Python 3实现网页爬虫
1 什么是网页爬虫
网络爬虫( 网页蜘蛛,网络机器人,网页追逐者,自动索引,模拟程序)是一种按照一定的规则自动地抓取互联网信息的程序或者脚本,从互联网上抓取对于我们有价值的信息。Tips:自动提取网页的程序,为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
2 Python爬虫架构
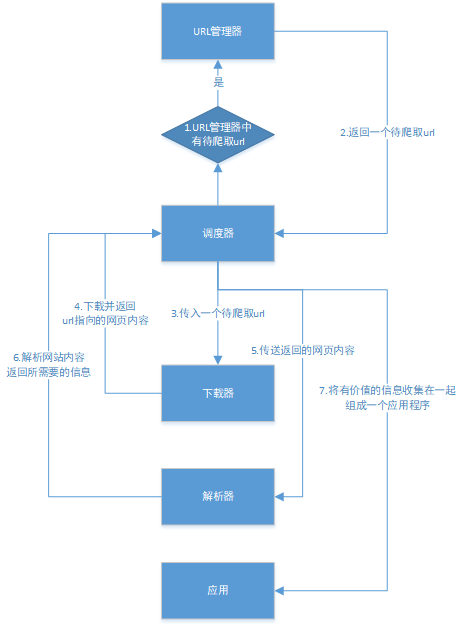
Python爬虫架构主要由调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)5个部分组成。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
下面用一个图来解释一下调度器是如何协调工作的:
3 urllib.request实现下载网页的三种方式
方法一:使用urllib.request.urlopen(url)方法函数实现最基本请求url的发起(打开url网址的操作)
函数原型如下:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
方法二:使用response=urllib.request. Request (url)及urllib.request.urlopen(request)函数
response=urllib.request. Request (url)实现对目标url,data,headers以及method访问
urllib.request.urlopen(request)参数为request对象,代码中 response就是上一步得到的request对象(打开url网址的操作)
Tips:构建一个完整的请求,如果请求中需要加入headers(请求头)等信息,我们就需要使用更强大的Request类来构建一个请求。Request存在的意义是便于在请求的时候传入一些信息,而urlopen则不。
方法三:加入urllib.request处理cookie的能力结合urllib.request.urlopen(url)函数实现
Tips:Python 2使用urllib2代替urllib.request,cookies代替http.cookiejar,print代替print()
#!/usr/bin/python
# -*- coding: UTF-8 -*- import http.cookiejar
import urllib.request url = "http://www.baidu.com"
response1 = urllib.request.urlopen(url)
print ("第一种方法")
# 获取状态码,200表示成功
print (response1.getcode())
# 获取网页内容的长度
print (len(response1.read())) print ("第二种方法")
request = urllib.request.Request(url)
# 模拟Mozilla浏览器进行爬虫
request.add_header("user-agent", "Mozilla/5.0")
response2 = urllib.request.urlopen(request)
print (response2.getcode())
print (len(response2.read())) print ("第三种方法")
cookie=http.cookiejar.CookieJar()
# 加入urllib.request处理cookie的能力
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
urllib.request.install_opener(opener)
response3 = urllib.request.urlopen(url)
print (response3.getcode())
print (len(response3.read()))
print (cookie)
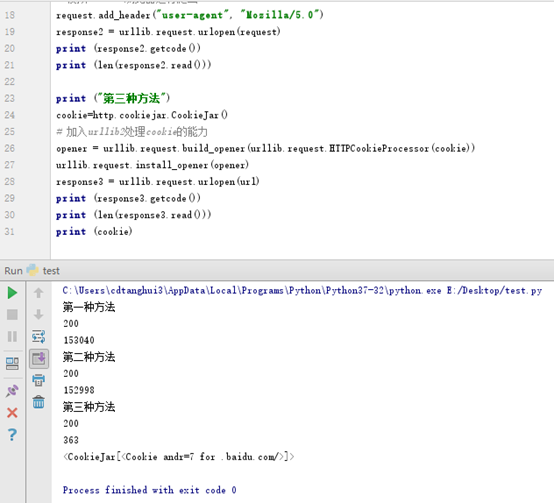
执行结果见下图:
4 使用三方库Beautiful Soup实现解析html文件
4.1 Beautiful Soup的安装
Beautiful Soup:Python 的第三方插件,用来提取 xml 和 HTML 中的数据,官网地址 https://www.crummy.com/software/BeautifulSoup/。
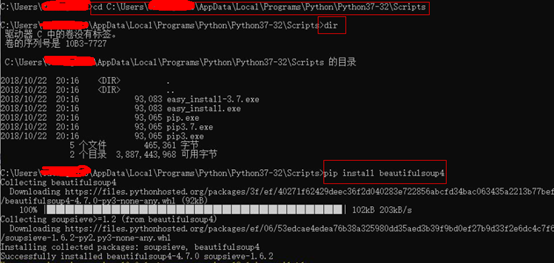
打开cmd(命令提示符),进入到Python(Python3版本)安装目录中的Scripts下,输入dir查看是否有pip.exe,如果用就可以使用Python自带的pip命令进行安装,输入以下命令进行安装即可:
pip install beautifulsoup4
执行如下图:
2、测试是否安装成功
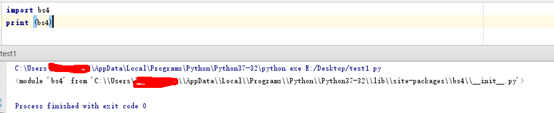
编写一个 Python 文件test.py,输入:
import bs4 print (bs4)
运行该文件,如果能够正常输出则安装成功,如下。
4.2 使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python
# -*- coding: UTF-8 -*- import re from bs4 import BeautifulSoup html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
<a href="https://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a>
<a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a>
<a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a>
<a href="http://xueshu.baidu.com" name="tj_trxueshu" class="mnav">学术</a>
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc, "html.parser")
# 获取所有的链接
links = soup.find_all('a')
print ("所有的链接")
for link in links:
print (link.name, link['href'], link.get_text()) print ("获取特定的URL地址")
link_node = soup.find('a', href="http://news.baidu.com")
print (link_node.name, link_node['href'], link_node['class'], link_node.get_text()) print ("正则表达式匹配")
link_node = soup.find('a', href=re.compile(r"hao"))
print (link_node.name, link_node['href'], link_node['class'], link_node.get_text()) print ("获取P段落的文字")
p_node = soup.find('p', class_='story')
print (p_node.name, p_node['class'], p_node.get_text())
执行结果如下:

------------------------------------------------------Tanwheey-------------------------------------------------------------------------
爱生活,爱工作。
Python 3实现网页爬虫的更多相关文章
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- Python网页爬虫(一)
很多时候我们想要获得网站的数据,但是网站并没有提供相应的API调用,这时候应该怎么办呢?还有的时候我们需要模拟人的一些行为,例如点击网页上的按钮等,又有什么好的解决方法吗?这些正是python和网页爬 ...
- python 网页爬虫+保存图片+多线程+网络代理
今天,又算是浪费了一天了.python爬虫,之前写过简单的版本,那个时候还不懂原理,现在算是收尾吧. 以前对网页爬虫不了解,感觉非常神奇,但是解开这面面纱,似乎里面的原理并不是很难掌握.首先,明白一个 ...
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
- Python带你轻松进行网页爬虫
前不久DotNet开源大本营通过为.NET程序员演示如何在.NET下使用C#+HtmlAgilityPack+XPath进行网页数据的抓取,从而为我们展示了HtmlAgilitypack利器的优点和使 ...
- Python十分适合用来开发网页爬虫
Python十分适合用来开发网页爬虫,理由如下:1.抓取网页自身的接口比较与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简练:比较其他动态脚本语言,如perl,shel ...
- 【Python】Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
本文转载自:https://www.cnblogs.com/colipso/p/4284510.html 好文 mark http://www.52nlp.cn/python-%E7%BD%91%E9 ...
- 多线程网页爬虫 python 实现
采用了多线程和锁机制,实现了广度优先算法的网页爬虫. 对于一个网络爬虫,如果要按广度遍历的方式下载,它就是这样干活的: 1.从给定的入口网址把第一个网页下载下来 2.从 ...
- python实现的一个简单的网页爬虫
学习了下python,看了一个简单的网页爬虫:http://www.cnblogs.com/fnng/p/3576154.html 自己实现了一个简单的网页爬虫,获取豆瓣的最新电影信息. 爬虫主要是获 ...
随机推荐
- 机器学习中的偏差(bias)和方差(variance)
转发:http://blog.csdn.net/mingtian715/article/details/53789487请移步原文 内容参见stanford课程<机器学习> 对于已建立 ...
- js基础复习~Array对象
Array对象 lenght 获取到数组的长度 concat() 方法用于合并两个或多个数组.此方法不会更改两大有数组,而是返回一个新的数组 let arr1 = ["a",&qu ...
- linux运维、架构之路-tomcat日志切割工具 logrotate
一.Logrotate简介 1.Logrotate实际就是对日志进行切割的小工具,他通过让用户来配置规则的方式,检测和处理日志文件.配合Cron可让处理定时化:2.Logrotate预制了大量判断条件 ...
- onload in JavaScript
https://www.w3schools.com/tags/ev_onload.asp Example Execute a JavaScript immediately after a page h ...
- python练习题--计算总分平均分操作excel
''' 有一个存着学生成绩的文件,里面存的是json串,json串读起来特别不直观,需要你写代码把它都写到excel中,并计算出总分和平均分,json格式如下 { "1":[&qu ...
- 鸡肋工具-Oracle建表工具
为什么叫鸡肋工具呢,因为我们完全可以在pl/sql上直接建立表.索引.同义词.授权.触发器等. 写这个工具目的是因为公司的本地.测试环境开发无权创建表,每次成员建表语句千奇百怪不规范,所以写了这么个工 ...
- dataframe中的数据类型及转化
1 float与str的互化 import pandas as pd import numpy as np df = pd.DataFrame({'a':[1.22, 4.33], 'b':[3.44 ...
- 《Python Data Structures》Week5 Dictionary 课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week5 Dictionary 9.1 Dictionaries 字 ...
- docker远程访问TLS证书认证shell
docker开启远程访问端口,防止非法访问 配置证书认证 配置防火墙或安全策略 #!/bin/bash # docker.tls.sh # 环境centos 7 ,root # 创建 Docker T ...
- idea多行注释缩进
选中多行代码 - 按下tab键——向后整体移动 选中多行代码 - 按下shift + tab键——向前整体缩进(整体去掉代码前面的空格)