SQLSERVER的 筛选索引(Fiter Index)
fiter index(筛选索引)是SQL Server的一项功能,可使此数据库与众不同。
筛选索引的概念
SQL Server中常用的索引是一种物理结构,它包含来自所有行的一组选定列的值 在一张桌子里。大多数情况下,结构是一个b树,值存储在节点和叶子中,以便在树中查找(寻找)特定值非常快。它从根开始,然后通过节点决定每次选择哪个分支。尽管这是一个充满激情的话题,但我不会完全描述索引的结构。出于本文的目的,足以知道索引列中的每个值在b树中都有自己的位置。如果表很大,则索引列具有许多值,并且索引具有许多节点。向表中添加新行会使表更大,但索引也会增长。有一些或多或少的明显后果:
- 索引增长并消耗更多磁盘空间。
- 更大的索引更难以搜索 - 搜索和扫描速度更慢。
- 重建大型索引需要更多时间和资源。
索引是一个很好的发明。它使得寻找(寻找特定价值)成为可能。如果列已建立索引,则数据库不需要从表中读取所有行,以在索引列中查找具有特定值的行。然而,大指数是大问题。有时您知道该表有一些您不会查询的特定行。如果我可以索引不是所有行而只是索引它们的一部分怎么办?这正是筛选索引。
没有索引的示例
我有一个表,其中包含用户发送给其他用户的消息。当接收器读取消息时,通过将mes_unread字段从1 切换为0将其标记为已读。
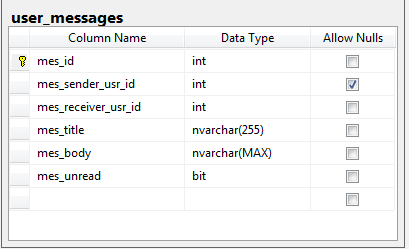
表中有100万行。当用户登录他/她的帐户时,将显示未读消息。这种情况的直接影响是非常频繁的查询是以下一种:
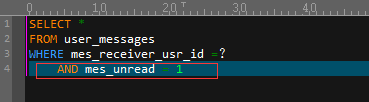
目前,此表上只有一个索引 - mes_id上的聚簇索引。因此,毫不奇怪,样本运行的执行计划显示聚集索引扫描正在读取所有数据,以查找与条件匹配的行。
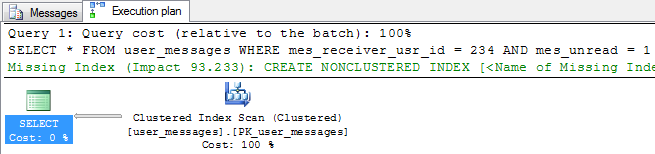
估计的查询成本为10.6818。最常用的查询从表中读取所有行并不好。
使用sp_spaceused过程检查表的大小。
EXEC sp_spaceused'user_messages ' ;

它显示表数据消耗了大约103 MB的存储空间和聚集索引 - 392 KB。
传统方法
回到聚集索引扫描问题,有一个简单的解决方案 - 创建一个索引。例如,数据库引擎建议的那个在执行计划中显示绿色字体
CREATE NONCLUSTERED INDEX IX_mes_receiver_usr_id_unread
ON user_messages(mes_receiver_usr_id,mes_unread); 创建索引后,相同的查询执行效率更高。执行计划显示使用索引和键查找搜索操作替换扫描操作。
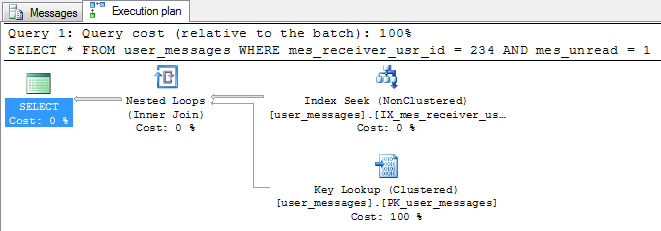
查询的成本估计为1.20738。它比没有索引的要少9倍。
sp_spaceused报告用于存储索引的额外15 MB。

15 MB并不多,但表只需103 MB。如果表是10 GB,我可以预期索引是1.5 GB,这是显而易见的。那还有什么方法可以减少这个索引的数据量吗?
过滤索引的方法
假如应用用户非常活跃,他们通常在收到消息后立即阅读消息,因此大部分消息已被阅读(95%)。只有5%的消息尚未打开。这意味着该条件 AND mes_unread = 1 将返回的行数减少了20倍(至5%)。更进一步,我不需要索引的那部分包含有关mes_unread = 0的行的信息。幸运的是,SQL Server包含过滤的索引功能,它允许我减少用于构建索引的行数。
此时,我将用过滤索引替换当前索引。
DROP INDEX IX_mes_receiver_usr_id_unread ON user_messages;
CREATE NONCLUSTERED INDEX IX_mes_receiver_usr_id_unread
ON user_messages(mes_receiver_usr_id,mes_unread)
WHERE mes_unread = 1; 过滤的索引可以通过定义中的WHERE子句轻松识别。上面使用的构造在两列上创建索引:mes_receiver_usr_id和mes_unread,
但仅适用于mes_unread = 1的那些行。不包括与其不匹配的其他行。它们根本不占用索引中的磁盘空间。
在开始使用过滤索引之前,我将检查执行计划。
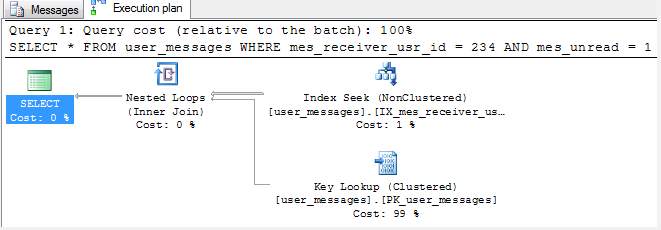
它看起来与普通索引的执行计划非常相似。那有什么区别?
不同的是执行成本。它下降到0.246134 ,几乎是传统指数的五倍。
为什么?答案是索引大小,可以使用sp_spaceused检查。
EXEC sp_spaceused'user_messages ' ;

与传统索引的15 MB相比,过滤索引的1.1 MB明显更少。它直接回答了较小的执行成本 - 更小的索引,更少的IO,更快的搜索。
总结下使用情况:
| 案件 | 执行成本 | 索引大小 |
| 没有索引 | 10.6818 | - |
| 普通索引 | 1.2073 | 15.3 MB |
| 过滤索引 | 0.2461 | 1.1 MB |
它可能是一个优势:更小的存储使用,更快的搜索,
但也有一个缺点 - 更改WHERE子句中的值可能会使索引无用。例如,如果我想查询已经读过的消息,那么这个索引对我没用:
SELECT *
FROM user_messages
WHERE mes_receiver_usr_id = 234
AND mes_unread = 0;
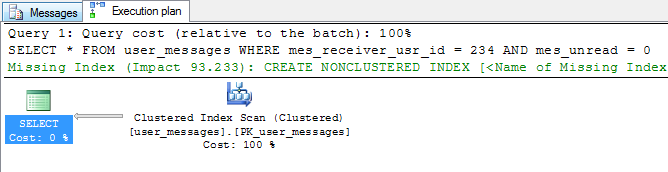
如您所见,将条件从mes_unread = 1更改为mes_unread = 0会导致从搜索切换到扫描。此时原因应该是显而易见的 -
过滤后的索引没有关于mes_unread = 0的行的任何信息,因此无法使用。
结论
过滤的索引具有强大的功能。如果您拥有几乎从不查询大多数行的表,它们可以提供很多帮助。它们不仅消耗更少的存储空间,而且由于它们更小,它们也更快。另一方面,我很少使用过滤索引。当想知道为什么时,我得出的结论是,如果绝大多数行都没有被查询为什么要保留它们?
SQLSERVER的 筛选索引(Fiter Index)的更多相关文章
- sqlserver 筛选索引(filter index)在使用时需要注意的事项
sqlserver 的筛选索引(filter index)与常规的非筛选索引,加了一定的filter条件,可以按照某些条件对表中的字段进行索引,但是filter 索引在查询 使用上,并不等同于常规的索 ...
- SQLServer性能调优3之索引(Index)的维护
前言 前一篇的文章介绍了通过建立索引来提高数据库的查询性能,这其实只是个开始.后续如果缺少适当的维护,你先前建立的索引甚至会成为拖累,成为数据库性能的下降的帮凶. 查找碎片 消除碎片可能是索引维护最常 ...
- sqlserver聚合索引(clustered index) / 非聚合索引(nonclustered index)的理解
1. 什么是聚合索引(clustered index) / 什么是非聚合索引(nonclustered index)? 可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索 ...
- SQLSERVER如何查看索引缺失
SQLSERVER如何查看索引缺失 当大家发现数据库查询性能很慢的时候,大家都会想到加索引来优化数据库查询性能, 但是面对一个复杂的SQL语句,找到一个优化的索引组合对人脑来讲,真的不是一件很简单的事 ...
- SQLServer → 09:索引
一.索引概念 用途 我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 概念 索引是一个单独的,存储在磁盘上的数据结构,它们包含则对数据表里 ...
- Sql Server 索引之唯一索引和筛选索引
唯一索引(UNIQUE INDEX) 当主键创建时如果不设置为聚集索引,那么就一定是唯一的非聚集索引.实际上,唯一索引,故名思议就是它要求该列上的值是唯一的.唯一索引能够保证索引键中不包含重复的值, ...
- SQL Server 创建索引(index)
索引的简介: 索引分为聚集索引和非聚集索引,数据库中的索引类似于一本书的目录,在一本书中通过目录可以快速找到你想要的信息,而不需要读完全书. 索引主要目的是提高了SQL Server系统的性能,加快数 ...
- SQL Server 性能调优2 之索引(Index)的建立
前言 索引是关系数据库中最重要的对象之中的一个,他能显著降低磁盘I/O及逻辑读取的消耗,并以此来提升 SELECT 语句的查找性能.但它是一把双刃剑.使用不当反而会影响性能:他须要额外的空间来存放这些 ...
- MySQL索引的Index method中btree和hash的优缺点
MySQL索引的Index method中btree和hash的区别 在MySQL中,大多数索引(如 PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)都是在BTREE中存储,但使用 ...
随机推荐
- Android 开发工具类 31_WebService 获取手机号码归属地
AndroidInteractWithWebService.xml <?xml version="1.0" encoding="utf-8"?> & ...
- Django 模板中 变量 过滤器 标签 的使用方法
一.变量 1.变量的形式是:{{variable}}, 当模板引擎碰到变量的时候,引擎使用变量的值代替变量. 2.使用dot(.)能够访问变量的属性 3.当模板引擎碰到dot的 ...
- j2ee高级开发技术课程第二周(web请求的整个过程、XML)
博客非原创,只是收集整理了一下网上的一些文章 一.web请求的整个过程 1)把URL分割成几个部分:协议.网络地址.资源路径.其中网络地址指示该连接网络上哪一台计算机,可以是域名或者IP地址,可以包括 ...
- Maven 映像
国内连接maven官方的仓库更新依赖库,网速一般很慢,收集一些国内快速的maven仓库镜像以备用. ====================国内OSChina提供的镜像,非常不错=========== ...
- 【持续更新】一个简洁、易用的美赛LaTeX模板: easyMCM
目录 1 当前美赛模板通行情况的概述 2 easymcm宏包说明 2.1 与mcmthesis的关系之说明 2.2 easymcm宏包的简介 2.3 美赛模板下载地址 3 常见问题的解决方案 若您无意 ...
- C#动态创建Gridview及批量插入到数据库
这里介绍两种动态创建Gridview的方法: (一).有时需要应付上头领导的检查,所以就弄一些静态的Gridview来显示数据,这种方法的优点就是不用连接数据库,比较方便,但是代码灵活性不高,所有数据 ...
- nginx+tomcat实现Windows系统下的负载均衡搭建的案例
刚入行没多久就听过‘负载均衡’的大名,到现在因为工作接触的少,所以没什么太多的认识.但自己又对其非常的好奇,所以前两天通过查资料,在自己的笔记本上就搭建了一个超简单的案例(工作中没有时间,晚上到家了条 ...
- 悟空模式-java-工厂方法模式
[却说那七衣仙女自受了大圣的定身法术,一周天方能解脱,各提花篮,回奏王母说道:“齐天大圣使术法困住我等,故此来迟.”王母问道:“汝等摘了多少蟠桃?”仙女道:“只有两篮小桃,三篮中桃.至后面,大桃半个也 ...
- Code Signal_练习题_isLucky
Ticket numbers usually consist of an even number of digits. A ticket number is considered lucky if t ...
- Yii 时间戳格式化显示的问题
这个控件是CJuiDatePicker控件的扩展,支持时分秒. 下载地址:http://www.yiiframework.com/extension/timepicker/ 这个控件用在view里的_ ...