HashMap 在 Java1.7 与 1.8 中的区别
hashMap 数据结构
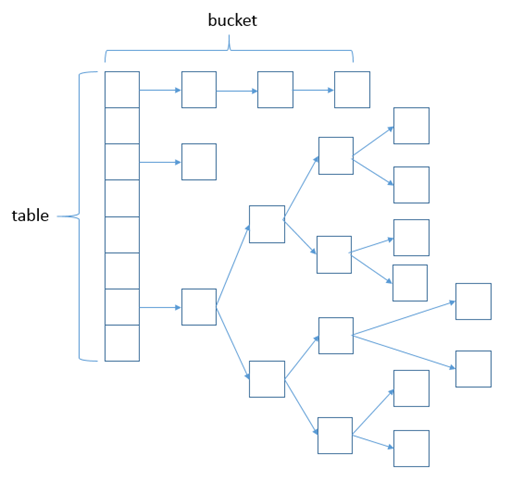
如上图所示,JDK7之前hashmap又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
JDK8中,当同一个hash值(Table上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。这就是JDK7与JDK8中HashMap实现的最大区别。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同,或者hashcode取模后的结果相同(hash collision),那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表。
在hashcode特别差的情况下,比方说所有key的hashcode都相同,这个链表可能会很长,那么put/get操作都可能需要遍历这个链表
也就是说时间复杂度在最差情况下会退化到O(n)
JDK1.8中
使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构
如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里。
如果同一个格子里的key不超过8个,使用链表结构存储。
如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树。
那么即使hashcode完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销
也就是说put/get的操作的时间复杂度最差只有O(log n)
听起来挺不错,但是真正想要利用JDK1.8的好处,有一个限制:
key的对象,必须正确的实现了Compare接口
如果没有实现Compare接口,或者实现得不正确(比方说所有Compare方法都返回0)
那JDK1.8的HashMap其实还是慢于JDK1.7的
简单的测试数据如下:
向HashMap中put/get 1w条hashcode相同的对象
JDK1.7: put 0.26s,get 0.55s
JDK1.8(未实现Compare接口):put 0.92s,get 2.1s
但是如果正确的实现了Compare接口,那么JDK1.8中的HashMap的性能有巨大提升,这次put/get 100W条hashcode相同的对象
JDK1.8(正确实现Compare接口,):put/get大概开销都在320ms左右
为什么要这么操作呢?
我认为应该是为了避免Hash Collision DoS攻击
Java中String的hashcode函数的强度很弱,有心人可以很容易的构造出大量hashcode相同的String对象。
如果向服务器一次提交数万个hashcode相同的字符串参数,那么可以很容易的卡死JDK1.7版本的服务器。
但是String正确的实现了Compare接口,因此在JDK1.8版本的服务器上,Hash Collision DoS不会造成不可承受的开销。
参考资料:
jdk1.7.0_80的HashMap源码
jdk1.8.0_66的HashMap源码
部分转载自:http://www.cnblogs.com/stevenczp/p/7028071.html
HashMap 在 Java1.7 与 1.8 中的区别的更多相关文章
- HashMap在Java1.7与1.8中的区别
基于JDK1.7.0_80与JDK1.8.0_66做的分析 JDK1.7中 使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同, ...
- java中 HashMap和Hashtable,list、set和map 的区别
摘自: http://blog.chinaunix.net/uid-7374279-id-2057584.html HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Ma ...
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- 【转】HashMap、TreeMap、Hashtable、HashSet和ConcurrentHashMap区别
转自:http://blog.csdn.net/paincupid/article/details/47746341 一.HashMap和TreeMap区别 1.HashMap是基于散列表实现的,时间 ...
- 集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别
一.HashMap 的原理 1.HashMap简介 简单来讲,HashMap底层是由数组+链表的形式实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表 ...
- js中== 和===中的区别
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- continue语句在for语句和while语句中的区别
while语句的形式: while( expression ) statement for语句的形式: for( expression1; expression2;expression3 ) // ...
- Objective-C声明在头文件和实现文件中的区别
Objective-C声明在头文件和实现文件中的区别 转自codecloud(有整理) 调试程序的时候,突然想到这个问题,百度一下发现有不少这方面的问答,粗略总结一下: 属性写在.h文件中和在.m文件 ...
- 在oracle中where 子句和having子句中的区别
在oracle中where 子句和having子句中的区别 1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用 ...
随机推荐
- 移动端UI
mui:http://dev.dcloud.net.cn/mui/ saltUI:https://salt-ui.github.io
- 洛谷P1456 Monkey King
https://www.luogu.org/problemnew/show/1456 #include<cstdio> #include<iostream> #include& ...
- yum安装_yum命令的相关操作
2017年1月11日, 星期三 yum安装的四种方式 一.默认:从国外下载 二.国内:从阿里获取 http://mirrors.aliyun.com 1. cd /etc/yum.repos.d 2 ...
- core EFCore 开始尝试
准备工作: 工程:core + console 引用包: Install-Package Microsoft.EntityFrameworkCore Install-Package Microsoft ...
- 【整理】HTML5游戏开发学习笔记(1)- 骰子游戏
<HTML5游戏开发>,该书出版于2011年,似乎有些老,可对于我这样没有开发过游戏的人来说,却比较有吸引力,选择自己感兴趣的方向来学习html5,css3,相信会事半功倍.不过值得注意的 ...
- 20145226夏艺华 《Java程序设计》第6周学习总结
教材学习内容总结 学习目标 理解流与IO 理解InputStream/OutPutStream的继承架构 理解Reader/Writer继承架构 会使用装饰类 会使用多线程进行并发程序设计 第十章 输 ...
- thinkphp 原数据更新
调用TP的save方法更新数据时,如果新数据与数据库中得数据一致, 那么执行M('table')->save(data)方法时,该方法会返回false.现在的需求是,哪怕用户要更新的数据与原数据 ...
- 阿里云mysql数据库设置让公网访问客户端访问
第一步 首先使用root登入你的mysql ./mysql -u root -p 你的密码 第二步 备注:也可以添加一个用户名为yuancheng,密码为123456,权限为%(表示任意ip都能连接) ...
- Linux下ssh的使用
更多内容推荐微信公众号,欢迎关注: 摘抄自:https://www.cnblogs.com/kevingrace/p/6110842.html 对于linux运维工作者而言,使用ssh远程远程服务器是 ...
- 【Loadrunner】LR参数化:利用mysql数据库里面的数据进行参数化
很多同学都在自学loadrunner去做压力测试,但是如果要利用LR做压力测试,或者是其他工具,其中有一个环节是我们避开不了的,比如说:参数化 今天华华就给大家简要的介绍下,如果你要做的参数化的数据来 ...