初步认识Hive
初步认识Hive

hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive 的设计特点如下:
● 支持索引,加快数据查询。
● 不同的存储类型,例如,纯文本文件、HBase 中的文件。
● 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
● 可以直接使用存储在Hadoop 文件系统中的数据。
● 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
● 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
Hive和传统数据库的比较

基本数据类型
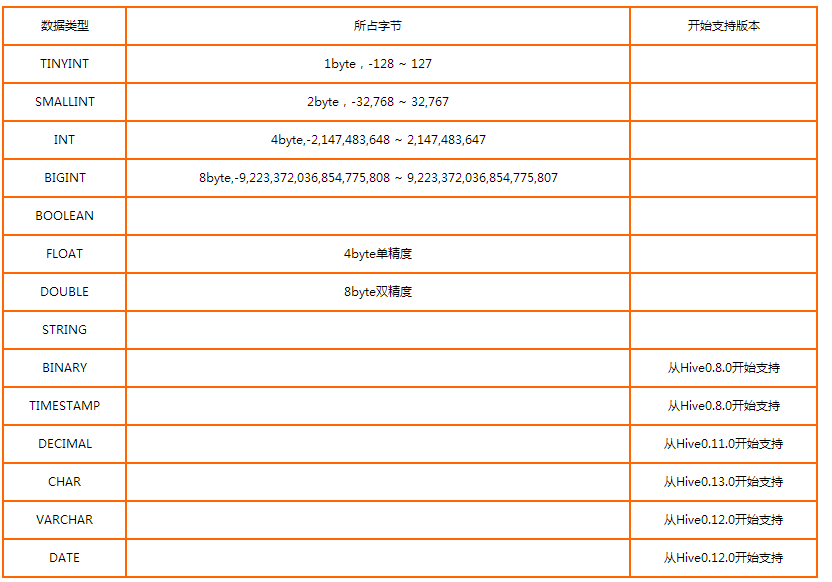
hive支持多种不同长度的整型和浮点型数据,支持布尔型,也支持无长度限制的字符串类型。例如:TINYINT、SMALINT、BOOLEAN、FLOAT、
DOUBLE、STRING等基本数据类型。这些基本数据类型和其他sql方言一样,都是保留字。
Hive基本数据类型:TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,BINARY,TIMESTAMP,DECIMAL,CHAR,VARCHAR,DATE。
集合数据类型
hive中的列支持使用struct、map和array集合数据类型。大多数关系型数据库中不支持这些集合数据类型,因为它们会破坏标准格式。关系型数据库中为实现集合数据类型是由多个表之间建立合适的外键关联来实现。在大数据系统中,使用集合类型的数据的好处在于提高数据的吞吐量,减少寻址次数来提高查询速度。
CREATE TABLE STUDENTINFO ( NAME STRING, FAVORITE ARRAY<STRING>, COURSE MAP<STRING,FLOAT>, ADDRESS STRUCT<CITY:STRING,STREET:STRING> )
查询语法:SELECT S.NAME,S.FAVORITE[0],S.COURSE["ENGLISH"],S.ADDRESS.CITY FROM STUDENTINFO S;
数据存储
1.首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
2.其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
3.Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
4.Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, ctry = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds = 20090801, ctry = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
5.Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020。
6.External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
注意:
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External Table 时,仅删除元数据,表中的数据不会真正被删除。
初步认识Hive的更多相关文章
- 1.5 Hive初步使用和安装MySQL
一.HQL初步试用 1.创建一个student表 #创建一个student表 hive> create table student(id int, name string) ROW FORMAT ...
- Hive初步认识,理解Hive(一)
Hive初步认识,理解Hive(一) 用了有一段时间的Hive了,之前一直以为hive是个数据库,类似Mysql.Oracle等数据库一样,其实不然. Hive是实现Hadoop 的MapReduce ...
- Hadoop: the definitive guide 第三版 拾遗 第十二章 之Hive初步
Hive简介 Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在 Hadoop 中的大规模数据的机制 ...
- Hive初步使用、安装MySQL 、Hive配置MetaStore、配置Hive日志《二》
一.Hive的简单使用 基本的命令和MySQL的命令差不多 首先在 /opt/datas 下创建数据 students.txt 1001 zhangsan 1002 lisi 1003 wangwu ...
- hive的初步认识与hive的本质
Hive是什么?就从这儿开始学习.... Hive是建立在Hadoop hdfs上的数据仓库基础架构. Hive可以用来数据抽取转换加载(ETL). Hive定义了简单的类SQL查询语句,称为HQL. ...
- Hadoop Hive概念学习系列之hive的正则表达式初步(六)
说在前面的话 hive的正则表达式,是非常重要!作为大数据开发人员,用好hive,正则表达式,是必须品! Hive中的正则表达式还是很强大的.数据工作者平时也离不开正则表达式.对此,特意做了个hive ...
- hive 调优总结
一.join优化 做join之前对数据进行预处理,减少参加join的数据量,把数据量少的表放入内存中,制作map端的join 应该将条目少的表/子查询放在 Join 操作符的左边.原因是在 Join ...
- 从零自学Hadoop(15):Hive表操作
阅读目录 序 创建表 查看表 修改表 删除表 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceL ...
- 《OD学hive》第四周0717
一.Hive基本概念.安装部署与初步使用 1. 后续课程 Hive 项目:hadoop hive sqoop flume hbase 电商离线数据分析 CDH Storm:分布式实时计算框架 Spar ...
随机推荐
- php中读写excel表格文件示例。
测试环境:php5.6.24.这块没啥兼容问题. 需要更多栗子,请看PHPExcel的examples.还是蛮强大的. 读取excel文件. 第一步.下载开源的PHPExcel的类库文件,官方网站是h ...
- PHP curl超时问题
今天调试一个非常老的代码时 发现nginx服务器超时 改了下nginx配置 发现是后台脚本一直等待 排查到最后发现是curl 超时引起的等待 具体解决方案: curl_setopt( $this ...
- Windows台的FailOver群集简介
首先,您需要有一些服务器硬件方面知识. 我们介绍Windows平台的FailOver群集,以多个站点场景为例,如下图示: 八个结点NODE,Windows的FailOver群集,依赖SAN存储同步各个 ...
- MyEclipse10 中的两种FreeMarker插件的安装与配置
第一个插件是: freemarker-ide MyEclipce10.0中安装FreeMarker插件,这绝对是最简单的方法 ...
- Dynamics.js - 创建逼真的物理动画的 JS 库
Dynamics.js 是一个用来创建物理动画 JavaScript 库.你只需要把dynamics.js引入你的页面,然后就可以激活任何 DOM 元素的 CSS 属性动画,也可以用户 SVG 属性. ...
- [js开源组件开发]localStorage-cache本地存储的缓存管理
localStorage-cache本地存储的缓存管理 距离上次的组件开发有近三个月的时间了,最近一直在做一些杂事,无法静下心来写写代码,也是在学习emberjs,在emberjs中有一个很重要的东西 ...
- easyui1.3.2中使用1.3.6或1.4.x的calendar
首先在1.3.2中calendar控件不支持日历某天的颜色进行改变,和自定义回调函数 Name Type Description Default width number The width of c ...
- select中无法使用click的处理
今天工作用到了select,想要给option添加click点击事件,可是却没有任何效果,百度了才发现,原来竟然是不支持呀! 众所周知(其实我才知道哎),在IE里, select的option是不支持 ...
- CSS学习总结(二)
一.id及class选择符 id和class的名称是由用户自定义的.id号可以唯一地标识html元素,为元素指定样式.id选择符以#来定义. 1.id选择符 注:在网页中,每个id名只能是唯一不重 ...
- ABAP 数据字典中的参考表和参考字段的作用
ABAP数据字典中的参考表和参考字段的作用 大家最初在SE11中创建表和结构的时候都会遇到一个问题,如果设定了某个字段为QUAN或者CURR类型,也就是数量或金额的时候,总会要求输入一个参考 ...