pandas基础(第一章(一))
摘要:通过简单例子,了解功能。以此作为基点,在工作中不断深入
1.设置需要显示的行列宽度(显示的最大列数和最大行数,其余部分用.....表示)
设置显示多少行多少列
import pandas as pd
import numpy as np
pd.set_option('max_columns',5,'max_rows',5)
df = pd.read_csv('20190708.csv')
print(df)
'''
pd.set_option('max_columns',3,'max_rows',3)
Unnamed: 0 ... circ_mv
0 0 ... 142940.1406
... ... ... ...
3608 3608 ... 466813.2600 [3609 rows x 19 columns] pd.set_option('max_columns',5,'max_rows',5)
Unnamed: 0 ts_code ... total_mv circ_mv
0 0 603639.SH ... 443175.0623 142940.1406
1 1 600130.SH ... 294144.0000 294144.0000
... ... ... ... ... ...
3607 3607 600017.SH ... 947301.3975 947301.3975
3608 3608 601038.SH ... 774878.1000 466813.2600 [3609 rows x 19 columns] '''
1.pd.set_option
2.提取df索引,并对索引操作
import pandas as pd
import numpy as np
pd.set_option('max_columns',5,'max_rows',5)
df = pd.read_csv('20190708.csv')
print(df)
column_ = df.columns
index_ = df.index
data_ = df.values
print(column_)
print(index_)
print(data_) print(type(column_)) ##<class 'pandas.core.indexes.base.Index'>
print(type(column_.values)) ##class 'numpy.ndarray'
print(type(column_.tolist()))##<class 'list'>
2.1提取索引,数据类型转化
说明:
1.列索引提取出来的数据类型都是Index对象<class 'pandas.core.indexes.base.Index'>

通过column_.values获得## <class 'numpy.ndarray'>数组类
通过column_.tolist()获得##<class 'list'> 列表类
2.行索引与列索引类似

3.访问索引内的值
print(column_.values[1]) ##ts_code同数组取值一样
print(index_.tolist()[1]) ## 1 同list取值一样
4.重命名行列索引
df.index = index_list ##新的行名列表直接赋值
df.columns = column_list
说明:局部行改名,可以先提取行索引,转化成列表,更改对应名称,之后执行df.index = index_list操作。
也可以通过df.rename(index=idx_rename,columns=col_rename),其中idx_rename、col_rename是字典{“旧名”:新名}
3.df取值的方式之标签索引和位置索引
3.1基于标签(索引).loc
单个标签0(解释为标签)或‘a’,列表或数组标签['a','b','c'],带标签的切片‘a’:'f',布尔数组,一个callable带一个参数的函数

布尔数组及callable取值后续更新
3.2基于位置 (整数).iloc (从0到len-1,位置索引不能超过这个索引范围)
基于位置索引的取值方式,大体上与基于标签索引的取值方式一致。
import pandas as pd
import numpy as np
df = pd.read_csv('20190708.csv')
##取0行1列位置的值
print(df.iloc[0,1])
##取指位置定行,返回一个series序列
print(df.iloc[0,:])
##取指定位置列,返回一个series序列
print(df.iloc[:,1])
##行位置切片
print(df.iloc[0:5,:])
##列位置切片
print(df.iloc[:,0:5])
##指定行位置(不连续)多个
print(df.iloc[[0,3,6],:])
##指定列位置(不连续)多个
print(df.iloc[:,[0,2,4]])
##指定行列位置多个
print(df.iloc[[0,3,6],[0,2,4]])
3.2基于位置索引
4.属性访问

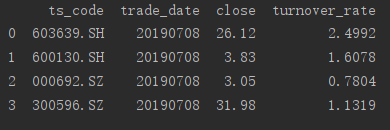
我们通过一个例子,来说明通过属性访问的实现过程
##获得一个序列
series_1 = dfa.ts_code
print(series_1)
通过属性运算'.'的方式获取ts_code这一列的数据,返回一个series序列,这个是数字索引,怎么通过属性获取其中的值(目前不清楚),这里用索引取series_1中的值
print(series_1[1]) ##返回 600130.SH
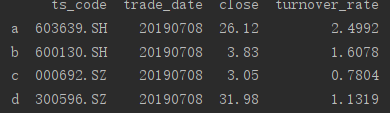
print(series_1) ##输出如下

print(series_1.b)
import pandas as pd
import numpy as np
df = pd.read_csv('20190708.csv')
dfa = df.iloc[[0,1,2,3],[1,2,3,4]]
dfa.index = ['a','b','c','d']
print(dfa)
##获得一个序列
series_1 = dfa.ts_code
print(series_1)
print(series_1.b)
完整代码
5.通过可调用选择(按条件选取)
.loc .iloc 及 []可以接受一个callable索引器。
import pandas as pd
import numpy as np
df = pd.read_csv('20190708.csv')
dfa = df.iloc[[0,1,2,3],[1,2,3,4]]
dfa.index = ['a','b','c','d']
print(dfa)
##显示满足条件的行(.iloc同理)
print(dfa.loc[lambda df:dfa.close>4,:])
##显示满足条件的列(.iloc同理)
print(dfa.loc[:,lambda df:['close','ts_code']])
##[]取 一列数据
print(dfa[lambda dfa:dfa.columns[0]])
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
b 600130.SH 20190708 3.83 1.6078
c 000692.SZ 20190708 3.05 0.7804
d 300596.SZ 20190708 31.98 1.1319
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
d 300596.SZ 20190708 31.98 1.1319
close ts_code
a 26.12 603639.SH
b 3.83 600130.SH
c 3.05 000692.SZ
d 31.98 300596.SZ
a 603639.SH
b 600130.SH
c 000692.SZ
d 300596.SZ
Name: ts_code, dtype: object Process finished with exit code 0
6.布尔操作过滤数据
|(or) &(and) ~(not) ,使用时需用括号进行分组
import pandas as pd
import numpy as np
df = pd.read_csv('20190708.csv')
dfa = df.iloc[[0,1,2,3],[1,2,3,4]]
dfa.index = ['a','b','c','d'] ##对序列操作
series_2 = dfa.close
print(series_2)
##显示序列中大于4的所有数据
print(series_2[series_2>4])
##显示序列中大于4或者小于3.5的
print(series_2[(series_2>4)|(series_2<3.5)])
##显示大于4且 小于30的
print(series_2[(series_2>4)&(series_2<30)])
##显示不大于4的
print(series_2[~(series_2>4)]) ##对df操作
print(dfa[dfa['close']>4])
print(dfa[(dfa['close']>4)&(dfa['turnover_rate']>2)])
a 26.12
b 3.83
c 3.05
d 31.98
Name: close, dtype: float64
a 26.12
d 31.98
Name: close, dtype: float64
a 26.12
c 3.05
d 31.98
Name: close, dtype: float64
a 26.12
Name: close, dtype: float64
b 3.83
c 3.05
Name: close, dtype: float64
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
d 300596.SZ 20190708 31.98 1.1319
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992 Process finished with exit code 0
import pandas as pd
import numpy as np
df = pd.read_csv('20190708.csv')
dfa = df.iloc[[0,1,2,3],[1,2,3,4]]
dfa.index = ['a','b','c','d']
print(dfa)
##使用map函数,判断指定列是否以‘6’开头
criterion = dfa['ts_code'].map(lambda x:x.startswith(''))
print(criterion) ##先产生布尔结果
print(dfa[criterion]) ##在筛选显示
##使用三元表达式筛选
dfb = dfa[[x.startswith('') for x in dfa['ts_code']]]
print(dfb )
##多条件筛选
dfc = dfa[criterion & (dfa['trade_date']==20190708)]
print(dfc)
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
b 600130.SH 20190708 3.83 1.6078
c 000692.SZ 20190708 3.05 0.7804
d 300596.SZ 20190708 31.98 1.1319
a True
b True
c False
d False
Name: ts_code, dtype: bool
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
b 600130.SH 20190708 3.83 1.6078
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
b 600130.SH 20190708 3.83 1.6078
ts_code trade_date close turnover_rate
a 603639.SH 20190708 26.12 2.4992
b 600130.SH 20190708 3.83 1.6078
pandas基础(第一章(一))的更多相关文章
- 20190804-Python基础 第一章
学习爬虫的同时,补充学习更多Python的基础知识,才能让所学更加扎实. 至今,所学的很多东西,基础都不牢固,导致这些所学都是浅尝则止的皮毛,不能真正上战场,故借速成之心,踏实打牢基础,举一反三,以求 ...
- python基础第一章
Python基础 第一个python程序 变量 程序交互 基本数据类型 格式化输出 基本运算符 流程控制if...else... 流程控制-循环 第一个python程序 文件执行 1.用notepad ...
- java基础第一章
有一定的基础,但是还是要重新开始,2020.10.6 1.手写Hello World public class HelloWorld{ public static void main(String[] ...
- JAVA基础第一章-初识java
业内经常说的一句话是不要重复造轮子,但是有时候,只有自己造一个轮子了,才会深刻明白什么样的轮子适合山路,什么样的轮子适合平地! 从今天开始,我将会持续更新java基础知识,欢迎关注. java的诞生 ...
- C语言基础-第一章
1.常量 直接常量: int mm=100; float nn=100.01; 字符常量: 编译指令,#define 常量名 常量值 (预处理命令,预处理命令都#开头.成为宏命令) 关键字, ...
- 深入学习重点分析java基础---第一章:深入理解jvm(java虚拟机) 第一节 java内存模型及gc策略
身为一个java程序员如果只会使用而不知原理称其为初级java程序员,知晓原理而升中级.融会贯通则为高级 作为有一个有技术追求的人,应当利用业余时间及零碎时间了解原理 近期在看深入理解java虚拟机 ...
- Vue基础第一章
Vue的简单示例 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> < ...
- JAVA基础第二章-java三大特性:封装、继承、多态
业内经常说的一句话是不要重复造轮子,但是有时候,只有自己造一个轮子了,才会深刻明白什么样的轮子适合山路,什么样的轮子适合平地! 我将会持续更新java基础知识,欢迎关注. 往期章节: JAVA基础第一 ...
- JAVA 入门第一章(语法基础)
本人初学java 博客分享记录一下自己的学习历程 java我的初步学习分为六章,有c和c++的基础学起来也简便了很多. 第一章 语法基础 第二章 面向对象 第三章 常用工具类 第四章 文件操纵 第五章 ...
- .net架构设计读书笔记--第一章 基础
第一章 基础 第一节 软件架构与软件架构师 简单的说软件架构即是为客户构建一个软件系统.架构师随便软件架构应运而生,架构师是一个角色. 2000年9月ANSI和IEEE发布了<密集性软件架构建 ...
随机推荐
- 06-JavaScript简介
### 前段三大块 ```HTML css JavaScript``` ### 什么是JavaScript? JavaScript是运行在浏览器端的脚步语言,JavaScript主要解决的是前端与用户 ...
- HTML5中的Web Worker
什么是 Web Worker? 当在 HTML 页面中执行脚本时,页面是不可响应的,直到脚本已完成. Web worker 是运行在后台的 JavaScript,独立于其他脚本,不会影响页面的性能.您 ...
- Web学习之CSS总结
银角大王武Sir的博客地址 1.positoin属性固定元素的定位类型 说明:这个属性定义建立元素布局所用的定位机制.任何元素都可以定位,不过绝对或固定元素会生成一个块级框,而无论该元素是什么类型.相 ...
- layui在当前页面弹出一个iframe层,并改变这个iframe层里的一些内容
layer.open({ type: 2, title: "专家信息", area: ['100%', '100%'], content: '/ZhuanJiaKu/AddZhua ...
- MVC加深理解
MVC MVC约定:Controllers文件夹 对应 Views文件夹:所有子文件的名称一一对应. 页面请求 -> 路由 -> 找到 controller/action -> re ...
- git@github.com出现Permission denied (publickey)
上传项目的时候出现Permission denied (publickey)这个问题 解决方案如下: 看本地的.git/config设置的仓库url地址和github使用的链接地址是否一致如下图,如u ...
- pytorch 指定GPU训练
# 1: torch.cuda.set_device(1) # 2: device = torch.device("cuda:1") # 3:(官方推荐)import os os. ...
- [洛谷P3205] HNOI2010 合唱队
问题描述 为了在即将到来的晚会上有更好的演出效果,作为AAA合唱队负责人的小A需要将合唱队的人根据他们的身高排出一个队形.假定合唱队一共N个人,第i个人的身高为Hi米(1000<=Hi<= ...
- 【leetcode】1090. Largest Values From Labels
题目如下: We have a set of items: the i-th item has value values[i] and label labels[i]. Then, we choose ...
- Delphi GridPanel Percent百分比设置
可能很多人都有这个困扰,为什么每次设置一个百分比后,值都会改变,只有设置成absolute才会正常,经摸索发现,是因为精度引起,设置percent的时候,需要将精确到多个小数位.如要有3列,需要设置 ...