详解HTTP缓存
HTTP缓存是个大公司面试几乎必考的问题,写篇随笔说一下HTTP缓存。
1. HTTP报文首部中有关缓存的字段
在HTTP报文中,与缓存相关的信息都存在首部里,简单说一下首部。
首部
HTTP首部字段向请求报文和相应报文中添加了一些附加信息。本质上来说,它们只是一些键值对的列表。比如,下面的首部行会向Content-Length首部字段赋值19:
Content-Length: 19
HTTP规范定义了几中首部字段。应用程序也可以随意发明自己所用的首部。HTTP首部可以分为以下几类:
通用首部
既可以出现在请求报文中,也可以出现在响应报文中。
请求首部
提供更多有关请求的信息。
响应首部
提供更多有关响应的信息。
实体首部
描述主体的长度和内容,或资源本身。
扩展首部
规范中没有定义的新首部。
想了解更多有关HTTP首部或报文的信息,个人推荐《HTTP权威指南》。
首部中与缓存有关的字段
通用首部字段

请求首部字段
响应首部字段

实体首部字段

2. 缓存的处理步骤
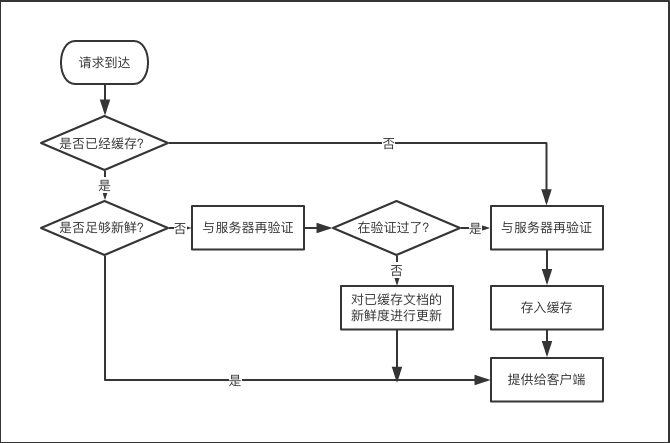
除了一些微小的细节,Web缓存的工作原理基本很简单,对一条HTTP GET报文的基本缓存处理过程包括7个步骤。
- 接收——缓存从网络中读取抵达的请求报文。
- 解析——缓存对报文解析,提取出URL和各种首部。
- 查询——缓存查看是否有本地副本可用,如果没有就向服务器获取一份副本,并将其保存在本地。
- 新鲜度检测——缓存查看以缓存的副本是否新鲜,如果不是,就询问服务器是否有更新。
- 创建响应——缓存会用新的首部和以缓存的主体来构建一条响应报文。
- 发送——缓存通过网路将响应发挥给客户端。
- 日志——缓存可选的创建一个日志文件来描述这个事务。
缓存的处理步骤如图:
3. 文档过期和服务器再验证
文档过期
通过特殊的HTTP Cache-Control首部和Expires首部,HTTP让原始服务器向每个文档加了一个过期时间,这些首部说明了多长时间内可将这些内容视为新鲜的。
在文档过期之前,缓存可以以任意频率使用这些副本,而无需与服务器进行联系,除非客户端请求中包含有阻止提供已缓存或未验证资源的首部。一旦已缓存的文档过期,缓存就必须与服务器进行核对,询问文档是否被修改过,如果被修改过,就要获取一份新鲜的并带有新的过期日期的副本。
服务器再验证
但是缓存文档过期并不意味着它与服务器上的文档有实际的区别,只是以为到了要进行核对的时间了。这种情况叫服务器再验证,说明缓存需要询问服务器文档是否发生了变化。
如果再验证显示内容发生了变化,缓存会获取一份新的文档副本,并将其存储在旧文档的位置上,然后将文档发送给客户端。
如果再验证显示内容没有发生变化,缓存只要获取新的首部,包括一个新的过期日期,并对缓存中的首部进行更新就好了。
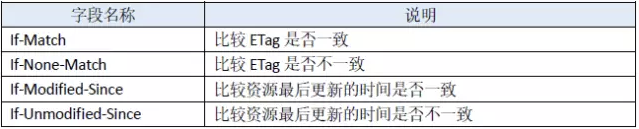
HTTP定义了几个首部用来实现缓存是否新鲜的验证,像开篇我们说到的If-Modified-Since和If-None-Match、Last-Modified等都属于这样的首部。
强缓存和协商缓存
我们根据是否需要向服务器发起请求将缓存分成两类,不需要向服务器发起请求的缓存叫强缓存,也就是上面所说的文档没过期时候用到的缓存。需要向服务器发起请求的缓存叫协商缓存,也就是上面服务器再验证用到的缓存。
下面我们详细介绍强缓存和协商缓存。
4. 强缓存
上面我们说可以通过Cache-Control首部和Expires首部来标明文档的过期时间。如果没有过期的话,自然就是从缓存里取文档了:

顾名思义,这里的memory cache内存了,disk cache就是磁盘的缓存了,再往下说就到了webkit的缓存机制了。
Expires
为什么要先说Expires呢?因为相比于Cache-Control,Expires出现的较早,是HTTP1.0的东西,而Cache-Control是HTTP1.1的东西。
Expires的值对应一个GMT,也就是格林尼治时间,比如“Mon, 22 Jan 2019 11:12:01 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
在客户端我们同样可以使用meta标签来知会IE(也仅有IE能识别)页面(同样也只对页面有效,对页面上的资源无效)缓存时间:
<meta http-equiv="expires" content="mon, 18 apr 2016 14:30:00 GMT">
如果希望在IE下页面不走缓存,希望每次刷新页面都能发新请求,那么可以把“content”里的值写为“-1”或“0”。但是是该方式仅仅作为知会IE缓存时间的标记,你并不能在请求或响应报文中找到Expires字段。
那么如果Pragma和Expires一起出现的话,Pragma的优先级是高的。
注意:响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,如果客户端上的时间跟服务器上的时间不一致,特别是如果你修改了自己电脑的系统时间,那缓存时间可能就没什么意义了。
Pragma
既然我们已经说了Expires是HTTP1.0的遗留物,那我们也要介绍下Pragma。
当该字段值为“no-cache”的时候,会通知客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。
Pragma属于通用首部字段,在客户端上使用时,常规要求我们往html上加上这段meta元标签:
<meta http-equiv="Pragma" content="no-cache">
它告诉浏览器每次请求页面时都不要读缓存,都得往服务器发一次请求才行。
但是这种禁用缓存的形式作用不是那么太大:
仅有IE才能识别这段meta标签含义,其它主流浏览器仅能识别“Cache-Control: no-store”的meta标签。
在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求,但是仅限页面,页面上的资源则不受影响。
所以这种在客户端定义Pragma并没有多少作用。
但是在响应报文中加上这个字段就不一样了,浏览器在收到服务器的Pragma字段后会对资源进行标记,禁用其缓存行为,进而后续每次刷新页面均能重新发出请求而不走缓存。
Cache-Control
针对上述的“Expires时间是相对服务器而言,无法保证和客户端时间统一”的问题,HTTP1.1新增了 Cache-Control 来定义缓存过期时间,若报文中同时出现了 Pragma、Expires 和 Cache-Control,会以 Cache-Control 为准。
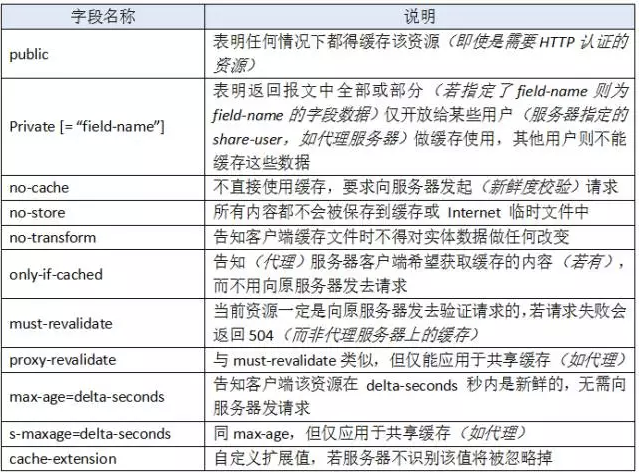
Cache-Control也是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。在RFC中规范了 Cache-Control 的格式为:
"Cache-Control" ":" cache-directive"
作为请求首部时,cache-directive的可选值有:
作为响应首部时,cache-directive的可选值有:
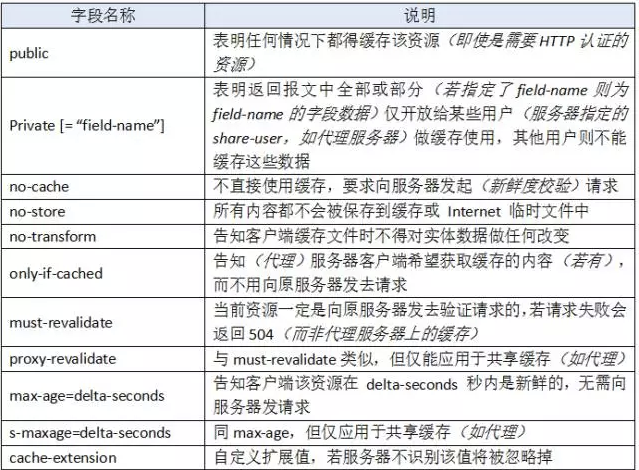
我们依旧可以在HTML页面加上meta标签来给请求报头加上 Cache-Control字段,并且可以有多个值:
Cache-Control: max-age=3600, must-revalidate
它意味着该资源是从原服务器上取得的,且其新鲜度的有效时间为一小时,在后续一小时内,用户重新访问该资源则无须发送请求。
当然这种组合的方式也会有些限制,比如 no-cache 就不能和 max-age、min-fresh、max-stale 一起搭配使用。
组合的形式还能做一些浏览器行为不一致的兼容处理。例如在IE我们可以使用 no-cache 来防止点击“后退”按钮时页面资源从缓存加载,但在 Firefox 中,需要使用 no-store 才能防止历史回退时浏览器不从缓存中去读取数据,故我们在响应报头加上如下组合值即可做兼容处理:
Cache-Control: no-cache, no-store
5. 协商缓存
顾名思义,客户端通过与服务器进行协商是否使用缓存。前面我们已经说过了HTTP提供了实现缓存文件是否新鲜的验证、提升缓存的复用率的几个首部,就来说说这些首部。其实它们都是HTTP1.1新增的。
Last-Modified
服务器将资源传递给客户端时,会将资源最后更改的时间以“Last-Modified: GMT”的形式加在实体首部上一起返回给客户端。
客户端会为资源标记上该信息,下次再次请求时,会把该信息附带在请求报文中一并带给服务器去做检查,若传递的时间值与服务器上该资源最终修改时间是一致的,则说明该资源没有被修改过,直接返回304状态码即可。
至于传递标记起来的最终修改时间的请求报文首部字段一共有两个:
⑴ If-Modified-Since: Last-Modified-value
示例:
If-Modified-Since: Thu, 31 Mar 2016 07:07:52 GMT
该请求首部告诉服务器如果客户端传来的最后修改时间与服务器上的一致,则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 Last-Modified 值。
⑵ If-Unmodified-Since: Last-Modified-value
告诉服务器,若Last-Modified没有匹配上,即资源在服务端的最后更新时间改变了,则应当返回412(Precondition Failed) 状态码给客户端。
当遇到下面情况时,If-Unmodified-Since 字段会被忽略:
Last-Modified值相等,即资源在服务端没有新的修改;
服务端需返回2XX和412之外的状态码;
传来的指定日期不合法
Last-Modified 说好却也不是特别好,因为如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端。
ETag
为了解决上述Last-Modified可能存在的不准确的问题,Http1.1还推出了 ETag 实体首部字段。
服务器会通过某种算法,给资源计算得出一个唯一标志符(比如md5标志),在把资源响应给客户端的时候,会在实体首部加上“ETag: 唯一标识符”一起返回给客户端。
客户端会保留该 ETag 字段,并在下一次请求时将其一并带过去给服务器。服务器只需要比较客户端传来的ETag跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
如果服务器发现ETag匹配不上,那么直接以常规GET 200回包形式将新的资源以及新的Etag发给客户端;如果ETag是一致的,则直接返回304知会客户端直接使用本地缓存即可。
那么客户端是如何把标记在资源上的 ETag 传去给服务器的呢?请求报文中有两个首部字段可以带上 ETag 值:
⑴ If-None-Match: ETag-value
示例为
If-None-Match: "56fcccc8-1699"
告诉服务端如果 ETag 没匹配上需要重发资源数据,否则直接回送304 和响应报头即可。
当前各浏览器均是使用的该请求首部来向服务器传递保存的 ETag 值。
⑵ If-Match: ETag-value
告诉服务器如果没有匹配到ETag,或者收到了“*”值而当前并没有该资源实体,则应当返回412(Precondition Failed) 状态码给客户端。否则服务器直接忽略该字段。
If-Match 的一个应用场景是,客户端走PUT方法向服务端请求上传/更替资源,这时候可以通过 If-Match 传递资源的ETag。
需要注意的是,如果资源是走分布式服务器(比如CDN)存储的情况,需要这些服务器上计算ETag唯一值的算法保持一致,才不会导致明明同一个文件,在服务器A和服务器B上生成的ETag却不一样。
如果 Last-Modified 和 ETag 同时被使用,则要求它们的验证都必须通过才会返回304,若其中某个验证没通过,则服务器会按常规返回资源实体及200状态码。
如果面试的时候能说出这些,就代表了你对HTTP缓存理解的很不错了,如果是一百分的话也应该可以拿到八十分了。
详解HTTP缓存的更多相关文章
- 详解浏览器缓存机制与Apache设置缓存
一.详解浏览器缓存机制 对于,如何说明缓存机制,在网络上找到了两张图,个人认为思路是比较清晰的.总结时,上图. 这里需要注意的有两点: 1.Last-Modified.Etag是响应头里的数据 2.I ...
- 浏览器 HTTP 协议缓存机制详解--网络缓存决策机制流程图
1.缓存的分类 2.浏览器缓存机制详解 2.1 HTML Meta标签控制缓存 2.2 HTTP头信息控制缓存 2.2.1 浏览器请求流程 2.2.2 几个重要概念解释 3.用户行为与缓存 4.Ref ...
- spring+springMVC+JPA配置详解(使用缓存框架ehcache)
SpringMVC是越来越火,自己也弄一个Spring+SpringMVC+JPA的简单框架. 1.搭建环境. 1)下载Spring3.1.2的发布包:Hibernate4.1.7的发布包(没有使用h ...
- 网卡驱动-BD详解(缓存描述符 Buffer Description)
DMA介绍(BD的引入) 网络设备的核心处理模块是一个被称作 DMA(Direct Memory Access)的控制器,DMA 模块能够协助处理器处理数据收发.对于数据发送来说,它能够将组织好的数据 ...
- 程序员笔记|详解Eureka 缓存机制
引言 Eureka是Netflix开源的.用于实现服务注册和发现的服务.Spring Cloud Eureka基于Eureka进行二次封装,增加了更人性化的UI,使用更为方便.但是由于Eureka本身 ...
- 详解Spring缓存注解@Cacheable,@CachePut , @CacheEvict使用
https://blog.csdn.net/u012240455/article/details/80844361 注释介绍 @Cacheable @Cacheable 的作用 主要针对方法配置,能够 ...
- 详解Eureka 缓存机制
原文:https://www.cnblogs.com/yixinjishu/p/10871243.html 引言 Eureka是Netflix开源的.用于实现服务注册和发现的服务.Spring Clo ...
- MyBatis(七):MyBatis缓存详解(一级缓存/二级缓存)
一级缓存 MyBatis一级缓存上SqlSession缓存,即在统一SqlSession中,在不执行增删改操作提交事务的前提下,对同一条数据进行多次查询时,第一次查询从数据库中查询,完成后会存入缓 ...
- 浏览器 HTTP 协议缓存机制详解
最近在准备优化日志请求时遇到了一些令人疑惑的问题,比如为什么响应头里出现了两个 cache control.为什么明明设置了 no cache 却还是发请求,为什么多次访问时有时请求里带了 etag, ...
随机推荐
- Spring整合MyBatis(五)MapperScannerConfigurer
摘要: 本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 目录 一.processPropertyPlaceHolders属性的 ...
- json2.js的作用与使用示例
工作中,如果公司要求你兼容ie6.7,那么你可以辞职了,开个玩笑: 关于json,本文不作介绍,介绍一下json字符串和对象的相互转换: 在各大主浏览器及ie8+,我们可以使用内置方法JSON.str ...
- layui水平导航条三级
需求 需要做一个顶部的水平导航条,有三级,展开的时候二级和三级一起展开,结果如图: 效果 一级菜单 二级标题 三级菜单 三级菜单 二级标题 三级菜单 三级菜单 一级菜单 二级标题 三级菜单 ...
- angular自定义过滤器在页面和控制器中的使用
首先设置自定义过滤器. 定义模块名:angular .module('myApp') .filter('filterName',function(){ return function(要过滤的对象,参 ...
- 2597: [Wc2007]剪刀石头布
2597: [Wc2007]剪刀石头布 链接 分析: 费用流. 首先转化一下问题,整张图最优的情况是存在$C_n^3$个,即任意3个都行,然后考虑去掉最少不满足的三元环. 如果u赢了v,u向v连一条边 ...
- javaweb 报表生成(pdf excel)所需要用到的技术和思路
pdf: “ 目前开源.成熟.稳定的第三方包只有iText.而用iText生成PDF有三种方式: 调用iText API,用代码“写”出PDF,依赖包:com.itextpdf:itextpdf:5. ...
- Java类的加载的一个小问题
前言 之前写了一篇文章专门介绍了一下类的加载和对象的创建流程,然后收到了一个博友的疑问,觉得蛮好的,在这里和大家分享下. 博文地址:[Java基础]Java类的加载和对象创建流程的分析 疑问 类在加载 ...
- Intellij IDEA《十分钟,配置struts2》by me
1.加载Struts 2类库 <dependencies> <!-- Struts 2 核心包--> <dependency> <groupId>org ...
- Open-Drain&Push-Pull
在配置GPIO(General Purpose Input Output)管脚的时候,常会见到两种模式:开漏(open-drain,漏极开路)和推挽(push-pull).对此两种模式,有何区别和联系 ...
- ATmega8仿真——LED 数码管的学习
1. I/O 口的结构及特点 Atmega8 有23 个I/O 引脚,分成3 个8 位的端口B.C 和D,其中C 口只有7 位 Atmega8 采用3个8位寄存器来控制I/O端口,它们分别是:方向寄存 ...