字符集详解 ASCII码、Unicode、UTF-8 (转)
认识字符集
对于计算机而言,它仅认识两个0和1,不管是在内存中还是外部存储设备上,我们所看到的文字、图片、视频等等“数据”在计算机中都是已二进制形式存在的。不同字符对应二进制数的规则,就是字符的编码。字符编码的集合称为字符集。
在早期的计算机系统中,使用的字符是非常少的,他们只包括26个英文字母、数字符号和一些常用符号,对于这些字符进行编码,用1个字节就足够了,但是随着计算机的不断发展,为了适应全世界其他各国民族的语言,这些少得可怜的字符编码肯定是不够的。于是人们提出了UNICODE编码,它采用双字节编码,兼容英文字符和其他国家民族的双字节字符编码。
每个国家为了统一编码都会规定该国家/地区计算机信息交换用的字符集编码,为了解决本地字符信息的计算机处理,于是出现了各种本地化版本,引进LANG, Codepage 等概念。现在大部分具有国际化特征的软件核心字符处理都是以 Unicode 为基础的,在软件运行时根据当时的 Locale/Lang/Codepage 设置确定相应的本地字符编码设置,并依此处理本地字符。在处理过程中需要实现 Unicode 和本地字符集的相互转换。
常见字符编码
计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。常见的字符编码主要包括:ASCII编码、GB**编码、Unicode。
1.ASCII编码
我们都知道,在计算机的世界里,信息的表示方式只有 0 和 1,但是我们人类信息表示的方式却与之大不相同,很多时候是用语言文字、图像、声音等传递信息的。
那么我们怎样将其转化为二进制存储到计算机中,这个过程我们称之为编码。更广义地讲就是把信息从一种形式转化为另一种形式的过程。
我们知道一个二进制有两种状态:”0” 状态 和 “1”状态,那么它就可以代表两种不同的东西,我们想赋予它什么含义,就赋予什么含义,比如说我规定,“0” 代表 “吃过了”, “1”代表 “还没吃”。
这样,我们就相当于把现实生活中的信息编码成二进制数字了,并且这个例子中是一位二进制数字,那么 2 位二进制数可以代表多少种情况能?对,是四种,2^2,分别是 00、01、10、11,那 7 种呢?答案是 2^7=128。
我们知道,在计算机中每八个二进制位组成了一个字节(Byte),计算机存储的最小单位就是字节,字节如下图所示 :

所以早期人们用 8 位二进制来编码英文字母(最前面的一位是 0),也就是说,将英文字母和一些常用的字符和这 128 中二进制 0、1 串一一对应起来,比如说 大写字母“A”所对应的二进制位“01000001”,转换为十六进制为 41。
在美国,这 128 是够了,但是其他国家不答应啊,他们的字符和英文是有出入的,比如在法语中在字母上有注音符号,如 é ,这个怎么表示成二进制?
所以各个国家就决定把字节中最前面未使用的那一个位拿来使用,原来的 128 种状态就变成了 256 种状态,比如 é 就被编码成 130(二进制的 10000010)。
为了保持与 ASCII 码的兼容性,一般最高为为 0 时和原来的 ASCII 码相同,最高位为 1 的时候,各个国家自己给后面的位 (1xxx xxxx) 赋予他们国家的字符意义。
但是这样一来又有问题出现了,不同国家对新增的 128 个数字赋予了不同的含义,比如说 130 在法语中代表了 é,但是在希伯来语中却代表了字母 Gimel(这不是希伯来字母,只是读音翻译成英文的形式)具体的希伯来字母 Gimel 看下图

所以这就成了不同国家有不同国家的编码方式,所以如果给你一串二进制数,你想要解码,就必须知道它的编码方式,不然就会出现我们有时候看到的乱码 。
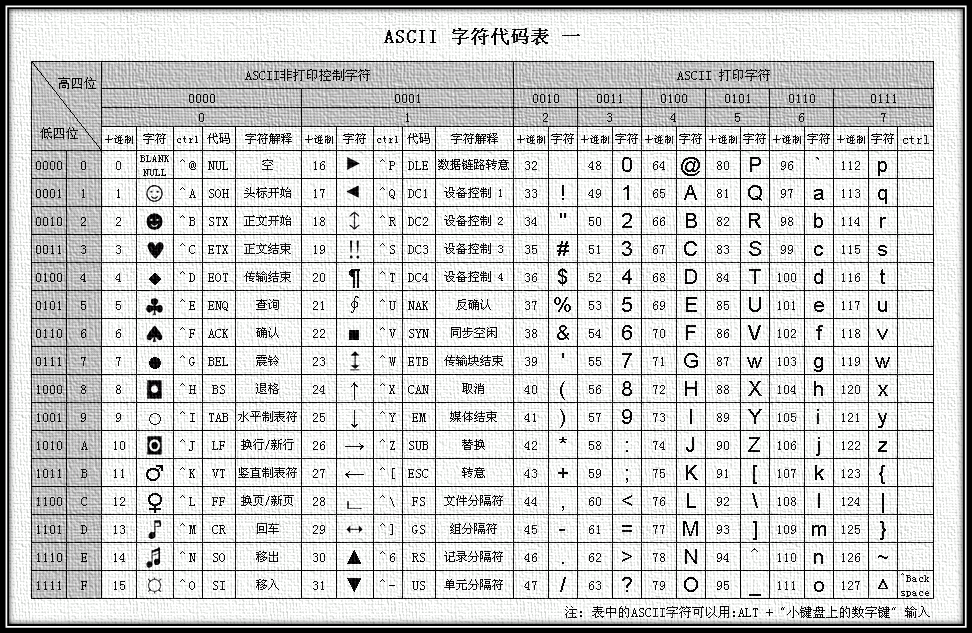
图1 ASCII编码表

图2 扩展ASCII编码表
2.Unicode
Unicode 为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF (十六进制),有 110 多万,每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,在前面加上 U+。例如:“马”的 Unicode 是U+9A6C。
Unicode 就相当于一张表,建立了字符与编号之间的联系
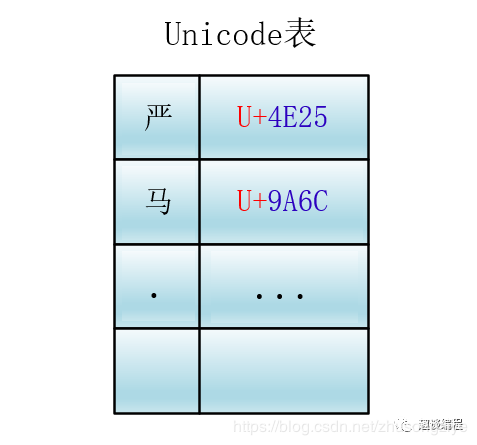
它是一种规定,Unicode 本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
有的人会说了,那我可以直接把 Unicode 编号直接转换成二进制进行存储,是的,你可以,但是这个就需要人为的规定了,而 Unicode 并没有说这样弄,因为除了你这种直接转换成二进制的方案外,还有其他方案,接下来我们会逐一看到。
编号怎么对应到二进制表示呢?有多种方案:主要有 UTF-8,UTF-16,UTF-32。下面主要讲UTF-8
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍:UTF-8是Unicode的实现方式之一。
UTF-8 使用变长字节表示,顾名思义,就是使用的字节数可变,这个变化是根据 Unicode 编号的大小有关,编号小的使用的字节就少,编号大的使用的字节就多。使用的字节个数从 1 到 4 个不等。
UTF-8 的编码规则是:
① 对于单字节的符号,字节的第一位设为 0,后面的7位为这个符号的 Unicode 码,因此对于英文字母,UTF-8 编码和 ASCII 码是相同的。
② 对于n字节的符号(n>1),第一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10,剩下的没有提及的二进制位,全部为这个符号的 Unicode 码 。
举个例子:比如说一个字符的 Unicode 编码是 130,显然按照 UTF-8 的规则一个字节是表示不了它(因为如果是一个字节的话前面的一位必须是 0),所以需要两个字节(n = 2)。
根据规则,第一个字节的前 2 位都设为 1,第 3(2+1) 位设为 0,则第一个字节为:110X XXXX,后面字节的前两位一律设为 10,后面只剩下一个字节,所以后面的字节为:10XX XXXX。
所以它的格式为 110XXXXX 10XXXXXX 。
下面我们来具体看看具体的 Unicode 编号范围与对应的 UTF-8 二进制格式
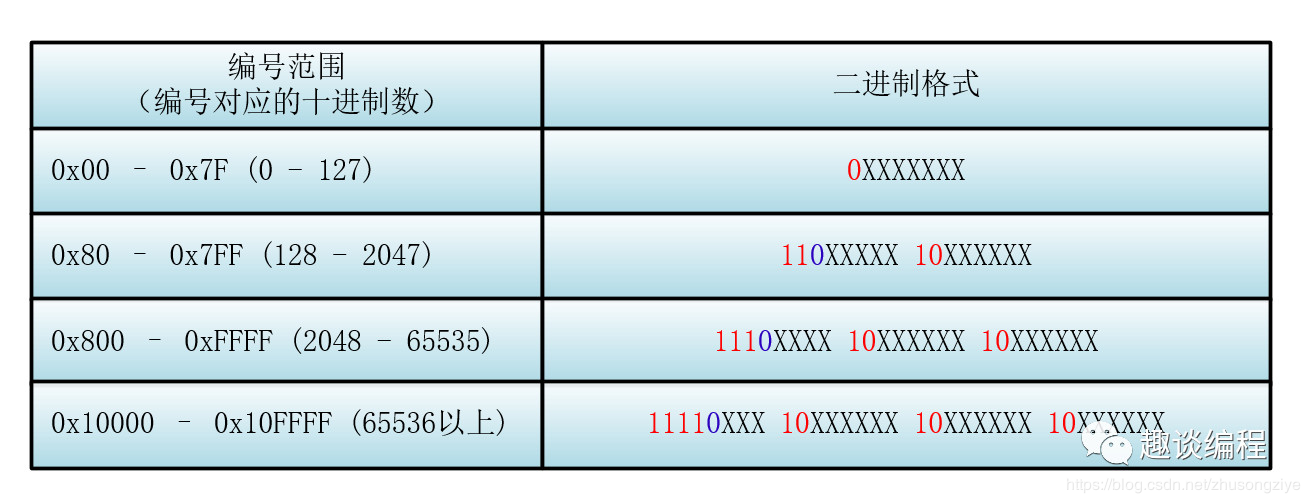
那么对于一个具体的 Unicode 编号,具体怎么进行 UTF-8 的编码呢?
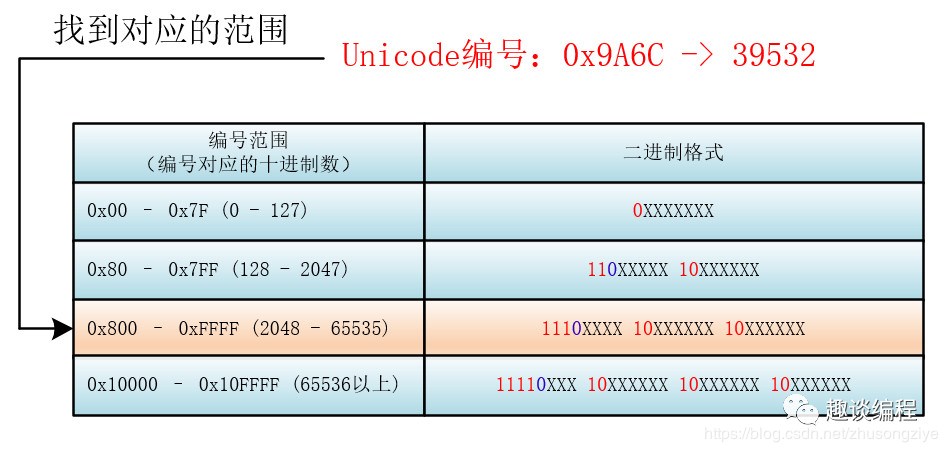
首先找到该 Unicode 编号所在的编号范围,进而可以找到与之对应的二进制格式,然后将该 Unicode 编号转化为二进制数(去掉高位的 0),最后将该二进制数从右向左依次填入二进制格式的 X 中,如果还有 X 未填,则设为 0 。
比如:“马”的 Unicode 编号是:0x9A6C,整数编号是 39532,对应第三个范围(2048 - 65535),其格式为:1110XXXX 10XXXXXX 10XXXXXX,39532 对应的二进制是 1001 1010 0110 1100,将二进制填入进入就为:
11101001 10101001 10101100 。

由于 UTF-8 的处理单元为一个字节(也就是一次处理一个字节),所以处理器在处理的时候就不需要考虑这一个字节的存储是在高位还是在低位,直接拿到这个字节进行处理就行了,因为大小端是针对大于一个字节的数的存储问题而言的。
参考出处:http://cmsblogs.com/?p=1530
https://blog.csdn.net/zhusongziye/article/details/84261211
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
字符集详解 ASCII码、Unicode、UTF-8 (转)的更多相关文章
- MySQL字符集详解
Reference: https://www.cnblogs.com/wcwen1990/p/6917109.html MySQL字符集详解 一.字符集和校验规则 字符集是一套符合和编码,校验规 ...
- Java开源生鲜电商平台-盈利模式详解(源码可下载)
Java开源生鲜电商平台-盈利模式详解(源码可下载) 该平台提供一个联合买家与卖家的一个平台.(类似淘宝购物,这里指的是食材的购买.) 平台有以下的盈利模式:(类似的平台有美菜网,食材网等) 1. 订 ...
- ArrayList详解-源码分析
ArrayList详解-源码分析 1. 概述 在平时的开发中,用到最多的集合应该就是ArrayList了,本篇文章将结合源代码来学习ArrayList. ArrayList是基于数组实现的集合列表 支 ...
- LinkedList详解-源码分析
LinkedList详解-源码分析 LinkedList是List接口的第二个具体的实现类,第一个是ArrayList,前面一篇文章已经总结过了,下面我们来结合源码,学习LinkedList. 基于双 ...
- 字符编码详解及由来(UNICODE,UTF-8,GBK)[转帖]
相信許多人對字符編碼都不是很了解,透過下文可以清晰的理解各种字符编码方式详解及由来. 一直对字符的各种编码方式懵懵懂懂,什么ANSI.UNICODE.UTF-8.GB2312.GBK.DBCS.UCS ...
- MultiByteToWideChar和WideCharToMultiByte用法详解, ANSI和UNICODE之间的转换
//========================================================================//TITLE:// MultiByteToW ...
- 彻底搞懂字符集编码:ASCII,Unicode 和 UTF-8
一.ASCII 码 我们知道,计算机内部,所有信息最终都是一个二进制值.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte).也就是说,一个 ...
- Shiro的Filter机制详解---源码分析
Shiro的Filter机制详解 首先从spring-shiro.xml的filter配置说起,先回答两个问题: 1, 为什么相同url规则,后面定义的会覆盖前面定义的(执行的时候只执行最后一个). ...
- Ascii码 unicode码 utf-8编码 gbk编码的区别
ASCII码: 只包含英文,数字,特殊符号的编码,一个字符用8位(bit)1字节(byte)表示 Unicode码: 又称万国码,包含全世界所有的文字,符号,一个字符用32位(bit)4字节(byte ...
随机推荐
- HUD 1166:敌兵布阵(线段树 or 树状数组)
敌兵布阵 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Problem Des ...
- nginx 与location语法详解
Location语法优先级排列 匹配符 匹配规则 优先级 = 精确匹配 1 ^~ 以某个字符串开头 2 ~ 区分大小写的正则匹配 3 ~* 不区分大小写的正则匹配 4 !~ 区分大小写不匹配的正则 ...
- SVN提交大量无效文件补救方法
有的时候,使用SVN时候会发现,由于系统编译器的问题,会自动生成大量.class文件, 或者一些多余的配置文件,这里主要就是整理一下,当如果手误,将这些多余文件都提交到了svn上面的补救方法. 可以在 ...
- vue项目使用cropperjs制作图片剪裁,压缩组件
项目中裁剪图片效果 代码部分:(将上传部分 封装成一个组件直接调用当前组件) <template> <div id="demo"> <!-- 遮罩层 ...
- qmake生成VS的vcproj/sln工程文件
qmake 生成的vs工程与环境变量中的 qmakespec相关,可以有两种方法: 1.默认情况下,即环境变量qmakespec为你装的qt for vs的版本,默认生成的为该版本的vs工程,如,你装 ...
- Why are dashes preferred for CSS selectors / HTML attributes?
Why are dashes preferred for CSS selectors / HTML attributes? I use dashes because I don't have to h ...
- redis扫描特定keys脚本,可避免阻塞,不影响线上业务
#!/bin/sh ## 该脚本用来查询redis集群中,各个实例当中特定前缀的key,对应只需要修改redis的其中一个实例的 host和port## 脚本会自动识别出该集群的所有实例,并查出对应实 ...
- DAY 3模拟赛
DAY3 钟皓曦来了! T1 网址压缩 [问题描述] 你是能看到第一题的 friends 呢. ——hja 众所周知,小葱同学擅长计算,尤其擅长计算组合数,但这个题和组合数没什么关 ...
- DeepFaceLab: 可视化交互式合成功能简介!
DeepFaceLab在沉寂了几个月后(目测Iperov同志讨生活去了),在8月下旬又迎来了重大更新.我总结了一下,主要是更新了三大功能. 新增Avatar模型 交互式转换器 半脸模型支持FAN ...
- Dojo入门:dojo中的事件处理
JS为DOM添加事件 在原生的环境下,为DOM添加事件处理函数有多种方法: <input type="button" name="btn" value ...