文本过滤工具之AWK
一、AWK简介
AWK三大文本处理工具之一,是一个非常强大的文本处理工具。它不仅是 Linux 中也是任何环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言(其名称来自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母)的最大功能取决于一个人所拥有的知识。AWK 提供了极其强大的功能:可以进行样式装入、流控制、数学运算符、进程控制语句甚至于内置的变量和函数。它具备了一个完整的语言所应具有的几乎所有精美特性。实际上AWK的确拥有自己的语言:AWK 程序设计语言,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有很多其他的功能;在Linux系统中awk链接到gawk,gawk是awk的GNU版本,它提供了Bell实验室和GNU的一些扩展,下面我们介绍的awk就是以GNU的gawk为例来讲解
二、AWK工作原理
在Linux系统中,"/etc/passwd"是一个非常典型的格式化文件,各字段之间用":"作为分隔符隔开,Linux系统中的大部分日志文件也是格式化的文件,处理这些文件从中提取相关信息是管理员的日常工作之一,有了AWK工具的帮助便使得这些工作变得很轻松
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@localhost ~]# cat /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologinadm:x:3:4:adm:/var/adm:/sbin/nologinlp:x:4:7:lp:/var/spool/lpd:/sbin/nologinsync:x:5:0:sync:/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdownhalt:x:7:0:halt:/sbin:/sbin/haltmail:x:8:12:mail:/var/spool/mail:/sbin/nologin... ... ... |
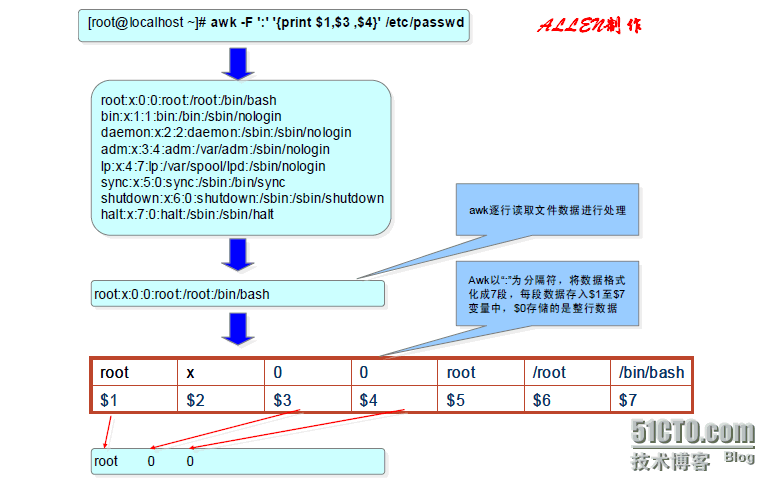
若需要查找并打印出"/etc/passwd"的用户名,用户ID及组ID,使用下面的awk命令即可完成:
|
1
|
[root@localhost ~]# awk -F: '{print $1,$3,$4}' /etc/passwd |
awk从文件或者标准输入读取信息,与sed一样信息的读取也是逐行读取的,处理过程与sed类似,不同的是awk将文本文件中的一行视为一个记录,而将一行中的某一部分作为记录中的一个字段。为了操作这些不同的字段,awk借用了shell的方法,用"$1,$2,$3..."这样的方式来顺序地表示行(记录)中的不同的字段。特殊地awk用"$0"表示整个行(记录)。不同的字段之间是用称作分隔符的字符来分隔开来的。系统默认的分隔符是空格,awk允许在命令中使用"[-F 分隔符]"的形式指定特定分隔符
在上述示例中,awk命令对"/etc/passwd"的处理过程如下图:
三、AWK的调用方式
AWK有三种调用方式如下:
1、命令行键入方式,也是最常用的一种方式,命令格式为:
|
1
2
|
awk [-F 分隔符] awk指令 输入文件shell 命令 | awk [-F 分隔符] awk指令 |
其中"[-F 分隔符]"为可选,awk使用空格作为缺省的分隔符,因此如果要查看有空格的文件,不用指定这个选项,但如果要查看如"/etc/passwd"就需要使用"-F"选项指定以":"为分隔符了。
awk指令由pattern(模式)和action(动作)或是两者的组合组成,常见的形式为"'/pattern/{action}",awk指令必须使用单引号;pattern是正则表达式、判断条件真假的表达式或两者的组合,多个pattern间使用","分隔;action是awk所要采取的动作,由awk语句组成,多个awk语句使用“;”分隔
2、编写awk运行脚本
是将所有awk命令插入一个文件,并使用awk程序执行,然后用awk命令解释器作为脚本的首行,通过键入脚本脚本名称来调用
3、将所有的awk命令插入一个单独文件,然后调用:
|
1
|
awk -f awk-script-file 输入文件 |
注: -f:指定写有awk命令的文件名 "输入文件":需要使用awk进行处理的文件名
用法格式
|
1
2
|
awk [options] 'script' file1 file2, ...awk [options] 'PATTERN { action }' file1 file2, ... |
options:
-F fs|--field-separator=fs:指定文件分隔符
-v var=val|--assign=var=val:赋值一个用户定义变量
-f scripfile|--file scriptfile:从脚本文件中读取awk命令
-W compact|--compat:在兼容模式下运行awk
四、print在AWK中的使用
使用"/etc/passwd"文件做测试:
示例: 打印出整行
|
1
2
3
4
5
|
[root@localhost ~]# awk '{print $0}' /etc/passwdroot:x:0:0:root:/root:/bin/bashbin:x:1:1:bin:/bin:/sbin/nologindaemon:x:2:2:daemon:/sbin:/sbin/nologin... ... ... |
示例:打印出"/etc/passwd"文件中以"/bash"结尾的行
|
1
2
3
4
|
[root@localhost ~]# awk '/bash/' /etc/passwdroot:x:0:0:root:/root:/bin/bashmockbuild:x:500:500::/home/mockbuild:/bin/bashmysql:x:498:498::/home/mysql:/bin/bash |
示例:查找"/etc/passwd"文件中包含"nologin"的行,以":"为分隔符并打印出第一个与第三个字段
|
1
2
3
4
|
[root@localhost ~]# awk -F: '/nologin/{print $1,$3}' /etc/passwd | head -3bin 1daemon 2adm 3 |
示例:打印每一行的最后一个字段
|
1
2
3
4
5
|
[root@localhost ~]# awk -F: '{print $NF}' /etc/passwd/bin/bash/sbin/nologin/sbin/nologin... ... ... |
示例:打印出每行的倒数第二个字段,并在后面打印ALLEN
|
1
2
3
4
5
|
[root@localhost ~]# awk -F: '{print $(NF-1),"ALLEN"}' /etc/passwd/root ALLEN/bin ALLEN/sbin ALLEN... ... ... |
示例:打印出每一行的行号
|
1
2
3
4
5
|
[root@localhost ~]# awk '{print NR,$0}' /etc/passwd1 root:x:0:0:root:/root:/bin/bash2 bin:x:1:1:bin:/bin:/sbin/nologin3 daemon:x:2:2:daemon:/sbin:/sbin/nologin... ... ... |
示例:打印当前系统环境变量"PATH"
|
1
2
|
[root@localhost ~]# awk 'BEGIN{print ENVIRON["PATH"];}'/usr/local/apache/bin:/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin:/root/bin |
示例:修改打印输出符号,特殊字符需要转义
|
1
2
3
4
5
6
7
8
9
|
[root@localhost ~]# awk -F: -v OFS=. '{print $1,$NF}' /etc/passwd | head -2root./bin/bashbin./sbin/nologin[root@localhost ~]# awk -F: -v OFS=\<\> '{print $1,$NF}' /etc/passwd | head -2root<>/bin/bashbin<>/sbin/nologin[root@localhost ~]# awk -F: -v OFS=- '{print $1,$NF}' /etc/passwd | head -2root-/bin/bashbin-/sbin/nologin |
AWK变量:
AWK默认有很多变量,如前面所用的"$1-$n"、$0、OFS、NF等,如下:
| 变量 | 注释 |
| $n | 当前记录的第n个字段,字段间由FS分隔。 |
| $0 | 完整的输入记录。 |
| ARGC | 命令行参数的数目。 |
| ARGIND | 命令行中当前文件的位置(从0开始算)。 |
| ARGV | 包含命令行参数的数组。 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组。 |
| ERRNO | 最后一个系统错误的描述。 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔)。 |
| FILENAME | 当前文件名。 |
| FNR | 同NR,但相对于当前文件。 |
| FS | 字段分隔符(默认是任何空格)。 |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配。 |
| NF | 当前记录中的字段数。 |
| NR | 当前记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g)。 |
| OFS | 输出字段分隔符(默认值是一个空格)。 |
| ORS | 输出记录分隔符(默认值是一个换行符)。 |
| RLENGTH | 由match函数所匹配的字符串的长度。 |
| RS | 记录分隔符(默认是一个换行符)。 |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是\034) |
五、printf在awk中的使用
命令格式: printf format1,format2..., item1,item2...
printf与print的不同之处是不会自动换行,而且还需要对每个字体做格式化输出,当然命令本身还多了个f
|
1
2
3
4
|
修饰符:-: 左对齐+: 显示数值符号N: 显示宽度 |
| 格式化符 | 注释 |
|---|---|
| %d | %i 十进制有符号整数 |
| $f | 浮点数 |
| %s | 字符串 |
| %u | 十进制无符号整数 |
| %e | %E 科学计数法显示数值 |
| %x | %X 无符号以十六进制表示的整数 |
| %g | %G 以tuip科学计数法或浮点数的格式显示数值 |
| %c | 显示字符的ASCII码 |
| %o | 无符号以八进制表示的整数 |
| %p | 指针的值 |
| %% | 显示%自身 |
示例:左对齐与右对齐分别测试打印出"/etc/passwd"文件中的第一个字段与最后一个字段
|
1
2
3
4
5
6
7
8
|
[root@localhost ~]# awk -F: '{printf "%15s %15s\n",$1,$NF}' /etc/passwd | head -3 root /bin/bash bin /sbin/nologin daemon /sbin/nologin[root@localhost ~]# awk -F: '{printf "%-15s %15s\n",$1,$NF}' /etc/passwd | head -3root /bin/bashbin /sbin/nologindaemon /sbin/nologin |
示例:以指定的格式输入"/etc/passwd"文件中的内容
|
1
2
3
4
|
[root@localhost ~]# awk -F: '{printf "%-15s~%10s ~%15s\n",$1,$3,$4}' /etc/passwd | head -3root ~ 0 ~ 0bin ~ 1 ~ 1daemon ~ 2 ~ 2 |
输出重定向:
|
1
2
3
|
print items > output-fileprint items >> output-fileprint items | command |
特殊文件描述符:
|
1
2
3
4
|
/dev/stdin:标准输入/dev/sdtout: 标准输出/dev/stderr: 错误输出/dev/fd/N: 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0; |
示例:下面两种用法效果是一样的:
|
1
2
|
[root@localhost ~]# awk -F: '{printf "%-15s %i\n",$1,$3,$NF > "/root/printf" }' /etc/passwd[root@localhost ~]# awk -F: '{printf "%-15s %i\n",$1,$3,$NF}' /etc/passwd > /tmp/printf |
六、AWK的操作符
1、算术操作符
|
1
2
3
4
5
6
7
8
9
10
|
操作符 描述-x 负值+x 转换为数值x^y 次方x**y 次方x*y 乘法x/y 除法x+y 加法x-y 减法x%y 取余 |
2、字符串操作符
只有一个,而且不用写出来,用于实现字符串连接
示例:
|
1
2
3
4
5
6
|
[root@localhost ~]# awk '{print $1 $2}' printf | head -2root0bin1[root@localhost ~]# awk '{print $1$2}' printf | head -2root0bin1 |
3、赋值操作符
|
1
2
3
4
5
6
7
8
9
10
|
操作符 描述= 赋值操作符+= 赋值加操作符-= 赋值减操作符*= 赋值乘操作符/= 赋值除操作符%= 赋值求余操作符^= 赋值求幂操作符**= 赋值求幂操作符注:如果某模式为=号,此时使用/=/可能会有语法错误,应以/[=]/替代 |
4、布尔值
awk中,任何非0值或非空字符串都为真,反之就为假
5、比较操作符
|
1
2
3
4
5
6
7
8
9
|
操作符 描述> 大于< 小于>= 大于等于<= 小于等于== 等于!= 不等于~ 匹配!~ 匹配取反 |
6、表达式之间的逻辑关系符
|
1
2
|
&& : 逻辑与|| : 逻辑或 |
示例:打印"/etc/passwd"文件中用户uid小于100且以"r"开头的行的用户名及UID
|
1
2
|
[root@localhost ~]# awk -F: '$3<=100 && $1 $3 ~ /^r/{printf "%-5s %5s\n",$1,$3}' /etc/passwdroot 0 |
示例:打印"/etc/passwd"文件中用户UID大于等于500或以"m"开头的行
|
1
2
3
4
|
[root@localhost ~]# awk -F: '$3>=500 || $1 $3 ~ /^m/{printf "%-5s %5s\n",$1,$3}' /etc/passwdmail 8mockbuild 500mysql 498 |
7、条件表达式
|
1
2
3
4
5
6
|
selector?if-true-exp:if-false-expif selector; then if-true-expelse if-false-expfi |
示例:在变量值中查找判断
|
1
2
|
[root@localhost ~]# awk 'BEGIN{Name="welcome to china";print index(Name,"china")?"OK":"NO";}'OK |
8、函数调用
|
1
|
function_name (para1,para2) |
上面所介绍的内容将在下面做示例介绍
七、AWK的模式
模式可以是表达式与正则表达式,还支持取反与模糊匹配等,如下:
|
1
2
3
4
5
6
|
常见的模式类型Regexp: 正则表达式,格式为/regular expression/expresssion: 表达式,其值非0或为非空字符时满足条件,如:$1 ~ /foo/ 或 $1 == "allen",用运算符~(匹配)和!~(不匹配)Ranges: 指定的匹配范围,格式为pat1,pat2BEGIN/END:特殊模式,仅在awk命令执行前运行一次或结束前运行一次Empty(空模式):匹配任意输入行 |
模式可以是以下任意一个:
/正则表达式/:使用通配符的扩展集。
关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>%1选择第二个字段比第一个字段长的行。
模式匹配表达式:
模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
操作:
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号分隔,并位于花括号内,主要有四个部分:变量或数组赋值、输出命令、内置函数、控制流命令
示例:打印"/etc/passwd"文件中以"bash"结尾和非"bash"结尾的行
|
1
2
3
4
5
6
7
8
|
[root@localhost ~]# awk -F: '/bash$/{print $1,$3,$NF}' /etc/passwdroot 0 /bin/bashmockbuild 500 /bin/bashmysql 498 /bin/bash[root@localhost ~]# awk -F: '!/bash$/{print $1,$3,$NF}' /etc/passwd | head -3bin 1 /sbin/nologindaemon 2 /sbin/nologinadm 3 /sbin/nologin |
示例:打印UID包含1的用户名及UID等于1的用户名及UID
|
1
2
3
4
5
6
|
[root@localhost ~]# awk -F: '$3~1{print $1,$3}' /etc/passwd | head -3bin 1uucp 10operator 11[root@localhost ~]# awk -F: '$3==1{print $1,$3}' /etc/passwd | head -3bin 1 |
其实除了用到过的表达式外还有ranges、BEGIN等,还可以使用以范围匹配等
示例:打印"/etc/passwd"文件中以bin开头到adm开头中所有用户的用户名及UID与Shell
|
1
2
3
4
|
[root@localhost ~]# awk -F: '/^bin/,/^adm/{print $1,$3,$NF}' /etc/passwdbin 1 /sbin/nologindaemon 2 /sbin/nologinadm 3 /sbin/nologin |
示例:打印输入结果添加注释与结束符
|
1
2
3
4
5
6
7
|
[root@localhost ~]# awk -F: 'BEGIN{print "UserName:UID"}{print $1,"\t",$3}END{print "===END==="}' /etc/passwdUserName:UIDroot 0bin 1... ... ...mysql 498===END=== |
示例:打印用户名以d开头的,并显示其UID,要有注释信息
|
1
2
3
4
5
|
[root@localhost ~]# awk -F: 'BEGIN{print "UserName:UID"}$1 ~ /^d/{printf "%-10s%s\n",$1,$3}END{print "===END==="}' /etc/passwdUserName:UIDdaemon 2dbus 81===END=== |
示例:统计以shell为"bash"的总用户数
|
1
2
|
[root@localhost ~]# awk -F: 'BEGIN{sum=0}$NF ~ /bash$/{count++}END{print "SHELL is Bash:",count}' /etc/passwdSHELL is Bash: 3 |
示例:使用BEGIN可以直接显示字符也可以为字段指定分隔符
|
1
2
3
4
5
6
7
|
[root@localhost ~]# awk 'BEGIN{print "All""en"}'Allen[root@localhost ~]# awk -v OFS=- 'BEGIN{print "All","en"}'All-en[root@localhost ~]# awk 'BEGIN{FS=":"}{print $1,$3}' /etc/passwd | head -2root 0bin 1 |
示例:打印系统用户和普通用户并输出
|
1
2
3
4
5
6
7
8
9
10
|
[root@localhost ~]# awk -F: '{if ($3<500)print $1,"System User";else print $1 "Common User"}' /etc/passwdroot System User... ... ...mockbuild Common Usermysql System User[root@localhost ~]# awk -F: '{if ($3==0)print $1,"Admin User";else if($3>0 && $3<500){print $1 " System User"}}' /etc/passwdroot Admin Userbin System Userdaemon System User... ... ... |
示例:打印每行的奇数与偶数字段
|
1
2
3
4
|
[root@localhost ~]# awk -F: '{i=1;while(i<=NF){print $i;i+=2}}' /etc/passwd #奇[root@localhost ~]# awk -F: '{i=2;while(i<=NF){print $i;i+=2}}' /etc/passwd #偶[root@localhost ~]# awk -F: '{for(i=1;i<NF;i+=2)print $i}' /etc/passwd #奇[root@localhost ~]# awk -F: '{for(i=2;i<NF;i+=2)print $i}' /etc/passwd #偶 |
示例:显示ID为奇数的用户
|
1
|
awk -F: '{if($3%2==0) next;print $1,$3}' /etc/passwd |
数组:
示例:数组引用,下标可以是字符串但需要双引号,数字不需要
|
1
2
|
[root@localhost ~]# awk 'BEGIN{A[1]="hello";B[2]="world";print A[1],B[2]}'[root@localhost ~]# awk 'BEGIN{A["a"]="hello";B["b"]="world";print A["a"],B["b"]}' |
示例:被/^tcp/模式匹配到的行,数组S[$NF]就加1,NF为当前匹配到的行的最后一个字段,此处用其值做为数组S的元素索引
|
1
|
[root@localhost ~]# netstat -ant | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' |
示例:统计每个shell用户的数量
|
1
|
awk -F: '$NF!~/^$/{BASH[$NF]++}END{for(A in BASH){printf "%15s:%i\n",A,BASH[A]}}' /etc/passwd |
示例:计算100以内的加法
|
1
2
|
awk 'BEGIN{res=0;i=0;do{res+=i;i++;}while(i<=100)print res;}'awk 'BEGIN{while(i<=100){res+=i;i++;}print res;}' |
示例:统计日志IP的访问次数,最多的前6个
|
1
|
awk '{IP[$1]++}END{for(A in IP)print IP[A],A}' access_log|sort -rn|head -6 |
AWK内置函数:
split(string, array [, fieldsep [, seps ] ])
功能:将string表示的字符串以fieldsep为分隔符进行分隔,并将分隔后的结果保存至array为名的数组中;数组下标为从1开始的序列;
|
1
|
netstat -ant | awk '/:80\>/{split($5,clients,":");IP[clients[1]]++}END{for(i in IP){print IP[i],i}}' | sort -rn | head -50 |
length([string])
功能:返回string字符串中字符的个数;
substr(string, start [, length])
功能:取string字符串中的子串,从start开始,取length个;start从1开始计数;
system(command)
功能:执行系统command并将结果返回至awk命令
systime()
功能:取系统当前时间
tolower(s)
功能:将s中的所有字母转为小写
toupper(s)
功能:将s中的所有字母转为大写
示例:读取100以内随机数
|
1
|
awk 'BEGIN{srand();fr=int(100*rand());print fr;}' |
示例:正则表达式,match函数的使用
|
1
2
3
4
|
[root@localhost ~]# awk 'BEGIN{res="welcome to china!";print match(res,/[0-9]+/)?"ok":"no";}'no[root@localhost ~]# awk 'BEGIN{res="welcome to 123 china!";print match(res,/[0-9]+/)?"ok":"no";}'ok |
示例:截取字符串,从第12个字符向后截取5个字符长度
|
1
2
|
[root@localhost ~]# awk 'BEGIN{info="welcome to china!";print substr(info,12,5);}'china |
示例:显示/etc/passwd中的前三个字段
|
1
2
|
[root@localhost ~]# awk -F: '{for(i=1;i<=3;i++) print $i}' /etc/passwd[root@localhost ~]# awk -F: '{for(i=1;i<=NF;i++) { if (length($i)>=4) {print $i}}}' /etc/passwd |
示例:调用外部命令执行,显示磁盘使用信息
|
1
2
3
4
5
6
7
8
9
|
[root@localhost ~]# awk 'BEGIN{disk=system("df -h");print disk;}'文件系统 容量 已用 可用 已用%% 挂载点/dev/mapper/VolGroup-lv_root 50G 12G 36G 24% /tmpfs 194M 0 194M 0% /dev/shm/dev/sda1 485M 45M 416M 10% /boot/dev/mapper/VolGroup-lv_home 67G 180M 63G 1% /home0 |
示例:时间函数strftime、systime的使用
|
1
2
3
4
5
6
|
[root@localhost ~]# awk 'BEGIN{Tim=mktime("2013 09 04 13 06 26");print strftime("%c",Tim);}'2013年09月04日 星期三 13时06分26秒[root@localhost ~]# date2013年 09月 04日 星期三 14:09:35 CST[root@localhost ~]# awk 'BEGIN{Time=mktime("2013 09 04 13 06 26");Time1=systime();print Time1-Time;}'3791 |
到此,以上内容为简写,如果都能理解并灵活使用那就最好了,这也是最基本的使用,如果想熟练使用并不是一天两天能搞定的,一起学习吧!!!
文本过滤工具之AWK的更多相关文章
- 工具: ass109.awk 分析 Oracle 的跟踪文件
原文链接:http://www.eygle.com/archives/2009/11/awk_ass109.html 以前分析Oracle的跟踪文件,主要靠手工阅读,最近发现ass109.awk文件是 ...
- Unix文本处理工具之awk
Unix命令行下输入的命令是文本,输出也都是文本.因此,掌握Unix文本处理工具是很重要的一种能力.awk是Unix常用的文本处理工具中的一种,它是以其发明者(Aho,Weinberger和Kerni ...
- Linux Shell 文本处理工具集锦--Awk―sed―cut(row-based, column-based),find、grep、xargs、sort、uniq、tr、cut、paste、wc
本文将介绍Linux下使用Shell处理文本时最常用的工具:find.grep.xargs.sort.uniq.tr.cut.paste.wc.sed.awk:提供的例子和参数都是最常用和最为实用的: ...
- 工具之awk
转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858470.html awk是一个强大的文本分析工具,相对于grep的查找,sed的编 ...
- awk、sed、grep三大shell文本处理工具之awk的应用
awk 1.是什么 是一个编程语言.支持变量.数组.函数.流程控制(if...else/for/while) 单行程序语言. 2.工作流程 读取file.标准输入.管道给的数据,从第一行开始读取,逐行 ...
- AWK文本处理工具(Linux)
AWK文本处理工具(Linux) PS:刚开始实习,就给了个处理百万级别数据的任务,以前学过SHELL的一些东西sed/awk之类的处理,但是也没有具体的应用,只是在10几行10几列的小数据操作过,所 ...
- shell脚本 awk工具
awk工具概述awk编程语言/数据处理引擎基于模式匹配检查输入文本,逐行处理并输出通常在shell脚本中,或取指定的数据单独用时,可对文本数据做统计 命令格式格式一:awk [选项] '[条件]{编辑 ...
- 【转载】GAWK AWK工具使用手册
IBM GAWK入门资料http://www.ibm.com/developerworks/cn/education/aix/au-gawk/ AWK 是什么? 最简单地说,AWK 是一种用于处理文本 ...
- Linux shell文本过滤
正则表达式 --概念:一种用来描述文本模式的特殊语法 --由普通字符(例如:字符a到z),以及特殊字符(元字符,如/*?等)组成匹配的字符串 --文本过滤工具在某种模式之下,都支持正则表达式 --基本 ...
随机推荐
- ubuntu14.04 Hadoop单机开发环境搭建MapReduce项目
Hadoop官网:http://hadoop.apache.org/ 目前最新的版本是Hadoop 3.0.0-alpha1前提:java 1.6 版本以上 首先从官网下载压缩包(hadoop-3.0 ...
- String or binary data would be truncated 解决办法
原因: 一般出现这个问题是因为数据库中的某个字段的长度小,而插入数据大 解决: 找到相应字段,修改表结构,使表字段大小相同或大于要插入的数据
- spring框架学习(五)注解
注解Annotation,是一种类似注释的机制,在代码中添加注解可以在之后某时间使用这些信息.跟注释不同的是,注释是给我们看的,Java虚拟机不会编译,注解也是不编译的,但是我们可以通过反射机制去读取 ...
- vue 2.0
vue2.0 据说也出了很久了,博主终于操了一次实刀. 整体项目采用 vue + vue-router + vuex (传说中的vue 全家桶 ),构建工具使用尤大大推出的vue-cli 项目是 ...
- Unity3d调用iOS陀螺仪
How to write gyroscope controller with Unity3d http://blog.heyworks.com/how-to-write-gyroscope-contr ...
- 用原生js获取class
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- node.js的优缺点
node.js的优缺点 优点: 1. 采用事件驱动,异步编程,为网络服务而设计. 2. node.js非阻塞模式的IO处理给node.js带来在相对较低的资源耗用下的高性能与出众的负载能力. 3. n ...
- 268. Missing Number -- 找出0-n中缺失的一个数
Given an array containing n distinct numbers taken from 0, 1, 2, ..., n, find the one that is missin ...
- TransactionScope oracle不能用的问题(转载)
报错:“无法加载oramts.dll ”的错误 参见文章:关于TransactionScope分布式事务在Oracle下的运作
- WebAPI返回数据类型解惑
本文来自:http://www.cnblogs.com/lzrabbit/archive/2013/03/19/2948522.html 最近开始使用WebAPI,上手很容易,然后有些疑惑 1.Web ...