Dynamic Programming and Policy Evaluation
Dynamic Programming divides the original problem into subproblems, and then complete the whole task by recursively conquering these subproblems. The key idea of DP, and of reinforcement learning generally, is the use of value functions to organize and structure the search for good policies. It assumes the full knowledge of the environment: someone tells us the state space, action space, transition struction, the reward structure, discounted factor...
We start with policy evaluation: given the MDP and an arbitary Policy π, we use Bellman Equation to recursively calculate the State-Value function:
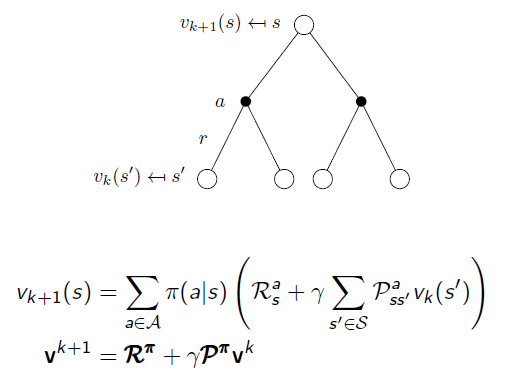
And the policy evaluation algorithm is given by following:

The stop criteria is only very small change for the value state function.
The example is a GridWorld puzzle, the task is to reach grey cell with most reward. The policy for the possible actions (up,down,left,right) are equivalent, all 25%.
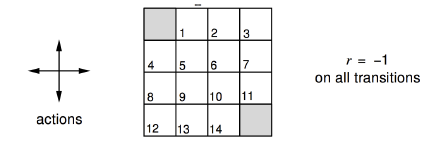
Like a random walk, after calculation, we got :

Dynamic Programming and Policy Evaluation的更多相关文章
- 强化学习三:Dynamic Programming
1,Introduction 1.1 What is Dynamic Programming? Dynamic:某个问题是由序列化状态组成,状态step-by-step的改变,从而可以step-by- ...
- Monte Carlo Policy Evaluation
Model-Based and Model-Free In the previous several posts, we mainly talked about Model-Based Reinfor ...
- Ⅲ Dynamic Programming
Dictum: A man who is willing to be a slave, who does not know the power of freedom. -- Beck 动态规划(Dy ...
- 动态规划 Dynamic Programming
March 26, 2013 作者:Hawstein 出处:http://hawstein.com/posts/dp-novice-to-advanced.html 声明:本文采用以下协议进行授权: ...
- Dynamic Programming
We began our study of algorithmic techniques with greedy algorithms, which in some sense form the mo ...
- HDU 4223 Dynamic Programming?(最小连续子序列和的绝对值O(NlogN))
传送门 Description Dynamic Programming, short for DP, is the favorite of iSea. It is a method for solvi ...
- hdu 4223 Dynamic Programming?
Dynamic Programming? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Oth ...
- XACML-条件评估(Condition evaluation),规则评估(Rule evaluation),策略评估(Policy evaluation),策略集评估(PolicySet evaluation)
本文由@呆代待殆原创,转载请注明出处. 一.条件评估(Condition evaluation) <Condition>元素缺失时或评估结果为真时,条件值为True. <Condit ...
- 算法导论学习-Dynamic Programming
转载自:http://blog.csdn.net/speedme/article/details/24231197 1. 什么是动态规划 ------------------------------- ...
随机推荐
- MySQL之Foreign_Key
MySQL之Foregin_Key 一\\一对多 一.员工表和部门表 dep emp 类似与我们将所有的代码都写在一个py文件内 确立标语表之间的关系 思路:一定要要换位思考问题(必须两方都考虑周全之 ...
- VB之Collection---Collection集合类
你看到的这个文章来自于http://www.cnblogs.com/ayanmw 由于要对一些数据进行处理,比较麻烦,实现某个算法要处理大量不同的不同类型的数据. 所以考虑到一些因素,又在使用VB6( ...
- 10年前文章_UC3A/B 开发环境设置
大部分设置和 Z32U 交叉编译环境的配置 类似 Windows 环境 步骤二: 安装 toolchain 和mkII lite V2 的驱动 安装运行 avr32-gnu-toolchain-2.0 ...
- PHP程序员要看的书单
想提升自己,还得多看书!多看书!多看书! 下面是我收集到的一些PHP程序员应该看得书单及在线教程,自己也没有全部看完.共勉吧! Github地址:https://github.com/52fhy/ph ...
- CSS3边框 圆角效果 border-radius
border-radius是向元素添加圆角边框 使用方法: border-radius:10px; /* 所有角都使用半径为10px的圆角 */ border-radius: 5px 5px 5px ...
- Linux C编程学习
C语言简介 简介 C语言具有控制特性较强.高效性.可移植性和强大的功能和灵活性."自由的代价是永远的警惕",C的简洁性与其丰富的运算符相结合,使其可能会编写出较难理解的代码.面向对 ...
- JavaSE---泛型系统学习
1.概述 1.1.泛型: 允许在 定义 类.接口.方法时 使用 类型形参,这个类型形参 将在声明变量.创建对象.调用方法时 动态地指定: 1.2.jdk5后,引入了 参数化类型(允许程 ...
- python补充之进制转换、exec、eval、compile
目录 eval.exec和compile 1.eval函数 2.exec函数 eval()函数和exec()函数的区别 python中的进制转换 eval.exec和compile 1.eval函数 ...
- python学习_day1
简单的输入与输出 python3.x输入 用内置函数input(),返回的数据类型是string,输出用print() 查看数据类型 用type方法 例如 a = int(input('请输入:')) ...
- Leetcode 1. Two Sum(hash+stl)
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...