用matplotlib对数据可视化
下图是要用到的数据集,反映了从1984到2016年的失业率的变化
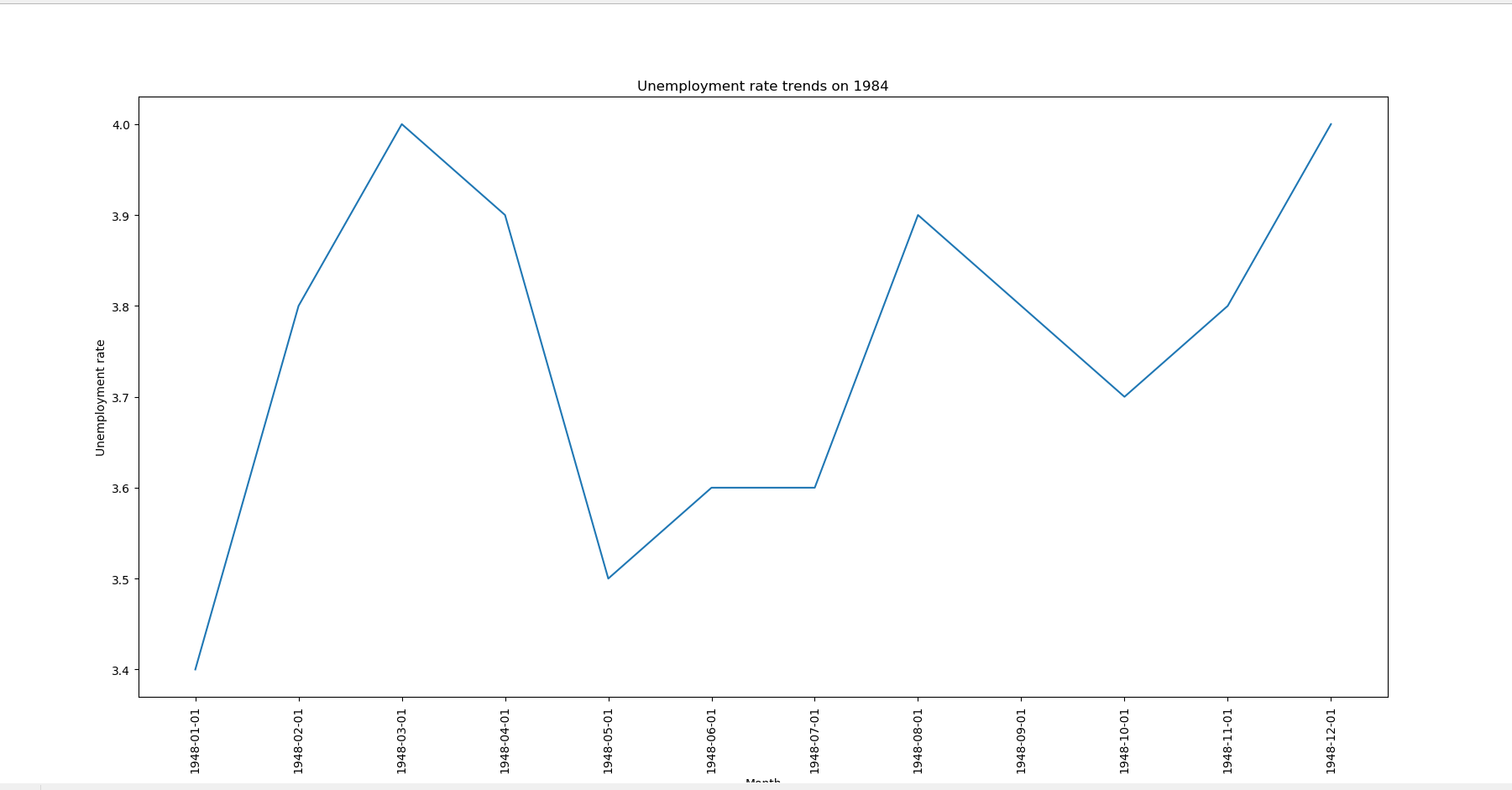
1.导入可视化模块import matlibplot.pyplot as plt, 函数plt.plot(x, y)确定折线图的点,x是由这些点的x坐标组成的列表,y是由这些点的y坐标组成
的列表。plt.show()显示图像,plt.xlabel()给x轴命名,plt.xticks()可以设置x坐标刻度点旋转指定角度,plt.title()给折线图命名
下面的代码是以上函数的应用
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- #画出1984年失业率折线图
- unrated = pd.read_csv("C:/学习/python/hello/UNRATE.csv")
- first_twelve = unrated.head()
- x_series = first_twelve["DATE"]
- y_series = first_twelve["VALUE"]
- plt.xticks(rotation=)
- plt.xlabel("Month")
- plt.ylabel("Unemployment rate")
- plt.title("Unemployment rate trends on 1984")
- plt.plot(x_series, y_series)
- plt.show()
运行结果如下
2.通过plt.subplot(n, m, x)在一个figure中添加多个子图, n和m表示子图的布局,分别代表行数和列数,x表示从左往右,从上往下数的第x个子图
下面的代码提供了该函数使用实例
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- plt.figure(figsize=(, ))
- ax1 = plt.subplot(, , )
- ax2 = plt.subplot(, , )
- ax3 = plt.subplot(, , )
- ax5 = plt.subplot(, , )
- plt.show()
运行结果如下
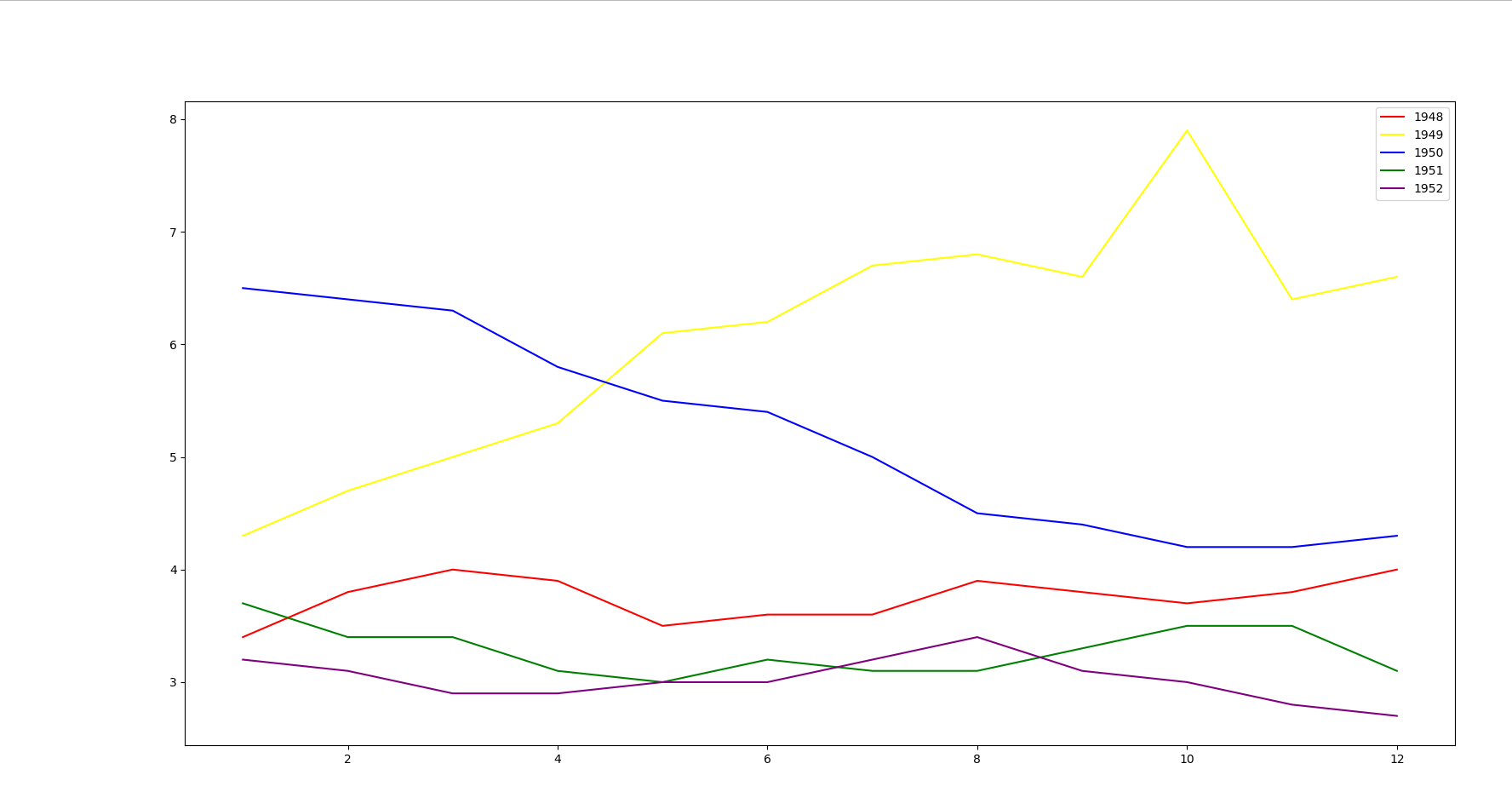
3.下面的代码是在一个坐标轴中画多个折线图的示例
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- unrated = pd.read_csv("C:/学习/python/hello/UNRATE.csv")
- unrated["DATE"] = pd.to_datetime(unrated["DATE"])
- color = ["red", "yellow", "blue", "green", "purple"]
- plt.figure(figsize=(, ))
- for i in range():
- sub_unrated = unrated.loc[i*:(i+)*-]
- sub_unrated_x = sub_unrated['DATE'].dt.month
- sub_unrated_y = sub_unrated["VALUE"]
- label = +i
- plt.plot(sub_unrated_x, sub_unrated_y, color=color[i], label=label)
- plt.legend(loc="best")
- plt.show()
运行结果如下
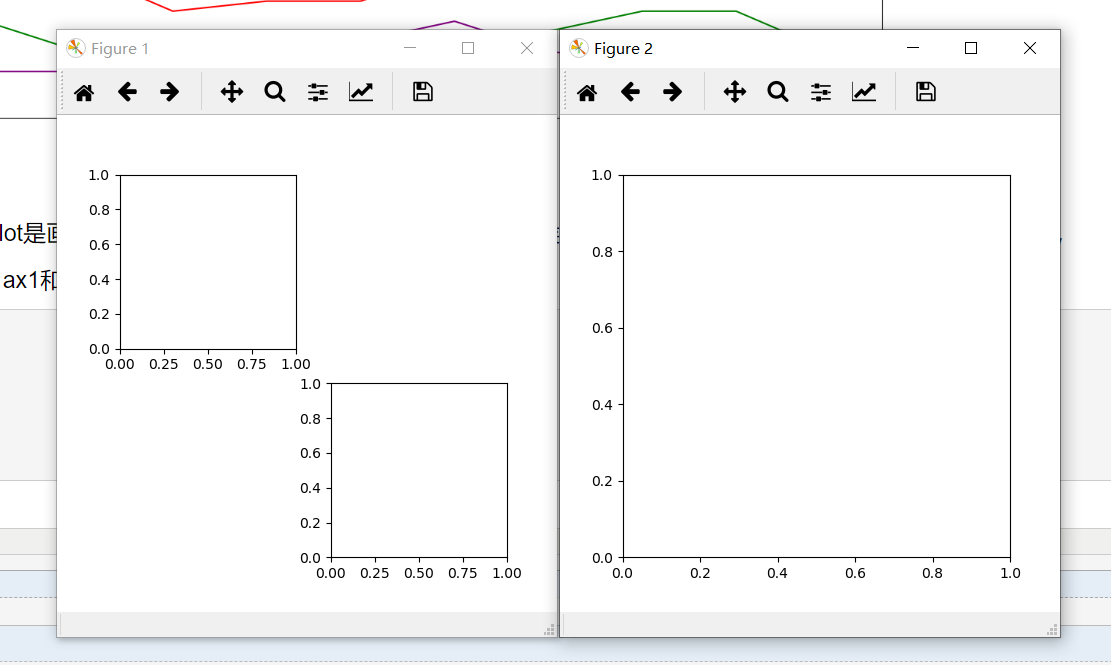
4.figure和subplot的定义顺序决定了subplot是画在哪个figure中。当代码中定义了多个figure时候,紧接着该figure定义的subplot才画在该figure中,
如下代码所示,定义了figure1和figure2,ax1和ax2在figure1中,ax在figure2中。
- plt.figure(figsize=(, ))
- ax1 = plt.subplot(,,)
- plt.figure(figsize=(, ))
- ax = plt.subplot(, , )
- plt.show()
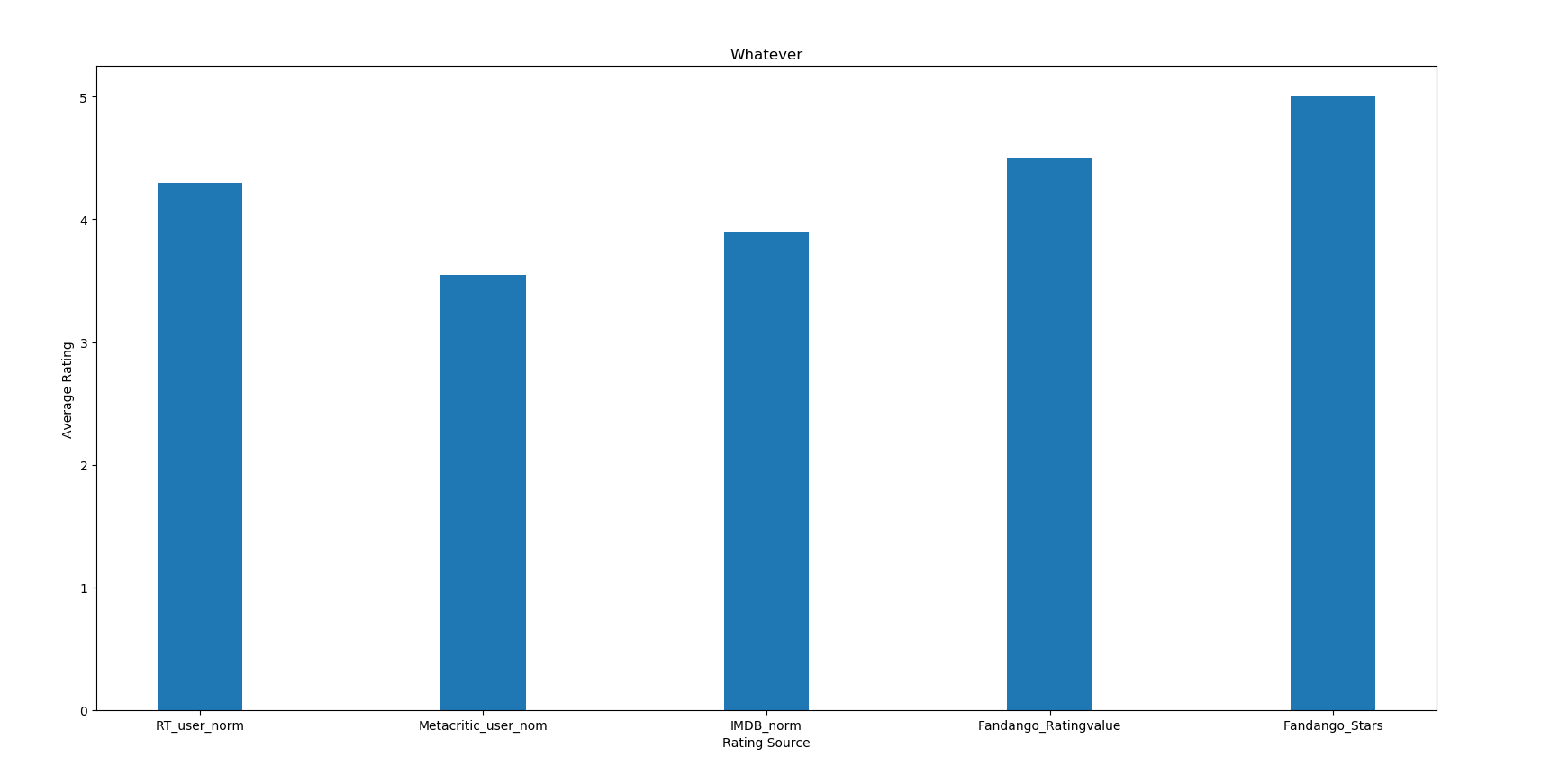
5.用matplotlib画条形图
- import pandas as pd
import numpy as np
import matplotlib.pyplot as plt- reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
cols = ["FILM", "RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"]
norm_reviews = reviews[cols]- num_cols = ["RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"]
bar_height = norm_reviews.loc[0, num_cols].values #第一部电影的评价,注意利用loc索引某一行的用法,可以添加第二维- bar_position = 1 + np.arange(5) #arange返回的是ndarray类型,range返回的是list类,使用arange需要用numpy
plt.figure(figsize=(10, 10))
ax = plt.subplot(1, 1, 1)
ax.bar(bar_position, bar_height, 0.3) #bar_position是条形图的x坐标(中点坐标),bar_height是高,0.3是宽
#设置x坐标刻度
tick_positions = range(1, 6)
ax.set_xticks(tick_positions)
ax.set_xticklabels(num_cols)- #设置x轴和y轴名称
ax.set_xlabel("Rating Source")
ax.set_ylabel("Average Rating")
ax.set_title("Whatever")
plt.show()
运行结果如下
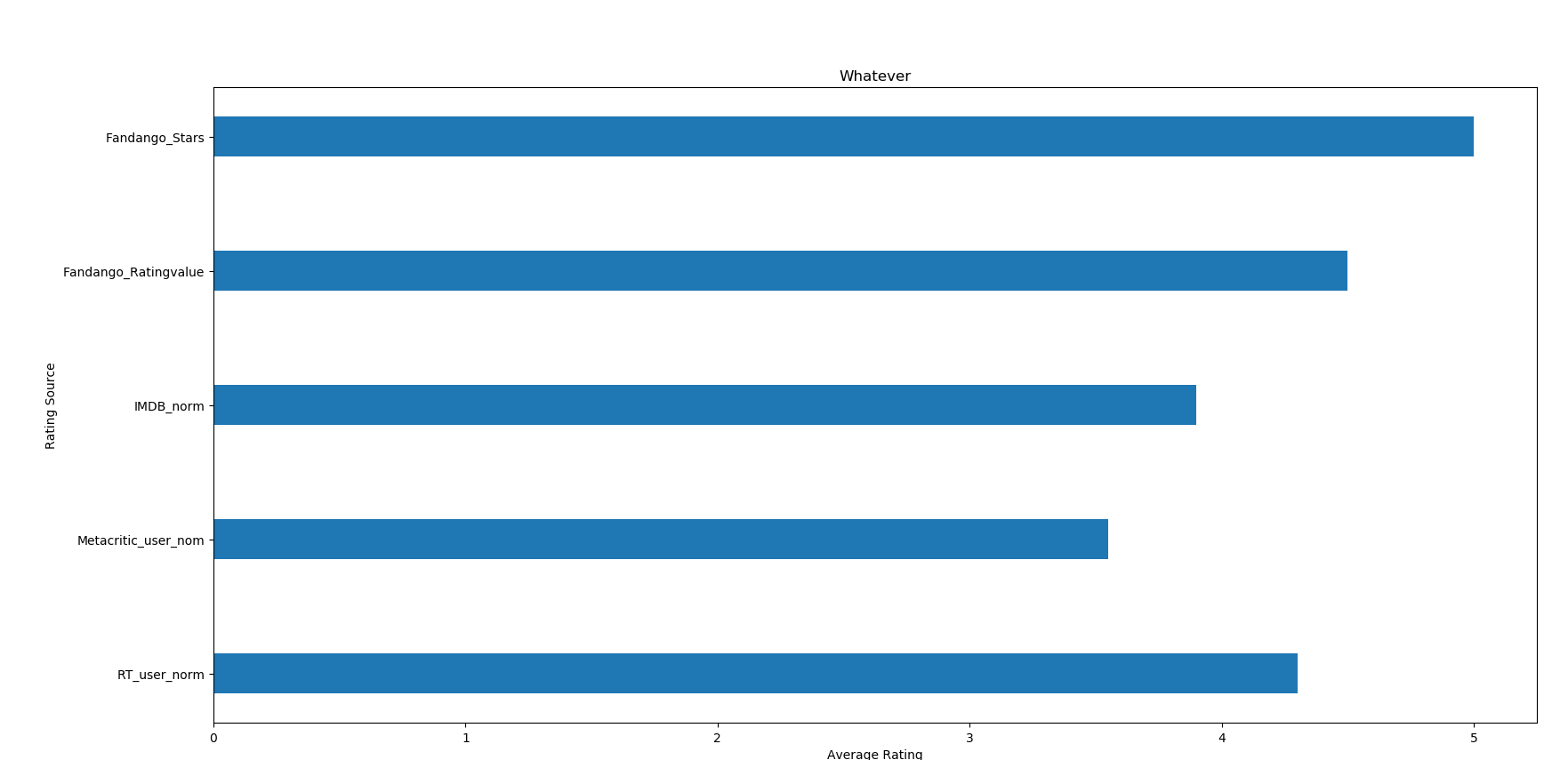
将上面的代码改变几处,就会成为横着的条形图了。代码如下所示(改动之处用白底红字加粗下划线标出来了)
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
- cols = ["FILM", "RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"]
- norm_reviews = reviews[cols]
- num_cols = ["RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"]
- bar_height = norm_reviews.loc[, num_cols].values #第一部电影的评价,注意利用loc索引某一行的用法,可以添加第二维
- bar_position = + np.arange() #arange返回的是ndarray类型,range返回的是list类,使用arange需要用numpy
- plt.figure(figsize=(, ))
- ax = plt.subplot(, , )
- ax.barh(bar_position, bar_height, 0.3) #bar_position是条形图的x坐标(中点坐标),bar_height是高,.3是宽
- #设置x坐标刻度
- tick_positions = range(, )
- ax.set_yticks(tick_positions)
- ax.set_yticklabels(num_cols)
- #设置x轴和y轴名称
- ax.set_ylabel("Rating Source")
- ax.set_xlabel("Average Rating")
- ax.set_title("Whatever")
- plt.show()
运行结果如下
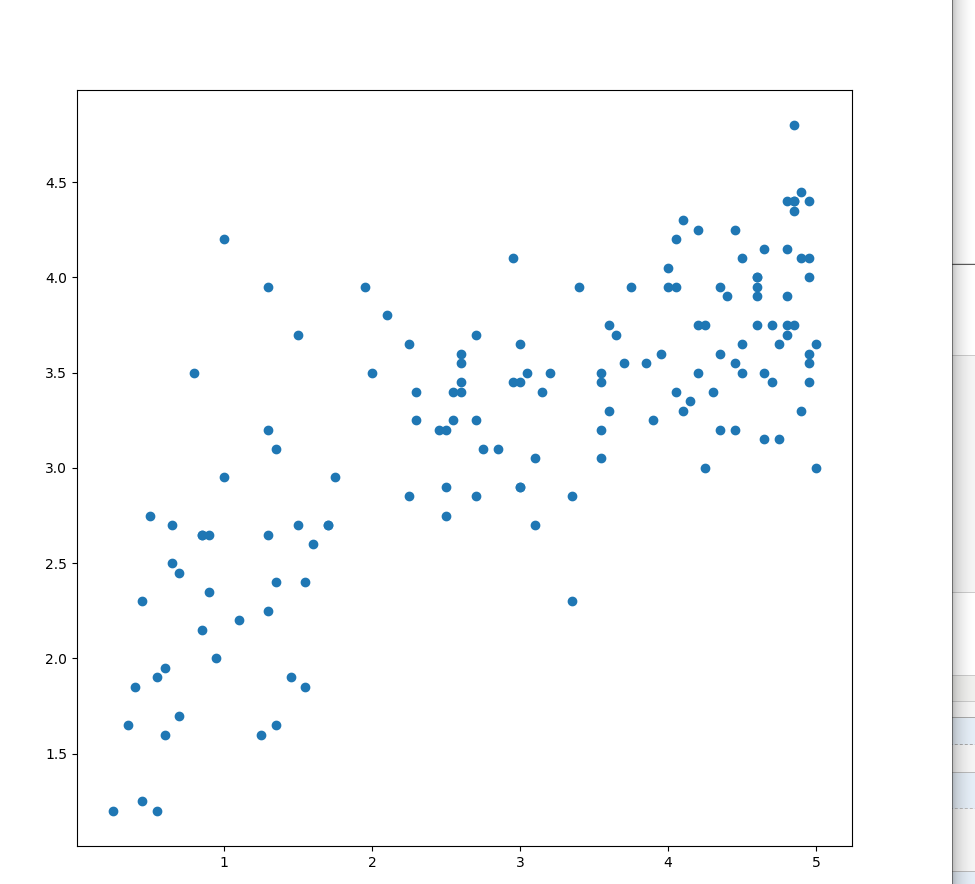
6.画散点图
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
- plt.figure(figsize=(,))
- ax = plt.subplot(, , )
- ax.scatter(reviews["RT_norm"], reviews["Metacritic_user_nom"])
- plt.show()
运行结果如下
7.设a是Series类型,b = a.value_counts()可以得到a的一个频数统计,b是Series结构,b的index是a的值,b的value是该值出现的频数。
如下代码所示
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
- cols = ["FILM", "RT_user_norm", "Metacritic_user_nom", "Fandango_Ratingvalue"]
- norm_reviews = reviews[cols]
- #fandango_distribution是Series结构,index是原来的列的值,value是该值出现的频率
- fandango_distribution = norm_reviews["Fandango_Ratingvalue"].value_counts()
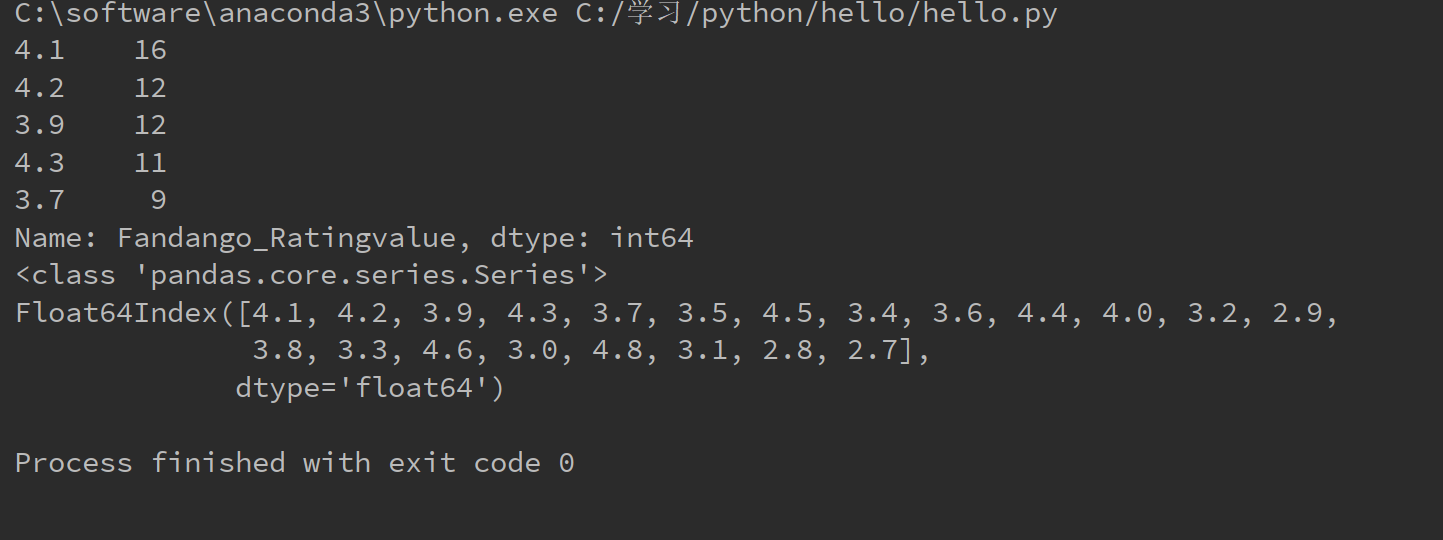
- print(fandango_distribution.head())
- print(type(fandango_distribution))
- print(fandango_distribution.index)
运行结果如下
8.我们来画直方图
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
- cols = ["FILM", "RT_user_norm", "Metacritic_user_nom","IMDB_norm", "Fandango_Ratingvalue"]
- norm_reviews = reviews[cols]
- plt.figure(figsize=(, ))
- ax = plt.subplot(, , )
- ax.hist(norm_reviews["RT_user_norm"], bins=) #参数bins表示直方图的x轴分成多少区间
- plt.show()
运行结果如下
用matplotlib对数据可视化的更多相关文章
- matplotlib实现数据可视化
一篇matplotlib库的学习博文.matplotlib对于数据可视化非常重要,它完全封装了MatLab的所有API,在python的环境下和Python的语法一起使用更是相得益彰. 一.库的安装和 ...
- 基于matplotlib的数据可视化 - 笔记
1 基本绘图 在plot()函数中只有x,y两个量时. import numpy as np import matplotlib.pyplot as plt # 生成曲线上各个点的x,y坐标,然后用一 ...
- 【Matplotlib】数据可视化实例分析
数据可视化实例分析 作者:白宁超 2017年7月19日09:09:07 摘要:数据可视化主要旨在借助于图形化手段,清晰有效地传达与沟通信息.但是,这并不就意味着数据可视化就一定因为要实现其功能用途而令 ...
- 使用 jupyter-notebook + python + matplotlib 进行数据可视化
上次用 python 脚本中定期查询数据库,监视订单变化,将时间与处理完成订单的数量进行输入写入日志,虽然省掉了人为定时查看数据库并记录的操作,但是数据不进行分析只是数据,要让数据活起来! 为了方便看 ...
- 基于matplotlib的数据可视化 - 等高线 contour 与 contourf
contour 与contourf 是绘制等高线的利器. contour - 绘制等高线 contourf - 填充等高线 两个的返回值值是一样的(return values are the sam ...
- 『Matplotlib』数据可视化专项
一.相关知识 官网介绍 matplotlib API 相关博客 matplotlib绘图基础 漂亮插图demo 使用seaborn绘制漂亮的热度图 fig, ax = plt.subplots(2,2 ...
- 基于matplotlib的数据可视化 - 饼状图pie
绘制饼状图的基本语法 创建数组 x 的饼图,每个楔形的面积由 x / sum(x) 决定: 若 sum(x) < 1,则 x 数组不会被标准化,x 值即为楔形区域面积占比.注意,该种情况会出现 ...
- 基于matplotlib的数据可视化 - 热图imshow
热图: Display an image on the axes. 可以用来比较两个矩阵的相似程度 mp.imshow(z, cmap=颜色映射,origin=垂直轴向) imshow( X, cma ...
- 基于matplotlib的数据可视化 -
matplotlib.pyplot(as mp or as plt)提供基于python语言的绘图函数 引用方式: import matplotlib.pyplot as mp / as plt 本章 ...
- Python学习笔记:Matplotlib(数据可视化)
Matplotlib是一个可以将数据绘制为图形表示的Python三方库,包括线性图(折线图,函数图).柱形图.饼图等基础而直观的图形,在平常的开发当中需要绘图时就非常有用了. 安装:pip insta ...
随机推荐
- hdu 3549 网络流最大流 Ford-Fulkerson
Ford-Fulkerson方法依赖于三种重要思想,这三个思想就是:残留网络,增广路径和割. Ford-Fulkerson方法是一种迭代的方法.开始时,对所有的u,v∈V有f(u,v)=0,即初始状态 ...
- 找不到javax.
https://blog.csdn.net/q343509740/article/details/79515911 idea导入java工程 file --> new -->存在的工程
- python打开文件的方式
r 以只读模式打开文件 w 以只写模式打开文件,文件若存在,首先要清空,然后(重新创建) a 以追加模式打开(从EOF开始,必要时创建新文件),把所有要写入文件的数据追加到文件的末尾,即使使 ...
- [易学易懂系列|rustlang语言|零基础|快速入门|(9)|Control Flows流程控制]
[易学易懂系列|rustlang语言|零基础|快速入门|(9)] 有意思的基础知识 Control Flows 我们今天再来看看流程控制. 条件控制 if-else if -else: / Simpl ...
- Java基本的程序结构设计 大数操作
大数操作 BigInteger 不可变的任意精度的整数.所有操作中,都以二进制补码形式表示 BigInteger(如 Java 的基本整数类型).BigInteger 提供所有 Java 的基本整数操 ...
- Mac 升级python2.7 到 3.5
Mac 系统 OSX 10.12 以上 第1步:下载Python3.5 下载地址如下: Python3.5 第二步:安装python 3.50 点击下载好的pkg文件进行安装,安装完成之后,pyt ...
- 在CentOS 6.4上安装Puppet配置管理工具
在CentOS 6.4上安装Puppet配置管理工具 linux, puppetAdd comments 五052013 上篇说了下在ubuntu12.04上安装puppet,安装的版本为puppet ...
- jvm——class类文件的结构
class类文件并不一定以磁盘的形式存在,也可以是由类加载器直接生成的二进制流,他其实是一种数据结构,类似于c语言结构体,这种数据结构只有两种数据类型:无符号数和表. 1.魔数:类似于文件拓展名,CA ...
- 安装caffe碰到的坑(各种.so未找到)
./include/caffe/common.hpp:4:32: fatal error: boost/shared_ptr.hpp: 没有那个文件或目录 所有类似于上面的错误,都可以用如下格式来解决 ...
- TTTTTTTTTTTTTT CDOJ Sliding Window 线段树(nlogn)或双端队列(n) 模板
题目链接: L - Sliding Window Time Limit:6000MS Memory Limit:131072KB 64bit IO Format:%lld & ...