编写高质量代码:改善Java程序的151个建议(第6章:枚举和注解___建议88~92)
建议88:用枚举实现工厂方法模式更简洁
工厂方法模式(Factory Method Pattern)是" 创建对象的接口,让子类决定实例化哪一个类,并使一个类的实例化延迟到其它子类"。工厂方法模式在我们的开发中经常会用到。下面以汽车制造为例,看看一般的工厂方法模式是如何实现的,代码如下:
//抽象产品
interface Car{ }
//具体产品类
class FordCar implements Car{ }
//具体产品类
class BuickCar implements Car{ }
//工厂类
class CarFactory{
//生产汽车
public static Car createCar(Class<? extends Car> c){
try {
return c.newInstance();
} catch (InstantiationException | IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
}
这是最原始的工厂方法模式,有两个产品:福特汽车和别克汽车,然后通过工厂方法模式来生产。有了工厂方法模式,我们就不用关心一辆车具体是怎么生成的了,只要告诉工厂" 给我生产一辆福特汽车 "就可以了,下面是产出一辆福特汽车时客户端的代码:
public static void main(String[] args) {
//生产车辆
Car car = CarFactory.createCar(FordCar.class);
}
这就是我们经常使用的工厂方法模式,但经常使用并不代表就是最优秀、最简洁的。此处再介绍一种通过枚举实现工厂方法模式的方案,谁优谁劣你自行评价。枚举实现工厂方法模式有两种方法:
(1)、枚举非静态方法实现工厂方法模式
我们知道每个枚举项都是该枚举的实例对象,那是不是定义一个方法可以生成每个枚举项对应产品来实现此模式呢?代码如下:
enum CarFactory {
// 定义生产类能生产汽车的类型
FordCar, BuickCar;
// 生产汽车
public Car create() {
switch (this) {
case FordCar:
return new FordCar();
case BuickCar:
return new BuickCar();
default:
throw new AssertionError("无效参数");
}
}
}
create是一个非静态方法,也就是只有通过FordCar、BuickCar枚举项才能访问。采用这种方式实现工厂方法模式时,客户端要生产一辆汽车就很简单了,代码如下:
public static void main(String[] args) {
// 生产车辆
Car car = CarFactory.BuickCar.create();
}
(2)、通过抽象方法生成产品
枚举类型虽然不能继承,但是可以用abstract修饰其方法,此时就表示该枚举是一个抽象枚举,需要每个枚举项自行实现该方法,也就是说枚举项的类型是该枚举的一个子类,我们俩看代码:
enum CarFactory {
// 定义生产类能生产汽车的类型
FordCar{
public Car create(){
return new FordCar();
}
},
BuickCar{
public Car create(){
return new BuickCar();
}
};
//抽象生产方法
public abstract Car create();
}
首先定义一个抽象制造方法create,然后每个枚举项自行实现,这种方式编译后会产生CarFactory的匿名子类,因为每个枚举项都要实现create抽象方法。客户端调用与上一个方案相同,不再赘述。
大家可能会问,为什么要使用枚举类型的工厂方法模式呢?那是因为使用枚举类型的工厂方法模式有以下三个优点:
- 避免错误调用的发生:一般工厂方法模式中的生产方法(也就是createCar方法),可以接收三种类型的参数:类型参数(如我们的例子)、String参数(生产方法中判断String参数是需要生产什么产品)、int参数(根据int值判断需要生产什么类型的的产品),这三种参数都是宽泛的数据类型,很容易发生错误(比如边界问题、null值问题),而且出现这类错误编译器还不会报警,例如:
public static void main(String[] args) {
// 生产车辆
Car car = CarFactory.createCar(Car.class);
}
Car是一个接口,完全合乎createCar的要求,所以它在编译时不会报任何错误,但一运行就会报出InstantiationException异常,而使用枚举类型的工厂方法模式就不存在该问题了,不需要传递任何参数,只需要选择好生产什么类型的产品即可。
- 性能好,使用简洁:枚举类型的计算时以int类型的计算为基础的,这是最基本的操作,性能当然会快,至于使用便捷,注意看客户端的调用,代码的字面意思就是" 汽车工厂,我要一辆别克汽车,赶快生产"。
- 降低类间耦合:不管生产方法接收的是Class、String还是int的参数,都会成为客户端类的负担,这些类并不是客户端需要的,而是因为工厂方法的限制必须输入的,例如Class参数,对客户端main方法来说,他需要传递一个FordCar.class参数才能生产一辆福特汽车,除了在create方法中传递参数外,业务类不需要改Car的实现类。这严重违背了迪米特原则(Law of Demeter 简称LoD),也就是最少知识原则:一个对象应该对其它对象有最少的了解。
而枚举类型的工厂方法就没有这种问题了,它只需要依赖工厂类就可以生产一辆符合接口的汽车,完全可以无视具体汽车类的存在。
建议89:枚举项的数量限制在64个以内
为了更好地使用枚举,Java提供了两个枚举集合:EnumSet和EnumMap,这两个集合使用的方法都比较简单,EnumSet表示其元素必须是某一枚举的枚举项,EnumMap表示Key值必须是某一枚举的枚举项,由于枚举类型的实例数量固定并且有限,相对来说EnumSet和EnumMap的效率会比其它Set和Map要高。
虽然EnumSet很好用,但是它有一个隐藏的特点,我们逐步分析。在项目中一般会把枚举用作常量定义,可能会定义非常多的枚举项,然后通过EnumSet访问、遍历,但它对不同的枚举数量有不同的处理方式。为了进行对比,我们定义两个枚举,一个数量等于64,一个是65(大于64即可,为什么是64而不是128,512呢,一会解释),代码如下:
//普通枚举项,数量等于64
enum Const{
A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,
AA,BB,CC,DD,EE,FF,GG,HH,II,JJ,KK,LL,MM,NN,OO,PP,QQ,RR,SS,TT,UU,VV,WW,XX,YY,ZZ,
AAA,BBB,CCC,DDD,EEE,FFF,GGG,HHH,III,JJJ,KKK,LLL
}
//大枚举,数量超过64
enum LargeConst{
A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,
AA,BB,CC,DD,EE,FF,GG,HH,II,JJ,KK,LL,MM,NN,OO,PP,QQ,RR,SS,TT,UU,VV,WW,XX,YY,ZZ,
AAAA,BBBB,CCCC,DDDD,EEEE,FFFF,GGGG,HHHH,IIII,JJJJ,KKKK,LLLL,MMMM
}
Const的枚举项数量是64,LagrgeConst的枚举项数量是65,接下来我们希望把这两个枚举转换为EnumSet,然后判断一下它们的class类型是否相同,代码如下:
public class Client89 {
public static void main(String[] args) {
EnumSet<Const> cs = EnumSet.allOf(Const.class);
EnumSet<LargeConst> lcs = EnumSet.allOf(LargeConst.class);
//打印出枚举数量
System.out.println("Const的枚举数量:"+cs.size());
System.out.println("LargeConst的枚举数量:"+lcs.size());
//输出两个EnumSet的class
System.out.println(cs.getClass());
System.out.println(lcs.getClass());
}
}
程序很简单,现在的问题是:cs和lcs的class类型是否相同?应该相同吧,都是EnumSet类的工厂方法allOf生成的EnumSet类,而且JDK API也没有提示EnumSet有子类。我们来看看输出结果:
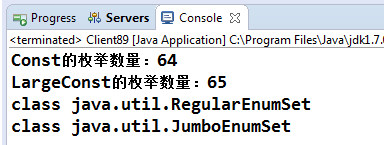
很遗憾,两者不相等。就差一个元素,两者就不相等了?确实如此,这也是我们重点关注枚举项数量的原因。先来看看Java是如何处理的,首先跟踪allOf方法,其源码如下:
public static <E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) {
//生成一个空EnumSet
EnumSet<E> result = noneOf(elementType);
//加入所有的枚举项
result.addAll();
return result;
}
allOf通过noneOf方法首先生成了一个EnumSet对象,然后把所有的枚举都加进去,问题可能就出在EnumSet的生成上了,我们来看看noneOf的源码:
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {
//获得所有的枚举项
Enum[] universe = getUniverse(elementType);
if (universe == null)
throw new ClassCastException(elementType + " not an enum");
//枚举数量小于等于64
if (universe.length <= 64)
return new RegularEnumSet<>(elementType, universe);
else
//枚举数量大于64
return new JumboEnumSet<>(elementType, universe);
}
看到这里,恍然大悟,Java原来是如此处理的:当枚举项数量小于等于64时,创建一个RegularEnumSet实例对象,大于64时则创建一个JumboEnumSet实例对象。
为什么要如此处理呢?这还要看看这两个类之间的差异,首先看RegularEnumSet类,源码如下:
class RegularEnumSet<E extends Enum<E>> extends EnumSet<E> {
private static final long serialVersionUID = 3411599620347842686L;
/**
* Bit vector representation of this set. The 2^k bit indicates the
* presence of universe[k] in this set.
*/
//记录所有的枚举号,注意是long型
private long elements = 0L;
//构造函数
RegularEnumSet(Class<E>elementType, Enum[] universe) {
super(elementType, universe);
}
//加入所有元素
void addAll() {
if (universe.length != 0)
elements = -1L >>> -universe.length;
}
//其它代码略
}
我们知道枚举项的排序值ordinal 是从0、1、2......依次递增的,没有重号,没有跳号,RegularEnumSet就是利用这一点把每个枚举项的ordinal映射到一个long类型的每个位置上的,注意看addAll方法的elements元素,它使用了无符号右移操作,并且操作数是负值,位移也是负值,这表示是负数(符号位是1)的"无符号左移":符号位为0,并补充低位,简单的说,Java把一个不多于64个枚举项映射到了一个long类型变量上。这才是EnumSet处理的重点,其他的size方法、contains方法等都是根据elements方法等都是根据elements计算出来的。想想看,一个long类型的数字包含了所有的枚举项,其效率和性能能肯定是非常优秀的。
我们知道long类型是64位的,所以RegularEnumSet类型也就只能负责枚举项的数量不大于64的枚举(这也是我们以64来举例,而不以128,512举例的原因),大于64则由JumboEnumSet处理,我们看它是怎么处理的:
class JumboEnumSet<E extends Enum<E>> extends EnumSet<E> {
private static final long serialVersionUID = 334349849919042784L;
/**
* Bit vector representation of this set. The ith bit of the jth
* element of this array represents the presence of universe[64*j +i]
* in this set.
*/
//映射所有的枚举项
private long elements[];
// Redundant - maintained for performance
private int size = 0;
JumboEnumSet(Class<E>elementType, Enum[] universe) {
super(elementType, universe);
//默认长度是枚举项数量除以64再加1
elements = new long[(universe.length + 63) >>> 6];
}
void addAll() {
//elements中每个元素表示64个枚举项
for (int i = 0; i < elements.length; i++)
elements[i] = -1;
elements[elements.length - 1] >>>= -universe.length;
size = universe.length;
}
}
JumboEnumSet类把枚举项按照64个元素一组拆分成了多组,每组都映射到一个long类型的数字上,然后该数组再放置到elements数组中,简单来说JumboEnumSet类的原理与RegularEnumSet相似,只是JumboEnumSet使用了long数组容纳更多的枚举项。不过,这样的程序看着会不会觉得郁闷呢?其实这是因为我们在开发中很少使用位移操作。大家可以这样理解:RegularEnumSet是把每个枚举项映射到一个long类型数字的每个位上,JumboEnumSet是先按照64个一组进行拆分,然后每个组再映射到一个long类型数字的每个位上。
从以上的分析可知,EnumSet提供的两个实现都是基本的数字类型操作,其性能肯定比其他的Set类型要好的多,特别是Enum的数量少于64的时候,那简直就是飞一般的速度。
注意:枚举项数量不要超过64,否则建议拆分。
建议90:小心注解继承
Java从1.5版本开始引入注解(Annotation),其目的是在不影响代码语义的情况下增强代码的可读性,并且不改变代码的执行逻辑,对于注解始终有两派争论,正方认为注解有益于数据与代码的耦合,"在有代码的周边集合数据";反方认为注解把代码和数据混淆在一起,增加了代码的易变性,消弱了程序的健壮性和稳定性。这些争论暂且搁置,我们要说的是一个我们不常用的元注解(Meta-Annotation):@Inheruted,它表示一个注解是否可以自动继承,我们开看它如何使用。
思考一个例子,比如描述鸟类,它有颜色、体型、习性等属性,我们以颜色为例,定义一个注解来修饰一下,代码如下:
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target; @Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Inherited
public @interface Desc {
enum Color {
White, Grayish, Yellow
} // 默认颜色是白色的
Color c() default Color.White;
}
该注解Desc前增加了三个注解:Retention表示的是该注解的保留级别,Target表示的是注解可以标注在什么地方,@Inherited表示该注解会被自动继承。注解定义完毕,我们把它标注在类上,代码如下:
@Desc(c = Color.White)
abstract class Bird {
public abstract Color getColor();
} // 麻雀
class Sparrow extends Bird {
private Color color; // 默认是浅灰色
public Sparrow() {
color = Color.Grayish;
} // 构造函数定义鸟的颜色
public Sparrow(Color _color) {
color = _color;
} @Override
public Color getColor() {
return color;
}
} // 鸟巢,工厂方法模式
enum BirdNest {
Sparrow;
// 鸟类繁殖
public Bird reproduce() {
Desc bd = Sparrow.class.getAnnotation(Desc.class);
return bd == null ? new Sparrow() : new Sparrow(bd.c());
}
}
上面程序声明了一个Bird抽象类,并且标注了Desc注解,描述鸟类的颜色是白色,然后编写一个麻雀Sparrow类,它有两个构造函数,一个是默认的构造函数,也就是我们经常看到的麻雀是浅灰色的,另外一个构造函数是自定义麻雀的颜色,之后又定义了一个鸟巢(工厂方法模式),它是专门负责鸟类繁殖的,它的生产方法reproduce会根据实现类注解信息生成不同颜色的麻雀。我们编写一个客户端调用,代码如下:
public static void main(String[] args) {
Bird bird = BirdNest.Sparrow.reproduce();
Color color = bird.getColor();
System.out.println("Bird's color is :" + color);
}
现在问题是这段客户端程序会打印出什么来?因为采用了工厂方法模式,它最主要的问题就是bird变量到底采用了那个构造函数来生成,是无参构造函数还是有参构造?如果我们单独看子类Sparrow,它没有被添加任何注释,那工厂方法中的bd变量就应该是null了,应该调用的是无参构造。是不是如此呢?我们来看运行结果:“Bird‘s Color is White ”;
白色?这是我们添加到父类Bird上的颜色,为什么?这是因为我们在注解上加了@Inherited注解,它表示的意思是我们只要把注解@Desc加到父类Bird上,它的所有子类都会从父类继承@Desc注解,不需要显示声明,这与Java的继承有点不同,若Sparrow类继承了Bird却不用显示声明,只要@Desc注解释可自动继承的即可。
采用@Inherited元注解有利有弊,利的地方是一个注解只要标注到父类,所有的子类都会自动具有父类相同的注解,整齐,统一而且便于管理,弊的地方是单单阅读子类代码,我们无从知道为何逻辑会被改变,因为子类没有显示标注该注解。总体上来说,使用@Inherited元注解弊大于利,特别是一个类的继承层次较深时,如果注解较多,则很难判断出那个注解对子类产生了逻辑劫持。
建议91:枚举和注解结合使用威力更大
我们知道注解的写法和接口很类似,都采用了关键字interface,而且都不能有实现代码,常量定义默认都是public static final 类型的等,它们的主要不同点是:注解要在interface前加上@字符,而且不能继承,不能实现,这经常会给我们的开发带来些障碍。
我们来分析一下ACL(Access Control List,访问控制列表)设计案例,看看如何避免这些障碍,ACL有三个重要元素:
- 资源,有哪些信息是要被控制起来的。
- 权限级别,不同的访问者规划在不同的级别中。
- 控制器(也叫鉴权人),控制不同的级别访问不同的资源。
鉴权人是整个ACL的设计核心,我们从最主要的鉴权人开始,代码如下:
interface Identifier{
//无权访问时的礼貌语
String REFUSE_WORD = "您无权访问";
//鉴权
public boolean identify();
}
这是一个鉴权人接口,定义了一个常量和一个鉴权方法。接下来应该实现该鉴权方法,但问题是我们的权限级别和鉴权方法之间是紧耦合,若分拆成两个类显得有点啰嗦,怎么办?我们可以直接顶一个枚举来实现,代码如下:
enum CommonIdentifier implements Identifier {
// 权限级别
Reader, Author, Admin;
@Override
public boolean identify() {
return false;
}
}
定义了一个通用鉴权者,使用的是枚举类型,并且实现了鉴权者接口。现在就剩下资源定义了,这很容易定义,资源就是我们写的类、方法等,之后再通过配置来决定哪些类、方法允许什么级别的访问,这里的问题是:怎么把资源和权限级别关联起来呢?使用XML配置文件?是个方法,但对我们的示例程序来说显得太繁重了,如果使用注解会更简洁些,不过这需要我们首先定义出权限级别的注解,代码如下:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@interface Access{
//什么级别可以访问,默认是管理员
CommonIdentifier level () default CommonIdentifier.Admin;
}
该注解释标注在类上面的,并且会保留到运行期。我们定义一个资源类,代码如下:
@Access(level=CommonIdentifier.Author)
class Foo{ }
Foo类只能是作者级别的人访问。场景都定义完毕了,那我们看看如何模拟ACL实现,代码如下:
public static void main(String[] args) {
// 初始化商业逻辑
Foo b = new Foo();
// 获取注解
Access access = b.getClass().getAnnotation(Access.class);
// 没有Access注解或者鉴权失败
if (null == access || !access.level().identify()) {
// 没有Access注解或者鉴权失败
System.out.println(access.level().REFUSE_WORD);
}
}
看看这段代码,简单,易读,而且如果我们是通过ClassLoader类来解释该注解的,那会使我们的开发更简洁,所有的开发人员只要增加注解即可解决访问控制问题。注意看加粗代码,access是一个注解类型,我们想使用Identifier接口的identity鉴权方法和REFUSE_WORD常量,但注解释不能集成的,那怎么办?此处,可通过枚举类型CommonIdentifier从中间做一个委派动作(Delegate),委派?你可以然identity返回一个对象,或者在Identifier上直接定义一个常量对象,那就是“赤裸裸” 的委派了。
建议92:注意@Override不同版本的区别
@Override注解用于方法的覆写上,它是在编译器有效,也就是Java编译器在编译时会根据注解检查方法是否真的是覆写,如果不是就报错,拒绝编译。该注解可以很大程度地解决我们的误写问题,比如子类和父类的方法名少写一个字符,或者是数字0和字母O为区分出来等,这基本是每个程序员都曾将犯过的错误。在代码中加上@Override注解基本上可以杜绝出现此类问题,但是@Override有个版本问题,我们来看如下代码:
interface Foo {
public void doSomething();
}
class FooImpl implements Foo{
@Override
public void doSomething() {
}
}
这是一个简单的@Override示例,接口中定义了一个doSomething方法,实现类FooImpl实现此方法,并且在方法前加上了@Override注解。这段代码在Java1.6版本上编译没问题,虽然doSomething方法只是实现了接口的定义,严格来说并不是覆写,但@Override出现在这里可减少代码中出现的错误。
可如果在Java1.5版本上编译此段代码可能会出现错误:
The method doSomeThing() of type FooImpl must override a superclass method
注意,这是个错误,不能继续编译,原因是Java1.5版本的@Override是严格遵守覆写的定义:子类方法与父类方法必须具有相同的方法名、输出参数、输出参数(允许子类缩小)、访问权限(允许子类扩大),父类必须是一个类,不能是接口,否则不能算是覆写。而这在Java1.6就开放了很多,实现接口的方法也可以加上@Override注解了,可以避免粗心大意导致方法名称与接口不一致的情况发生。
在多环境部署应用时,需呀考虑@Override在不同版本下代表的意义,如果是Java1.6版本的程序移植到1.5版本环境中,就需要删除实现接口方法上的@Override注解。
编写高质量代码:改善Java程序的151个建议(第6章:枚举和注解___建议88~92)的更多相关文章
- 博友的 编写高质量代码 改善java程序的151个建议
编写高质量代码 改善java程序的151个建议 http://www.cnblogs.com/selene/category/876189.html
- 编写高质量代码改善java程序的151个建议——导航开篇
2014-05-16 09:08 by Jeff Li 前言 系列文章:[传送门] 下个星期度过这几天的奋战,会抓紧java的进阶学习.听过一句话,大哥说过,你一个月前的代码去看下,慘不忍睹是吧.确实 ...
- 编写高质量代码改善java程序的151个建议——[1-3]基础?亦是基础
原创地址: http://www.cnblogs.com/Alandre/ (泥沙砖瓦浆木匠),需要转载的,保留下! Thanks The reasonable man adapts himse ...
- 编写高质量代码:改善Java程序的151个建议 --[117~128]
编写高质量代码:改善Java程序的151个建议 --[117~128] Thread 不推荐覆写start方法 先看下Thread源码: public synchronized void start( ...
- 编写高质量代码:改善Java程序的151个建议 --[106~117]
编写高质量代码:改善Java程序的151个建议 --[106~117] 动态代理可以使代理模式更加灵活 interface Subject { // 定义一个方法 public void reques ...
- 编写高质量代码:改善Java程序的151个建议 --[78~92]
编写高质量代码:改善Java程序的151个建议 --[78~92] HashMap中的hashCode应避免冲突 多线程使用Vector或HashTable Vector是ArrayList的多线程版 ...
- 编写高质量代码:改善Java程序的151个建议 --[65~78]
编写高质量代码:改善Java程序的151个建议 --[65~78] 原始类型数组不能作为asList的输入参数,否则会引起程序逻辑混乱. public class Client65 { public ...
- 编写高质量代码:改善Java程序的151个建议 --[52~64]
编写高质量代码:改善Java程序的151个建议 --[52~64] 推荐使用String直接量赋值 Java为了避免在一个系统中大量产生String对象(为什么会大量产生,因为String字符串是程序 ...
- 编写高质量代码:改善Java程序的151个建议 --[36~51]
编写高质量代码:改善Java程序的151个建议 --[36~51] 工具类不可实例化 工具类的方法和属性都是静态的,不需要生成实例即可访 问,而且JDK也做了很好的处理,由于不希望被初始化,于是就设置 ...
- Github即将破百万的PDF:编写高质量代码改善JAVA程序的151个建议
在通往"Java技术殿堂"的路上,本书将为你指点迷津!内容全部由Java编码的最佳 实践组成,从语法.程序设计和架构.工具和框架.编码风格和编程思想等五大方面,对 Java程序员遇 ...
随机推荐
- Android中手机录屏并转换GIF的两种方式
之前在博文中为了更好的给大家演示APP的实现效果,本人了解学习了几种给手机录屏的方法,今天就给大家介绍两种我个人用的比较舒服的两种方法: (1)配置adb环境后,使用cmd命令将手机界面操作演示存为视 ...
- 水印第三版 ~ 变态水印(这次用Magick.NET来实现,附需求分析和源码)
技能 汇总:http://www.cnblogs.com/dunitian/p/4822808.html#skill 以前的水印,只是简单走起,用的是原生态的方法.现在各种变态水印,于是就不再用原生态 ...
- 一道返回num值的小题目
题目描述: 实现fizzBuzz函数,参数num与返回值的关系如下: .如果num能同时被3和5整除,返回字符串fizzbuzz .如果num能被3整除,返回字符串fizz .如果num能被5整除,返 ...
- npm 使用小结
本文内容基于 npm 4.0.5 概述 npm (node package manager),即 node 包管理器.这里的 node 包就是指各种 javascript 库. npm 是随同 Nod ...
- GitHub管理代码-随笔
公司一直用的SVN进行项目管理,平时便自己折腾了下Git,这里做下GitHub的最简单的记录... 在git上创建仓库等就免谈了,网上也有好多教程,直接从创建之后记录: 在github的readme文 ...
- Linux 权限设置chmod
Linux中设置权限,一般用chmod命令 1.介绍 权限设置chmod 功能:改变权限命令.常用参数: 1=x(执行权execute) 2=w(写权write) 4=r(读权Read) setuid ...
- Jquery对网页高度、宽度的操作
Jquery获取网页的宽度.高度 网页可见区域宽: document.body.clientWidth 网页可见区域高: document.body.clientHeight 网页可见区域宽: doc ...
- Demo源码放送:打通B/S与C/S !让HTML5 WebSocket与.NET Socket公用同一个服务端!
随着HTML5 WebSocket技术的日益成熟与普及,我们可以借助WebSocket来更加方便地打通BS与CS -- 因为B/S中的WebSocket可以直接连接到C/S的服务端,并进行双向通信.如 ...
- iOS开发系列--网络开发
概览 大部分应用程序都或多或少会牵扯到网络开发,例如说新浪微博.微信等,这些应用本身可能采用iOS开发,但是所有的数据支撑都是基于后台网络服务器的.如今,网络编程越来越普遍,孤立的应用通常是没有生命力 ...
- 探索 Linux 系统的启动过程
引言 之所以想到写这些东西,那是因为我确实想让大家也和我一样,把 Linux 桌面系统打造成真真正正日常使用的工具,而不是安装之后试用几把再删掉.我是真的在日常生活和工作中都使用 Linux,比如在 ...