盘点linux系统中的12条性能调优命令。
| 导读 | 性能调优一直是运维工程师最重要的工作之一,如果您所在的生产环境中遇到了系统响应速度慢,硬盘IO吞吐量异常,数据处理速度低于预期值的情况,又或者如CPU、内存、硬盘、网络等系统资源长期处于耗尽的状态,那么这篇文章将着实的能帮助到你,如果没有也请先收藏起来。 |

命令:hdparm -t /dev/sda5
打印:Timing buffered disk reads: 254 MB in 3.01 seconds = 84.34 MB/sec
说明:能够指定具体的哪块硬盘进行查询的哦!
格式:iostat [ -c | -d ] [ -k ] [ -t ] [ -V ] [ -x [ device ] ] [ interval ]
描述:iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况,同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析,每1秒检测统计一次(共5次)。

blk_read/s 每秒读取的数据块数 blk_wrtn/s 每秒写入的数据块数 blk_read 表示读取的所有数据块数 blk_wrtn 表示写入的所有数据块数
名称:报告虚拟内存的统计信息
格式:vmstat [-n] [延时[次数]]

| R: | 运行和等待CPU时间片的进程数。长期大于CPU的个数,代表CPU不足 |
| B: | 等待资源的进程数,如果等待数量多,问题有可能处在I/O或者内存 |
| Swpd: | 切换到内存交换区的内存大小[以KB为单位] |
| free: | 当前空闲的物理内存数量[以KB为单位] |
| si: | 由磁盘调入内存 |
| so: | 由内存调入磁盘 |
| bi: | 从块设备读入数据的总量 |
| bo: | 写到块设备的数据总量 |
| bi+bo | 1000 如果超过1000,代表硬盘的读写速度有问题 |
| in: | 在某一时间间隔内观测到的每秒设备中断数[中断数太多对性能不好] |
| cs: | 列表示每秒产生的上下文切换次数 |
| us+sy > 80% | 代表CPU资源不足 |
| us: | 用户进程消耗的CPU时间百分比 |
| sy: | 内核进程消耗的CPU时间百分比 |
| id: | CPU处在空闲状态的时间百分比 |
| wa: | IO等待所占用的时间百分比 |
| runq-sz: | 内存中可以运行的进程数 |
| plist-sz: | 系统中活跃的任务个数 |
任务计划 /etc/cron.d/sysstat
日志目录 /var/log/sa
查看方法 Sar –q –f /var/log/sa/sa10
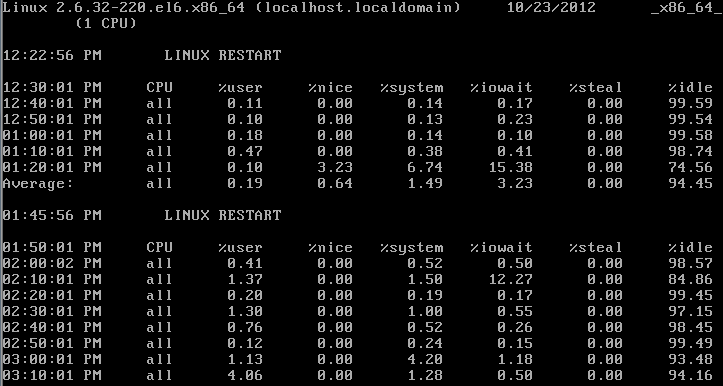
dmesg 显示出开机启动的信息
lscpu 显示CPU信息
lscpu -p 显示CPU对应的节点数
getconf LONG_BIT 获知主机的位数
getconf -a 查看全部的参数
/sys/class/dmi/id 可以查看Bios的信息 bios_*
strace –fc elinks –dump http://localhost
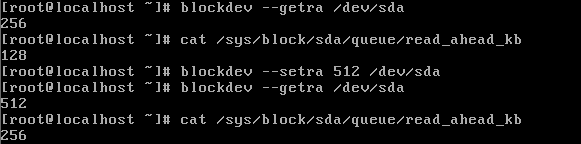
预先读取需要写入的量,然后再处理写请求,↑读到的值将会是设置值的一半↑。 设置读取到缓存中的数值越大.写入时就会因为数据量大而速度变慢。 /sys/block/sda/queue/nr_requests 队列长度越大,硬盘IO速度会提升,但占用内存 /sys/block/sda/queue/scheduler 调度算法Noop、anticipatory、deadline、[cfq]
1、创建200M的/dev/sdb1 格式化为ext3
2、dumpe2fs /dev/sdb1查看文件系统功能中包含的has_journal
3、Tune2fs –O ^has_journal /dev/sdb1 去掉默认原有的日志功能
4、再分一个200M的分区./dev/sdb2. 日志卷的block必须等于 /dev/sdb1
Mke2fs –O journal_dev –b 1024 /dev/sdb2
5、将/dev/sdb2作为/dev/sdb1的日志卷.
Tune2fs –j –J device=/dev/sdb2 /dev/sdb1
对于网站文件,频繁的修改atime是没有意义的,会影响性能
mount –o remount,noatime DEVICE 即可
默认是5秒提交一次日志,修改更长时间可以提高性能,但容易丢失数据。
mount –o remount,commit=15 DEVICE
chunk size.轮循一次写入的字节.默认是64K,只要没有写满,就不会移动到下一个设备 设置在每个硬盘都只写一个文件就切换到下一块硬盘,那么如果都是1K的小文件,就会将系统资源浪费在切换硬盘上 如果将chunk size的值设置很大,比如100M,那么也就没有了意义,还不如用一块硬盘。 Stripe size.条带大小,并不是有数据就写入,而是设置每次写入的数据量,一般是16K写一次。 所以.Chunk size(64K)/stripe size(16K),也就是说每块硬盘写四次。 ------------------------------------算当前应该把chunk size调成多少------------------------------------ 使用iostat –x查看自开机以来每秒的平均请求数avgrq-sz chunk size = 每秒请求数*512/1024/磁盘数,取一个最紧接2倍数的整数 stride = chunk size /block(默认是4k) 创建raid并设置chunk sinze mdadm –C /dev/md0 –l 0 –n3 –chunk=8 /dev/sdb[123] 修改raid mke2fs –j –b 4096 –E stride=2 /dev/md0
dumpe2fs /dev/sda1
tune2fs –m 10 /dev/sda1 保留block百分比
tune2fs –r 保留block数
保留的block过少,影响性能,保留的过多又浪费硬盘,默认是5%
学习了上面的性能调优命令和方法后,再总结几条调优的金句: 独立设备性能速度比集成的强,因为不占用主机整体资源 工程师一般不会远程管理计算机,需要提供日志等信息 硬盘空间越大,读取的速度越慢,可以考虑用多块硬盘组成一块较大空间 分区只是在硬盘上做标识,而不像格式化在做文件系统特性,所以速度快 硬盘越靠外侧速度越快[分区号越小越靠外区,所以将数据量大的首先分区]. 程序开发者注重雇主的功能要求,系统管理员注重程序的资源开销
免费提供最新Linux技术教程书籍,为开源技术爱好者努力做得更多更好:https://www.linuxprobe.com/
盘点linux系统中的12条性能调优命令。的更多相关文章
- 盘点linux操作系统中的10条性能调优命令,一文搞懂Linux系统调优
原文链接:猛戳这里 性能调优一直是运维工程师最重要的工作之一,如果您所在的生产环境中遇到了系统响应速度慢,硬盘IO吞吐量异常,数据处理速度低于预期值的情况,又或者如CPU.内存.硬盘.网络等系统资源长 ...
- Linux性能调优命令之free
功能说明 free 命令显示系统使用和空闲的内存情况,包括物理内存.交互区内存(swap)和内核缓冲区内存.共享内存将被忽略 语法 free [参数] 参数 -b : 以Byte为单位显示内存使用情况 ...
- Linux 系统TCP连接内存大小限制 调优
系统TCP连接内存大小限制 TCP的每一个连接请求,读写都需要占用系统内存资源,可根据系统配置,对TCP连接数,内存大小,限制调优. 查看系统内存资源 记录内存 详情:cat /proc/meminf ...
- 性能调优命令之jstack
jstack是java虚拟机自带的一种线程堆栈跟踪工具. /opt/java8/bin/jstack Usage: jstack [-l] <pid> (to connect to run ...
- find查找文件命令 - Linux系统中的常用技巧整理
“find”在Linux系统中是比较常用的文件查找命令,使用方法有很多,可以拥有查找文件.文件目录.文件更新时间.文件大小.文件权限及对比文件时间.下面是整理的“find”常用方法,方便以后需要的时候 ...
- linux概念之性能调优
目前,对系统进行性能调试的工具有很多,这些可以两大类:一类是标准的分析工具,即所有的UNIX都会带的分析工具: 另一类是不同厂商的UNIX所特有的性能分析工具,比如HP-UX就有自己的增值性能分析工具 ...
- Redis 宝典 | 基础、高级特性与性能调优
转载:Redis 宝典 | 基础.高级特性与性能调优 本文由 DevOpsDays 本文由简书作者kelgon供稿,高效运维社区致力于陪伴您的职业生涯,与您一起愉快的成长. 作者:kelgon ...
- JVM性能调优详解
前面我们学习了整个JVM系列,最终目标的不仅仅是了解JVM的基础知识,也是为了进行JVM性能调优做准备.这篇文章带领大家学习JVM性能调优的知识. 性能调优 性能调优包含多个层次,比如:架构调优.代码 ...
- [转帖]JVM性能调优详解
JVM性能调优详解 https://www.cnblogs.com/secbro/p/11833651.html 应该是 jdk8 以前的方法 貌似permsize 已经放弃这一块了. 前面我们学习了 ...
随机推荐
- CodeForces1082G Petya and Graph 最小割
网络流裸题 \(s\)向点连边\((s, i, a[i])\) 给每个边建一个点 边\((u, v, w)\)抽象成\((u, E, inf)\)和\((v, E, inf)\)以及边\((E, t, ...
- Git 初学者使用指南及Git 资源整理
Git 资源整理 Git is a free and open source distributed version control system designed to handle everyth ...
- wdcp(WDlinux Control Panel) 快速安装RPM包,lanmp一件安装
lanmp一键安装包是wdlinux官网2010年开始推出的lamp,lnmp,lnamp(apache,nginx,php,mysql,zend,eAccelerator,pureftpd)应用环境 ...
- JAVA基础(一) ——— static 关键字
1. 静态代码块 保证只创建一次,提升属性的级别为类变量.初始化后独自占用一块内存 2. 静态代码块执行触发条件 (1).当创建这个类的实例 (2).当调用这个类的静态变量 (3).当调用这个类的 ...
- 【洛谷】3469:[POI2008]BLO-Blockade【割点统计size】
P3469 [POI2008]BLO-Blockade 题意翻译 在Byteotia有n个城镇. 一些城镇之间由无向边连接. 在城镇外没有十字路口,尽管可能有桥,隧道或者高架公路(反正不考虑这些).每 ...
- 【BZOJ-3110】K大数查询 整体二分 + 线段树
3110: [Zjoi2013]K大数查询 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 6265 Solved: 2060[Submit][Sta ...
- django: ListView解读
[转载注明出处: http://www.cnblogs.com/yukityan/p/8039041.html ] django内置列表视图: # 导入 from django.views.gener ...
- bzoj 1798: [Ahoi2009]Seq 维护序列seq 线段树 区间乘法区间加法 区间求和
1798: [Ahoi2009]Seq 维护序列seq Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://www.lydsy.com/JudgeO ...
- Codeforces Round #243 (Div. 1)A. Sereja and Swaps 暴力
A. Sereja and Swaps time limit per test 1 second memory limit per test 256 megabytes input standard ...
- mongoDB系列之(三):mongoDB 分片
1. monogDB的分片(Sharding) 分片是mongoDB针对TB级别以上的数据量,采用的一种数据存储方式. mongoDB采用将集合进行拆分,然后将拆分的数据均摊到几个mongoDB实例上 ...