MySQL3:存储过程和函数
什么是存储过程
简单说,存储过程就是一条或多条SQL语句的集合,可视为批文件,但是起作用不仅限于批处理。本文主要讲解如何创建存储过程和存储函数以及变量的使用,如何调用、查看、修改、删除存储过程和存储函数等。使用的数据库和表还是之前写JDBC用的数据库和表:

create database school; use school; create table student
(
studentId int primary key auto_increment not null,
studentName varchar(10) not null,
studentAge int,
studentPhone varchar(15)
) insert into student values(null,'Betty', '20', '00000000');
insert into student values(null,'Jerry', '18', '11111111');
insert into student values(null,'Betty', '21', '22222222');
insert into student values(null,'Steve', '27', '33333333');
insert into student values(null,'James', '22', '44444444');
commit;
存储程序可以分为存储过程和函数,MySQL中创建存储过程和函数的语句分别 是:CREATE PROCEDURE和CREATE FUNCTION。使用CALL语句来调用存储过程,只能用输出变量返回值。函数可以从语句外调用(即通过引用函数名),也能返回标量值。存储过程也可以 调用其他存储过程。
创建存储过程
创建存储过程,需要使用CREATE PROCEDURE语句,语句基本格式如下:
CREATE PROCEDURE sp_name([proc_parameter])
[characteristics ...] routine_body
解释一下:
1、CREATE PROCEDURE为创建存储过程的关键字
2、sp_name为存储过程的名字
3、proc_parameter为指定存储过程的参数列表,列表形式为[IN|OUT|INOUT] param_name type。其中,IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出,param_name表示参数名称,type表示参数类型,该类型可以是MySQL数据库中的任意类型
4、characteristics指定存储过程的特性
5、routime_body是SQL代码的内容,可以用BEGIN...END来表示SQL代码的开始和结束
编写存储过程不是简单的事情,可能存储过程中需要复杂的SQL语句,并且要有创建存储过程的权限;但是使用存储过程将简化操作,减少冗余的操作步骤,同时还可以减少操作过程中的事物,提高效率,因此存储过程是非常有用的。下面看两个存储过程,一个查询student表中的所有字段,一个根据student表的Age字段算一个Age的平均值:
CREATE PROCEDURE proc ()
BEGIN
SELECT * FROM student;
END;
CREATE PROCEDURE AvgStudentAge()
BEGIN
SELECT AVG(studentAge) AS avgAge FROM student;
END;
上面都是不带参数的存储过程,下面看一个带参数的存储过程:
DELIMITER //
CREATE PROCEDURE CountStudent(IN sName VARCHAR(10), OUT num INT)
BEGIN
SELECT COUNT(*) INTO num FROM student WHERE studentName = sName;
END //
上述代码的作用是创建一个获取student表记录条数的存储过程,名称为CountStudent,根据传入的学生姓名COUNT(*)后把结果放入参数num中。
注意另外一个细节,上述代码第一行使用了"DELIMITER //",这句语句的作用是把MySQL的结束符设置为"//",因为MySQL默认的语句结束符号为分号";",为了避免与存储过程中SQL语句结束符相冲突,需要使用DELIMITER改变存储过程的结束符,并以"END //"结束存储过程。存过程定义完毕之后再使用"DELIMITER ;"恢复默认结束符。DELIMITER也可以指定其他符号作为结束符。
创建存储函数
创建存储函数需要使用CREATE FUNCATION语句,其基本语法如下:
CREATE FUNCTION func_name([func_parameter]) RETURNS type
[characteristic ...] routine_body
解释一下:
1、CREATE_FUNCTION为用来创建存储函数的关键字
2、func_name表示存储函数的名称
3、func_parameter为存储过程的参数列表,参数列表形式为[IN|OUT|INOUT] param_name type,和存储过程一样
4、RETURNS type表示函数返回数据的类型
5、characteristic表示存储函数的特性,和存储过程一样
举个例子:
CREATE FUNCTION NameByZip() RETURNS CHAR(50)
RETURN (select studentPhone from student where studentName = 'JAMES');
提两点:
1、如果在存储函数中的RETURN语句返回一个类型不同于函数的RETURNS自居指定的类型的值,返回值将被强制为恰当的类型
2、指定参数为IN、OUT或INOUT只对PROCEDURE是合法的(FUNCTION中总是默认为IN参数)。RETURNS子句只能对FUNCTION做指定,对于函数而言这是强制性的,它用来指定函数的返回类型,而且函数体必须包含一个RETURN value语句
变量的使用
变量可以在子程序中声明并使用,这些变量的作用范围是在BEGIN...END程序中,在存储过程中可以使用DECLARE语句定义变量,语法如下:
DECLARE var_name[,varame]... date_type [DEFAULT value]
解释一下:
1、var_name为局部变量的名称
2、DEFAULT value子句给变量提供一个默认值,值除了可以被声明为一个常数之外,还可以被指定为一个表达式。如果没有DEFAULT子句,那么初始值为NULL
定义变量后,为变量赋值可以改变变量的默认值,MySQL使用SET为变量赋值:
SET var_name=expr[, var_name=expr] ...;
举个例子:
DECLARE var1 INT DEFAULT 100;
DECLARE var2, var3, var4 INT;
SET var2 = 10, var3 = 20;
SET var4 = var2 + var3;
当然,我们使用SELECT语句也可以给变量赋值:
DECLARE t_studentName CHAR(20);
DECLARE t_studentAge INT;
SELECT studentName, studentId INTO t_studentName, t_studentAge FROM student where studentName = 'Bruce';DECLARE t_studentName CHAR(20);
DECLARE t_studentAge INT;
游标的使用
查询语句可能返回多条记录,如果数据量非常大,需要在存储过程和存储函数中使用游标来逐条读取查询结果集中的记录。应用程序可以根据需要滚动或浏览器中的程序。
游标必须在处理程序之前被声明,并且变量和条件还必须在声明游标或处理程序之前被声明。MySQL中声明游标的方法为:
DECLARE cursor_name CURSOR FOR select_statement
解释一下:
1、cursor_name表示游标的名称
2、select_statement表示SELECT语句返回的内容,返回一个用于创建游标的结果集
定义了游标,就要打开游标,打开游标的方法为:
OPEN cursor_name{游标名称}
再就是使用游标了,使用游标的方法为:
FETCH cursor_name INTO var_name [, var_name] ... {参数名称}
最后游标使用完了,要关闭:
CLOSE cursor_name{游标名称}
举个例子:
DECLARE t_studentName CHAR(20);
DECLARE t_studentAge INT;
DECLARE cur_student CURSOR FOR SELECT studentName, studentId FROM student where studentName = 'Bruce';
OPEN cur_student;
FETCH cur_student INTO t_studentName, t_studentAge;
...
CLOSE cur_student;
studentName为Bruce的在数据里面不止一条记录,创建游标之后就从student表中查出了studentName和studentId的值。OPEN这个游标,通过FETCH之后遍历每一组studentName和studentAge,并放入申明的变量t_studentName和t_studentAge中,之后想怎么用这两个字段怎么用这两个字段了。注意,游标用完关闭掉。
IF、CASE、LOOP、LEAVE、ITERATE、REPEAT
这六个比较简单,放在一起讲了,简单说下用法,除了第一个IF写个例子以外,别的就不写例子了,可以自己尝试下。
1、IF
IF语句包含多个判断条件,根据判断的结果为TRUE或FALSE执行相应的语句,其格式为:
IF expr_condition THEN statement_list
[ELSEIF expr_condition THEN statement_list]
[ELSE statement_list]
END IF
比如:
IF t_studentName IS NULL
THEN SELECT studentName INTO t_studentName FROM student where studentName = 'Bruce';
ELSE UPDATE studentName set student = NULL where studentName = 'Bruce';
END IF;
2、CASE
case是另外一个进行条件判断的语句,该语句有两种格式,第一种格式如下:
CASE case_expr
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE
其中,case_expr参数表示判断的表达式,决定了哪一个WHEN自居会被执行;when_value表示表达式可能的值,如果某个when_value表达式与case_expr表达式结果相同,则执行对应THEN关键字后的statement_list中的语句;statement_list参数表示不同when_value值的执行语句。
CASE语句的第二种格式为:
CASE
WHEN expr_condition THEN statement_list
[WHEN expr_condition THEN statement_list] ...
[ElSE statement_list]
END CASE
只是写法稍微变了一下,参数还是第一种写法的意思
3、LOOP
LOOP循环用来重复执行某些语句,与IF和CASE相比,LOOP只是创建一个循环操作的过程,并不进行条件判断。LOOP内的语句一直被重复执行直到循环被退出,跳出循环过程,使用LEAVE子句。LOOP语句j的基本格式如下:
[loop_label:] LOOP
statement_list
END LOOP
其中loop_label表示LOOP语句的标注名称,该参数可以省略;statement_list参数表示需要循环执行的语句
4、LEAVE
LEAVE语句用来退出任何被标注的流程控制构造,LEAVE语句的基本格式如下:
LEAVE label
5、ITERATE
ITERATE语句将执行顺序转到语句段开头出,语句基本格式如下:
ITERATE label
6、REPEAT
REPEAT语句用来创建一个带有条件判断的循环过程,每次与局执行完毕之后,会对条件表达式进行判断,如果表达式为真,则循环结束,否则重复执行循环中的语句。REPEAT语句的基本格式如下:
[repeat_label:] REPEAT
statement_list
UNTIL expr_condition
END REPEAT
其中,repeat_label为REPEAT语句的标注名称,该参数可以省略;REPEAT语句内的语句或语句群被重复,直至expr_condition为真
调用存储过程和函数
存储过程已经定义好了,接下来无非就是调用。存储过程和函数有很多种调用方法,存储过程必须使用CALL语句调用,并且存储过程和数据库相关,如果要执行其他数据库中的存储过程,需要指定数据库名称,例如CALL dbname.procname。存储函数的调用与MySQL中预定义的函数调用方式相同。
1、调用存储过程
存储过程是通过CALL语句进行调用的,语法如下:
CALL sp_name([parameter[,...]])
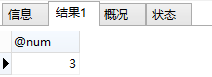
举个例子,就调用最前面那个CountStudent的存储过程:
CALL CountStudent('Bruce', @num);
select @num;
运行结果为:
2、调用存储函数
MySQL中调用存储函数的使用方法和MySQL内部函数的使用方法是一样的,无非存储函数是用户自己定义的,内部函数是MySQL开发者定义的。
我们调用一下上面定义的NameByZip那个函数:
select NameByZip();
运行结果为:
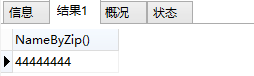
可以对照一下,studenName为"James"这一条,对应的studentPhone就是"44444444",符合SELECT出来的结果
查看、删除存储过程和函数
1、查看存储过程和函数的状态
SHOW STATUS可以查看存储过程核函数的状态,其基本语法结构如下:
SHOW {PROCEDURE | FUNCTIOn} STATUS [LIKE 'pattern'
这个语句是一个MySQL的扩展,他返回子程序的特征,如数据库、名字、类型、创建者及创建和修改日期。如果没有指定样式,根据使用的语句,所有存储过程或存储函数的信息都被列出。PROCEDURE和FUNCTIOn分别表示查看存储过程和函数,LIKE语句表示匹配存储过程或函数的名称。
举个例子:
SHOW PROCEDURE STATUS
运行结果为:

后面还有一些字段,截图截不全没办法。查看存储函数也一样,可以自己试试看。
2、查看存储过程和函数的定义
除了SHOW STATUS外,还可以使用SHOW CREATE来查看存储过程的定义,基本格式为:
SHOW CREATE {PROCEDURE | FUNCTION} sp_name
比如:
SHOW CREATE FUNCTION NameByZip
我查看了NameByZip这个函数的定义,结果为:

这个Create Function字段就是创建的存储函数的内容
3、删除存储过程和函数
删除存储过程核函数,可以使用DROP语句,基本语法如下:
DROP {PROCEDURE | FUNCTION} [IF EXISTS] sp_name
这个语句被用来移除一个存储过程或函数。sp_name为待移除的存储过程或函数的名称。
IF EXISTS子句是一个MySQL的扩展,如果程序或函数不存储,它可以防止错误发生,产生一个用SHOW WARNINGS查看的警告。举个例子:
DROP PROCEDURE CountStudent
DROP FUNCTION NameByZip;
这么简单就可以了。注意这里没有讲修改存储过程和存储函数,因为修改存储过程或者函数只能修改存储过程或者存储函数的特性,不能直接对已有的存储过程或函数进行修改,如果必须要改,只能先DROP在重新编写代码,CREATE一个新的。
MySQL3:存储过程和函数的更多相关文章
- MySQL主从环境下存储过程,函数,触发器,事件的复制情况
下面,主要是验证在MySQL主从复制环境下,存储过程,函数,触发器,事件的复制情况,这些确实会让人混淆. 首先,创建一张测试表 mysql),age int); Query OK, rows affe ...
- MySQL 系列(三)你不知道的 视图、触发器、存储过程、函数、事务、索引、语句
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 第三篇:MySQL 系列(三)你不知道的 视图.触发器.存储过程.函数 ...
- 我的MYSQL学习心得(十) 自定义存储过程和函数
我的MYSQL学习心得(十) 自定义存储过程和函数 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心 ...
- MySQL 存储过程和函数
概述 一提到存储过程可能就会引出另一个话题就是存储过程的优缺点,这里也不做讨论,一般别人问我我就这样回答你觉得它好你就用它.因为mysql中存储过程和函数的语法非常接近所以就放在一起,主要区别就是函数 ...
- Mysql存储过程和函数区别介绍
存储过程是用户定义的一系列sql语句的集合,涉及特定表或其它对象的任务,用户可以调用存储过程,而函数通常是数据库已定义的方法,它接收参数并返回某种类型的值并且不涉及特定用户表. 存储过程和函数存在以下 ...
- MySQL 第十天(视图、存储过程、函数、触发器)
MySql高级-视图.函数.存储过程.触发器 目录 一.视图 1 1.视图的定义 1 2.视图的作用 1 (1)可以简化查询. 1 (2)可以进行权限控制, 3 3.查询 ...
- MySQL4:存储过程和函数
什么是存储过程 简单说,存储过程就是一条或多条SQL语句的集合,可视为批文件,但是起作用不仅限于批处理.本文主要讲解如何创建存储过程和存储函数以及变量的使用,如何调用.查看.修改.删除存储过程和存储函 ...
- PKG_COLLECTION_LHR 存储过程或函数返回集合类型
存储过程或函数可以返回集合类型,方法很多,今天整理在一个包中,其它情况可照猫画虎. CREATE OR REPLACE PACKAGE PKG_COLLECTION_LHR AUTHID CURREN ...
- Oracle数据库中调用Java类开发存储过程、函数的方法
Oracle数据库中调用Java类开发存储过程.函数的方法 时间:2014年12月24日 浏览:5538次 oracle数据库的开发非常灵活,不仅支持最基本的SQL,而且还提供了独有的PL/SQL, ...
随机推荐
- day 81 天 ORM 操作复习总结
# ###############基于对象查询(子查询)############## 一.对多查询 正向查询 from django.shortcuts import render,HttpResp ...
- FFmpeg软硬解和多线程解码
一. AVCodecContext解码上下文 1.avcodec_register_all() : 注册所有的解码器 2.AVCodec *avcodec_find_decoder(enum AVCo ...
- CentOS 6 - 升级内核
有的时候,需要升级Linux内核,今天我就是在CentOS 6中升级内核,在没有升级内核之前,我的CentOS 6只有2.6.32这一个内核,也是默认启动的内核.下面就开始一步步操作升级内核了! 一, ...
- 一,php的错误处理和异常处理
php程序中如果语法或逻辑错误,会引起php默认错误处理机制,不会引起异常处理机制,只有在程序中throw抛出异常后,如果没有catch捕捉异常,默认调用php默认异常处理. php有默认错误机制和默 ...
- FunDA(6)- Reactive Streams:Play with Iteratees、Enumerator and Enumeratees
在上一节我们介绍了Iteratee.它的功能是消耗从一些数据源推送过来的数据元素,不同的数据消耗方式代表了不同功能的Iteratee.所谓的数据源就是我们这节要讨论的Enumerator.Enumer ...
- Java并发编程之volatile的应用
在多线程的并发编程中synchronized和volatile都扮演着重要的角色.volatile是轻量级的synchronized,它在多处理器的开发中保证了共享变量的可见性,可见性的意思是当一个线 ...
- python3模块: uuid
一. 简介 UUID是128位的全局唯一标识符,通常由32字节的字母串表示.它可以保证时间和空间的唯一性,也称为GUID. 全称为:UUID--Universally Unique IDentifie ...
- 适配 iOS 11 & iPhone X 大全
1.升级iOS11后造成的变化 1. 1升级后,发现某个拥有tableView的界面错乱,组间距和contentInset错乱,因为iOS11中UIViewController的automatical ...
- 【PaddlePaddle系列】CIFAR-10图像分类
前言 本文与前文对手写数字识别分类基本类似的,同样图像作为输入,类别作为输出.这里不同的是,不仅仅是使用简单的卷积神经网络加上全连接层的模型.卷积神经网络大火以来,发展出来许多经典的卷积神经网络模型, ...
- js获取url地址的参数的方法
js获取url参数值 今天说一下如何获取url参数值. 思路 通过location的search就可以获取到url中问号后面的值. 字符串过滤到问号 通过split方法分割参数集合 循环赋值 匹配对应 ...