Deep Residual Learning for Image Recognition这篇文章
作者:何凯明等,来自微软亚洲研究院;
这篇文章为CVPR的最佳论文奖;(conference on computer vision and pattern recognition)
在神经网络中,常遇到的问题:
1. 当网络变深以后的 vanishing/exploding gradient 问题: 对于这一个问题,现在可以说差不多已经有解决的办法了,如:使用 ReLU激活函数、 良好的权值初始化方法 、还有 intermediate normalization layers(即网络中间的batch normalization);
2. 对于网络过程中的过拟合问题: 解决办法如使用很不错的regularization, 如:权值衰减、dropout方法、maxout(这个?)
3. 现在通过看这篇论文注意到了一个以前没有注意到的问题:
当随着网络的层数深以后,出现一个问题: 网络的训练error与验证error 会变大,比shallow的效果差 (并且这个问题不是由于梯度消失或爆炸问题引起的,而是更深层的优化问题)。。这个现象在很多论文中也已经证明了这一问题; 用文中的图表示:
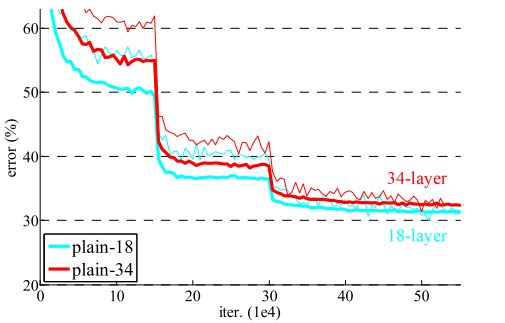
(左图中可以看出,34层的无论是train error[细线] 还是 validation error[粗线] 是比 18层的大, 右图同样的现像)
本文的提出的方法就是解决算是解决了这一问题了,甚至把网络的层数加到了152层; 甚至1202层; 使用文中的网络结构得到的误差曲线:(与上面的图分别作比较)
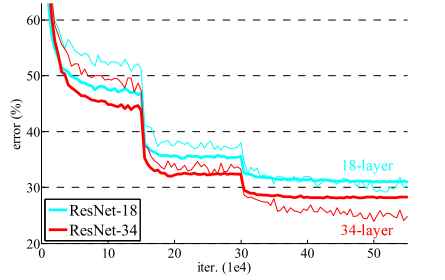
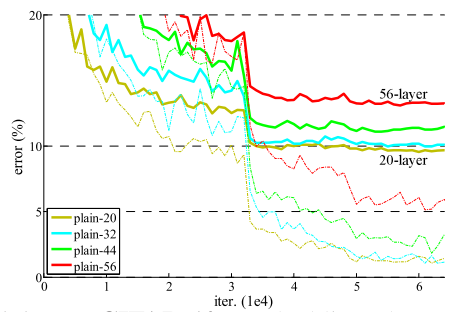
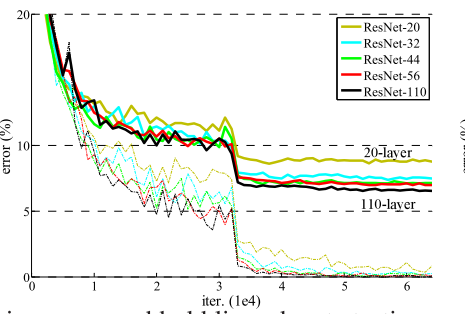
本文采用的什么方法呢?
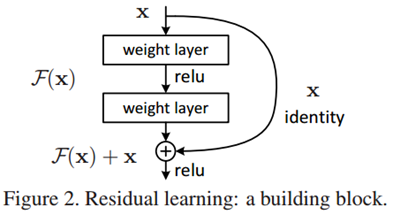
使用了 residual learning 方法; 用一个图表示就是:
假如原始网络想学习一个F(X) + X 的mapping, 现在通过 shortcut connection ,使网络变成学习F(X)就可以了; 用文中的话:
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers。
想想是这么个道理,但是呢,我的疑问是::谁能确定怎么知道网络学习得到的mapping, 一定是需要加上X的呢?? 这个会不会限制了网络的representation呢?
一些细节:1. 对于Fx 与X 的dimension不相同是怎么办啦,文中两个方法:要么用0补齐,要么 Linear projection;
2. 文中说了一个 deeper bottleneck 的结构; 文中作用它的目的应该是可以加深网络的结构同时保持或减少着网络的参数; 但是当我看到这里的时候有一个疑问:这个难道不影响网络的representation吗?因为看论文Rethinking the inception architecture for computer vision中提到应该避免 bottleneck啊(原话:Avoid representational bottlenecks, especially early in the network.)
更重要的是:
已经很容易了解了这个网络的具体的implementation, 如何去窥探其内部的本质问题呢? 我现在想的是 为residual learning 就可以呢??需要看看 residual reprentation的相关知识,引用文中的话:
上面这两段,我不了解,因为以前没有接触过这方面的知识,所以呢,更需要知道 residual representation 如何啊? 所以,下一步,深入数字内部,看一下details;

通过文章,学习到了一个shortcut connection;还是随着网络的加深,网络的性能不下降,并且这个原因不是由于梯度消失或爆炸引起的,而是由于深层网络的本质的难以训练的原因;
文中其它的部分,关乎的具体的实验设置、过程也实验结果的分析;不多说明;
参考:He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
Deep Residual Learning for Image Recognition这篇文章的更多相关文章
- 论文笔记——Deep Residual Learning for Image Recognition
论文地址:Deep Residual Learning for Image Recognition ResNet--MSRA何凯明团队的Residual Networks,在2015年ImageNet ...
- [论文理解]Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition 简介 这是何大佬的一篇非常经典的神经网络的论文,也就是大名鼎鼎的ResNet残差网络,论文主要通过构建了一种新 ...
- Deep Residual Learning for Image Recognition (ResNet)
目录 主要内容 代码 He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]. computer vi ...
- [论文阅读] Deep Residual Learning for Image Recognition(ResNet)
ResNet网络,本文获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名. 本篇文章解决了深度神经网络中产生的退化问题(degradation problem). ...
- Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun Microsoft Research {kahe, v-xiangz, v-sh ...
- Deep Residual Learning for Image Recognition论文笔记
Abstract We present a residual learning framework to ease the training of networks that are substant ...
- Deep Residual Learning for Image Recognition(MSRA-深度残差学习)
转自:http://blog.csdn.net/solomonlangrui/article/details/52455638 ABSTRACT: 神经网络的训练因其层次加深而 ...
- Deep Residual Learning for Image Recognition(残差网络)
深度在神经网络中有及其重要的作用,但越深的网络越难训练. 随着深度的增加,从训练一开始,梯度消失或梯度爆炸就会阻止收敛,normalized initialization和intermediate n ...
- Paper | Deep Residual Learning for Image Recognition
目录 1. 故事 2. 残差学习网络 2.1 残差块 2.2 ResNet 2.3 细节 3. 实验 3.1 短连接网络与plain网络 3.2 Projection解决短连接维度不匹配问题 3.3 ...
随机推荐
- zabbix server 与数据库不在同一台服务器上面
16312:20170527:095215.225 database is down: reconnecting in 10 seconds 16312:20170527:095225.225 [Z3 ...
- FFmpeg(14)-使用NDK、C++完成EGL,display, surface, context的配置和初始化
EGL 用它开发需要做哪些事情. DIsplay 与原生窗口建立链接.EGL在Android中可以用java调,也可以用C++调. EGLDisplay eglGetDisplay ...
- FFmpeg编译:jni not found 的问题
进入Android\Sdk\ndk-bundle\platforms\android-xx\arch-arm\usr目录查看发现与Google官方下载的NDK相比缺少include目录 此目录下包含各 ...
- React 设计思想
https://github.com/react-guide/react-basic React 设计思想 译者序:本文是 React 核心开发者.有 React API 终结者之称的 Sebasti ...
- 添加Fragment报已有父view,需先移除的错
错误LOG: 12-13 17:05:28.754: E/AndroidRuntime(8344): FATAL EXCEPTION: main 12-13 17:05:28.754: E/Andro ...
- 【流媒体】UPnP的工作过程
UPnP简介 通用即插即用(英语:Universal Plug and Play,简称UPnP)是由“通用即插即用论坛”(UPnP™ Forum)推广的一套网络协议. 该协议的目标是使家庭网络(数据共 ...
- VS2013 未找到与约束ContractName ...
控制面板>程序>程序和功能 找到如下选中软件右击修复 即可 需关闭VS2013 参考:http://blog.csdn.net/zhaoyun927/article/details/298 ...
- LeetCode: Binary Tree Inorder Traversal 解题报告
Binary Tree Inorder Traversal Given a binary tree, return the inorder traversal of its nodes' values ...
- Python提取MD5
使用Python的hashlib模块提取MD5,网上参考,觉得这个还不错,可以作为模块直接使用. # -*- coding: utf-8 -*- import hashlib import sys i ...
- JAVA-JSP内置对象之response对象实现页面跳转
相关资料:<21天学通Java Web开发> response对象 实现页面跳转1.可以通过response对象的sendRedirect()方法设置页面重定向,从而实现页面跳转.2.这种 ...