第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
我们自定义一个main.py来作为启动文件
main.py
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法
import sys
import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'pach', '--nolog']) #执行scrapy命令
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
import urllib.response
from lxml import etree
import re class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
pass
xpath表达式
1、
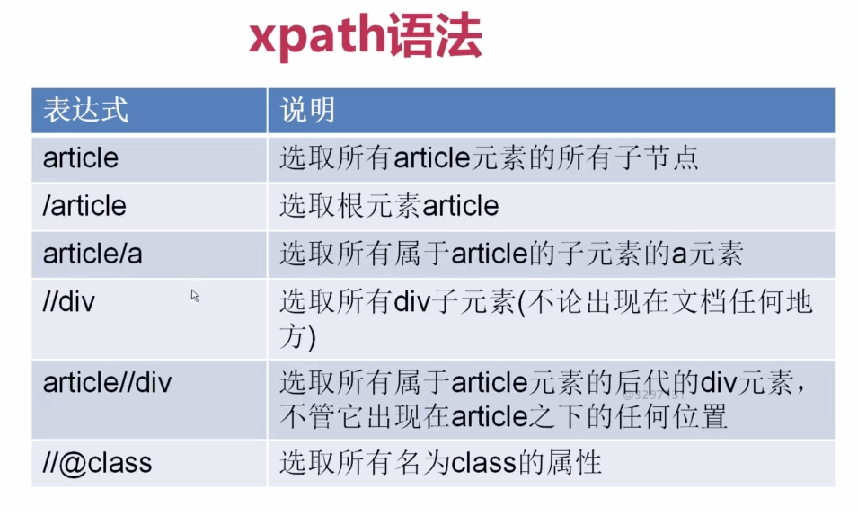
2、
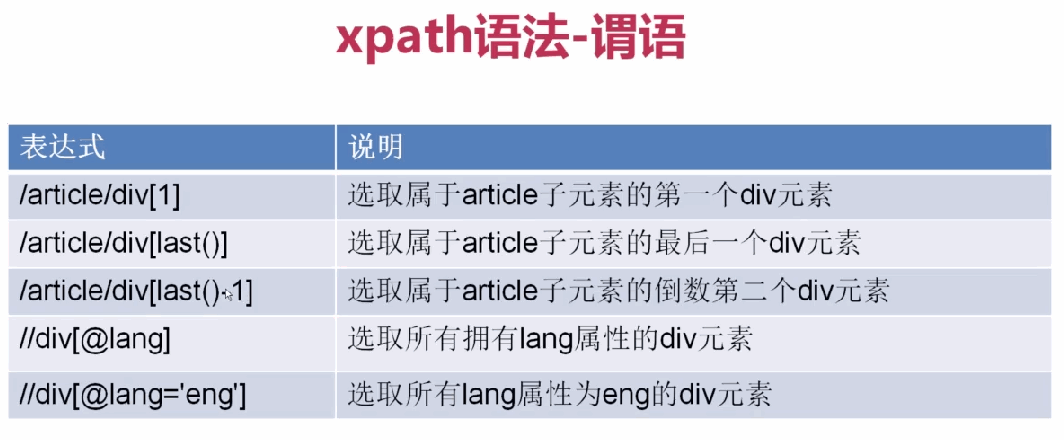
3、

基本使用
allowed_domains设置爬虫起始域名
start_urls设置爬虫起始url地址
parse(response)默认爬虫回调函数,response返回的是爬虫获取到的html信息对象,里面封装了一些关于htnl信息的方法和属性
responsehtml信息对象下的方法和属性
response.url获取抓取的rul
response.body获取网页内容
response.body_as_unicode()获取网站内容unicode编码
xpath()方法,用xpath表达式过滤节点
extract()方法,获取过滤后的数据,返回列表
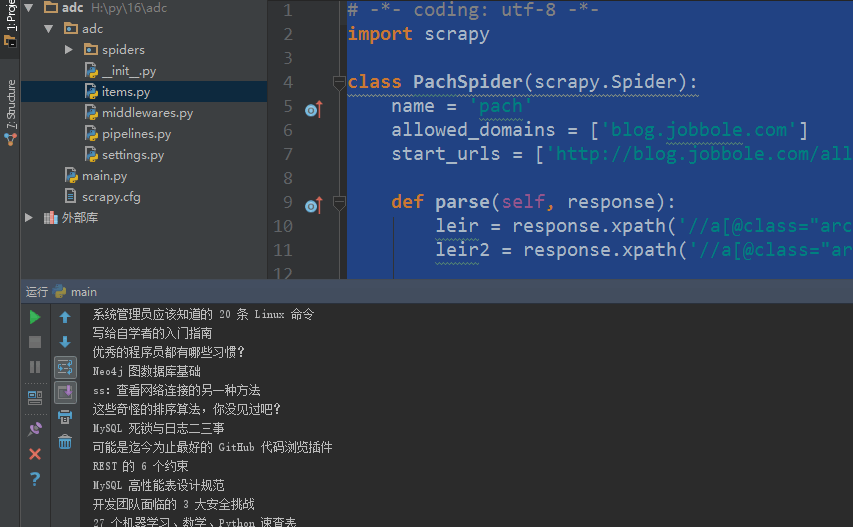
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response):
leir = response.xpath('//a[@class="archive-title"]/text()').extract() #获取指定标题
leir2 = response.xpath('//a[@class="archive-title"]/@href ').extract() #获取指定url print(response.url) #获取抓取的rul
print(response.body) #获取网页内容
print(response.body_as_unicode()) #获取网站内容unicode编码 for i in leir:
print(i)
for i in leir2:
print(i)
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式的更多相关文章
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装
第三百七十九节,Django+Xadmin打造上线标准的在线教育平台—xadmin的安装 xadmin介绍 xadmin是基于Django的admin开发的更完善的后台管理系统,页面基于Bootstr ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页
第三百八十九节,Django+Xadmin打造上线标准的在线教育平台—列表筛选结合分页 根据用户的筛选条件来结合分页 实现原理就是,当用户点击一个筛选条件时,通过get请求方式传参将筛选的id或者值, ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
随机推荐
- Fluent UDF【2】:学习途径
要怎样做才能做到无畏惧编写任何UDF程序?估计很多与UDF打交道的人都会问到这个问题. 面对UDF文档中那众多的宏描述,小伙伴们是不是感觉到茫然无措,不知从何入手.有时候读别人写好的程序感觉并不难,然 ...
- python(45)内置函数:os.system() 和 os.popen()
os.system() 和 os.popen() 概述 os.popen() 方法用于从一个命令打开一个管道. 在Unix,Windows中有效 语法 popen()方法语法格式如下: os.pope ...
- 如何优雅的退出/关闭/重启gunicorn进程
在工作中,会发现gunicorn启动的web服务,无论怎么使用kill -9 进程号都是无法杀死gunicorn,经过我一番百度和谷歌,发现想要删除gunicorn进程其实很简单. 1. 寻找mast ...
- 【web技术】html特效代码(二)
html特效代码(一) html特效代码(二) 图片漂浮广告代码 <bodybgcolor="#F7F7F7"> <!--图片漂浮广告代码开始--> < ...
- ubuntu mysql 远程连接问题解决方法
在shell下输入mysql -uroot -p是可以登录的,所以问题应该是mysql不允许root用户远程登录的问题,于是通过输入下面命令: GRANT ALL PRIVILEGES ON *.* ...
- 关于electron的跨域问题,有本地的图片的地址,访问不了本地的图片
项目中有上传图片功能,自定义input type=file 改变透明度和超出部分隐藏,把按钮和 点击的图标放在上传文件的按钮上面,然后又碰到到获取input里面的图片的本地的路径, 在electron ...
- FIDDLER的使用方法及技巧总结(连载三)FIDDLER使用技巧及方法
(接上篇!~~~~) 三.FIDDLER使用技巧及方法 1.AutoResponder选项卡的使用 Fiddler的AutoResponder 选项卡允许你使用本地硬盘的文件来作为返回内容,而不是把请 ...
- 如何在一张ppt中插入多张图片并能依次播放
我们在做ppt的过程中,有时遇到在一张ppt中插入多张图片还想让其能依次播放的情况,针对上述情况我们可以根据下列步骤进行设置.(新手必看) 1.首先,用鼠标点击桌面Microsoft PowerPo ...
- django源码解析之 BooleanField (三)
def __init__(self, *args, **kwargs): kwargs['blank'] = True if 'default' not in kwargs and not kwarg ...
- 算法篇---Shell排序(希尔)算法
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组.所有距离为dl的倍数的记录放在同一个组中.先在各组内进行直接插入排序:然后,取第二个增量d2<d1重复上述的分组和排序,直至 ...