『cs231n』无监督学习
经典无监督学习
聚类
K均值
PCA主成分分析
等
深度学习下的无监督学习

- 自编码器
- 传统的基于特征学习的自编码器
- 变种的生成式自编码器
- Gen网络(对抗式生成网络)
传统自编码器
原理
类似于一个自学习式PCA,如果编码/解码器只是单层线性的话
自编码器编码解码示意图:
特征提取过程中甚至用到了卷积网络+relu的结构(我的认知停留在Originally级别)
编码&解码器可以共享权值(在我接触的代码中一般都没共享权值)
损失函数推荐L2

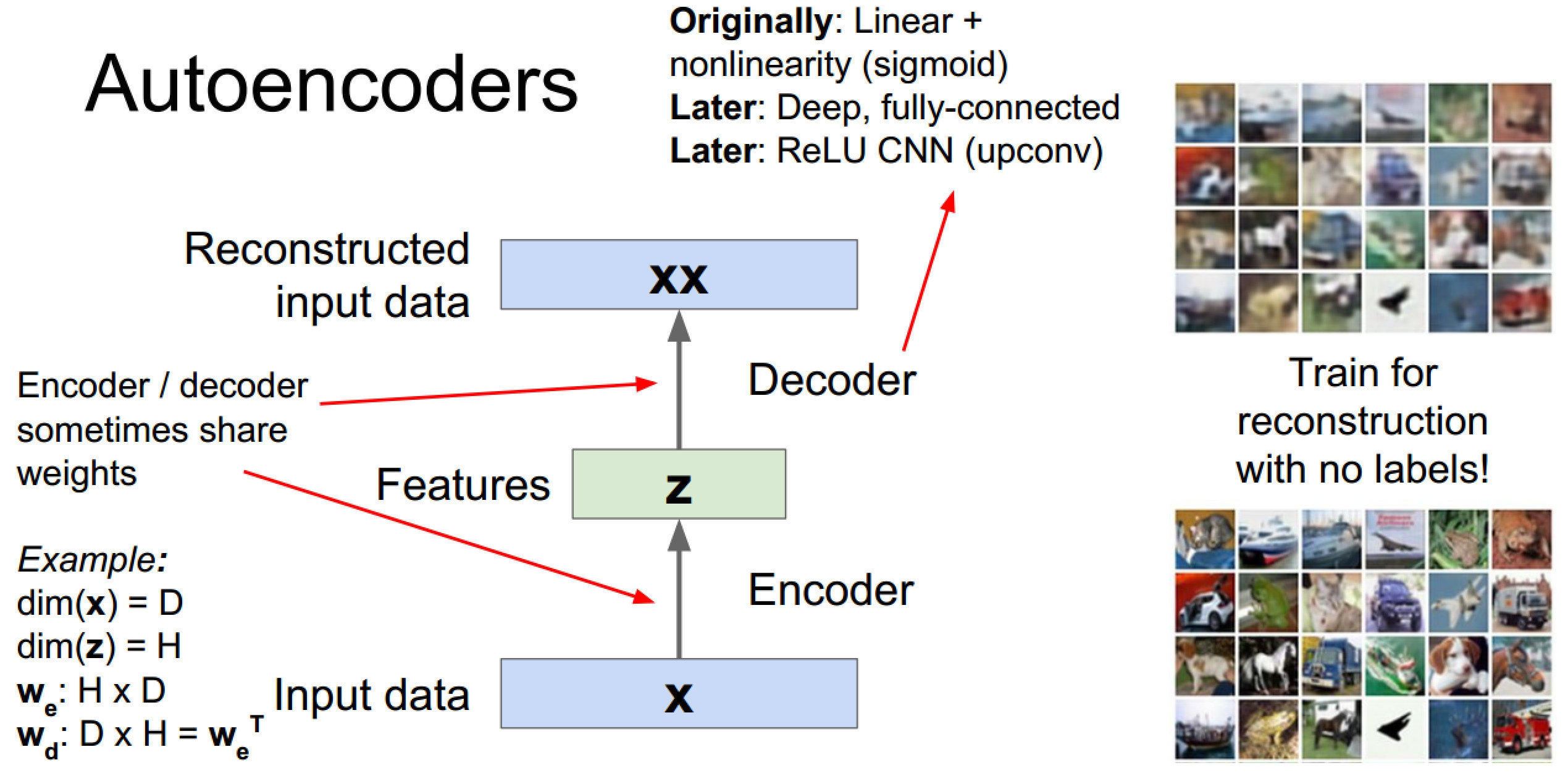

应用
由于重建已知数据是个没什么用的过程,所以自编码器一般在训练后会丢掉解码过程作为一个特征提取工具,
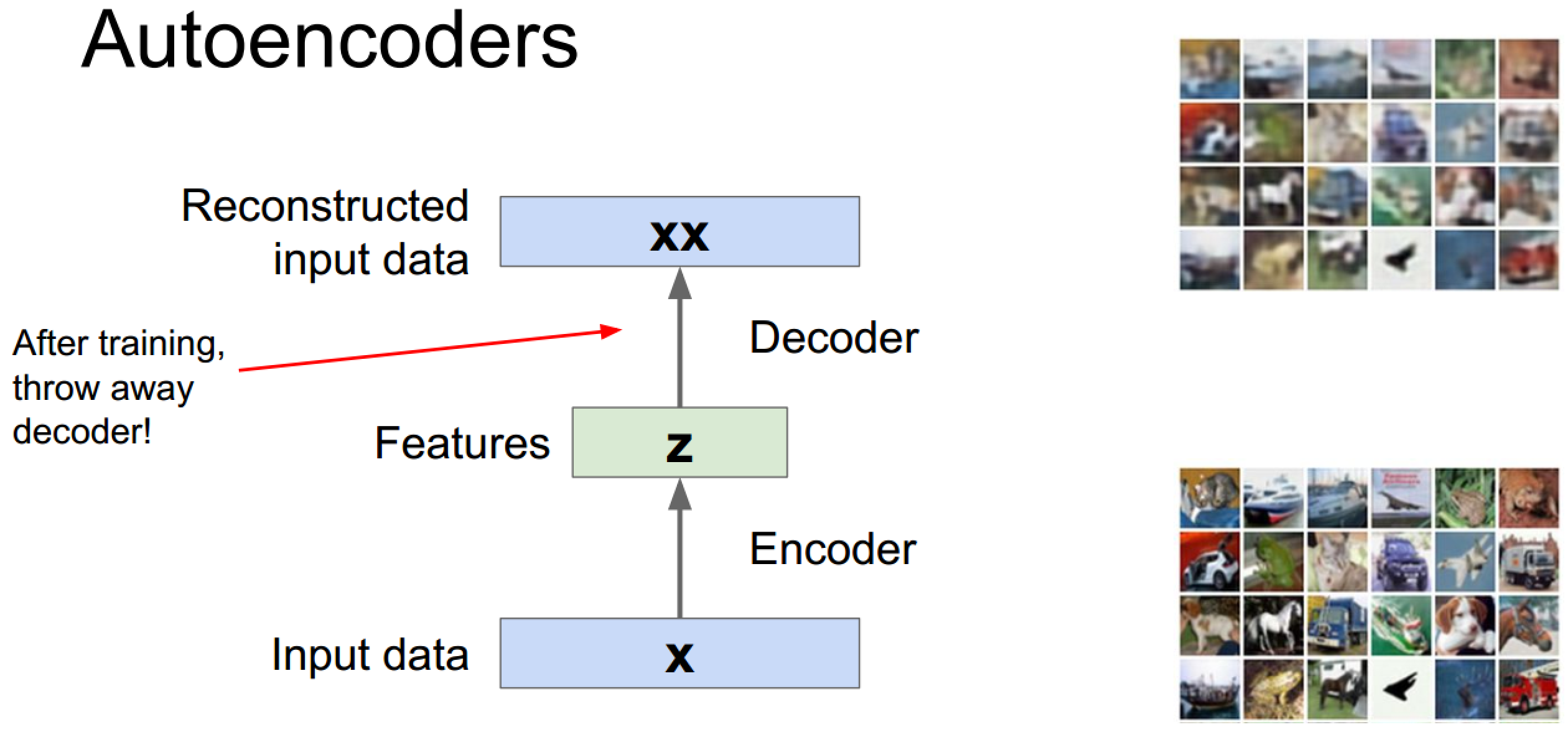
这里的思路是当我们有少量含标签数据以及大量无标签数据时,可以采用使用无标签数据训练自编码器,然后使用训练好的编码器加上分类器去提取有标签数据并训练分类器,不过现实可能不太好,这是老师的评价:


下图表示的是有标签数据经过训练好的编码器去训练分类器的过程,

通过监督学习进行微调,也分两种,一个是只调整分类器(黑色部分):

另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)

一旦监督训练完成,这个网络就可以用来分类了。
在相关文献中有提到Greedy Training的,这是一种逐层训练的方式,是由于当时数据数量和计算能力决定的,现在已经不再使用了,老师说他特意提出来也只是为了防止大家看到这个词蒙圈。
Variational Autoencoder
可以生成数据的自编码器变种——变分自编码器

位置一:我们将 encoder 的输出(2m个数)视作分别为m个高斯分布的均值(z_mean)和方差的对数(z_log_var),也就是特征z分布的描述
位置二、三:我们采样初始数据,根据 encoder 输出的均值与方差,生成服从相应高斯分布的随机数:
eps = tf.random_normal((self.batch_size, n_z), 0, 1,
dtype=tf.float32)
# z = mu + sigma*epsilon
self.z = tf.add(self.z_mean,
tf.mul(tf.sqrt(tf.exp(self.z_log_sigma_sq)), eps))
即使这样这里还有tips:


位置四:经由z还原x,计算loss,这里的loss计算颇为复杂,先给出结论,推导以后再说(逃... ...:


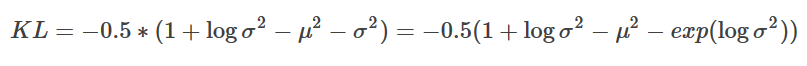

最后,尝试应用模型
下面是用于生成图片的应用,采样并尝试重构:
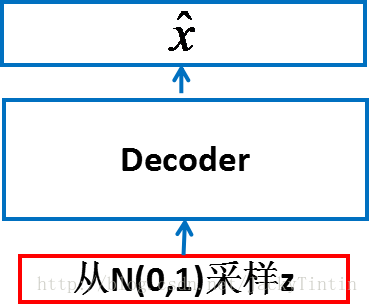
这里的z是直接采样得到的,而非先采样N(0,1)后使用均值标准差等还原出来的。
对抗式生成网络
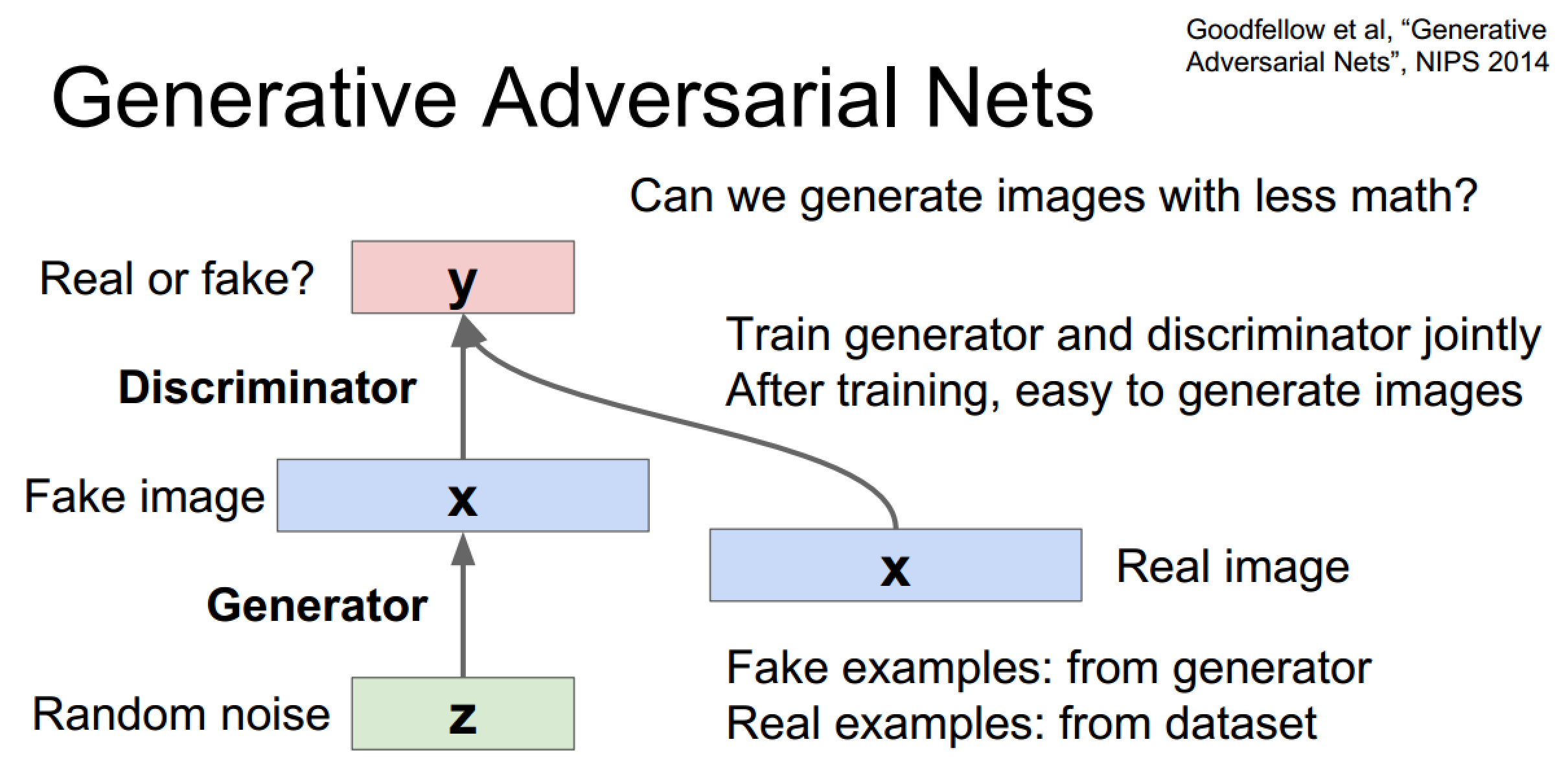
噪声->生成图 + 真图 ->分类器,实际属于二分类问题
由于结构简单在手写数字和人脸上效果不错,但对于复杂场景效果一般
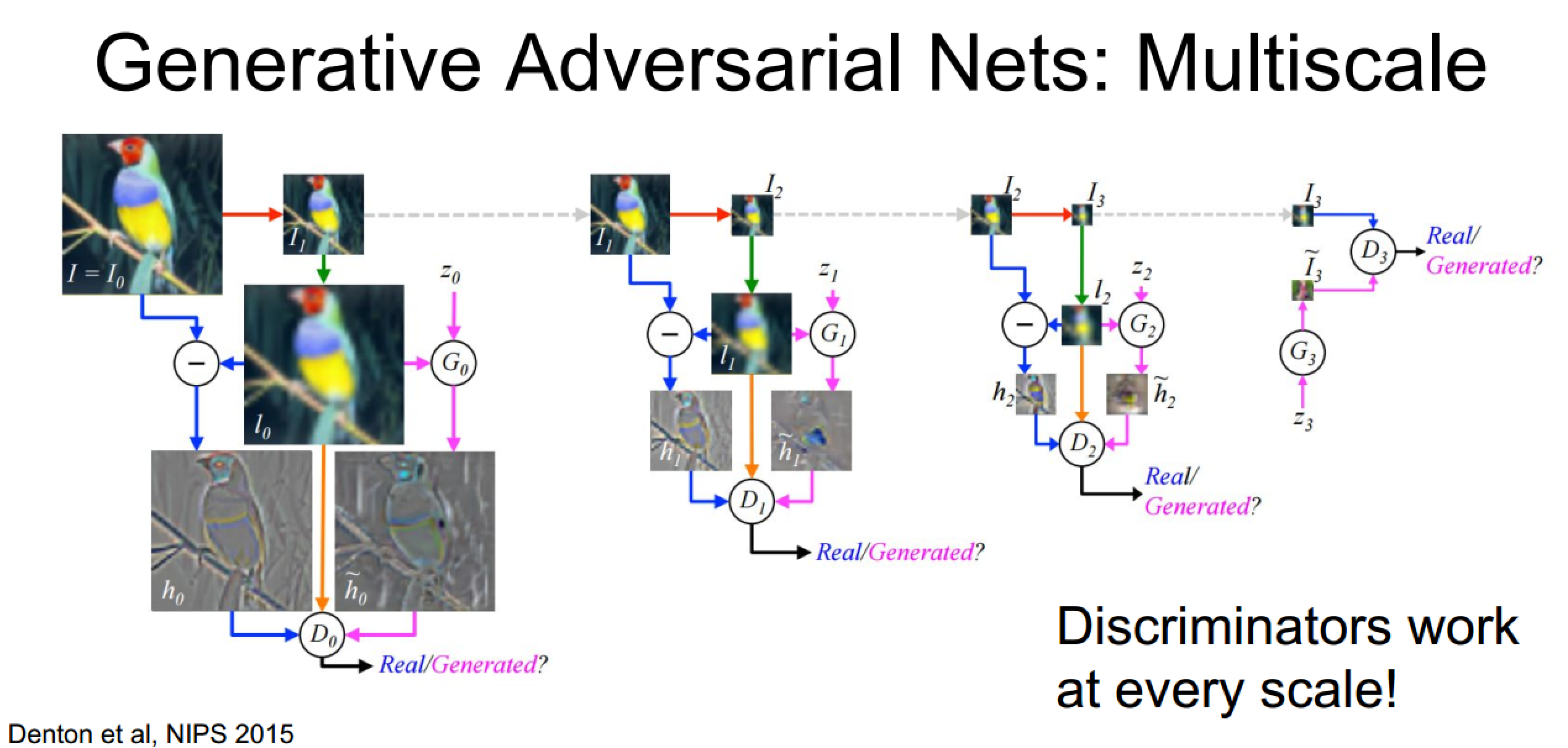
提高思路一:多尺度生成
自右向左逐层生成图像

训练过程比较繁琐:每个尺度都要进行鉴别
提高思路二:卷积生成网络

据说效果也很不错
混合型生成网络
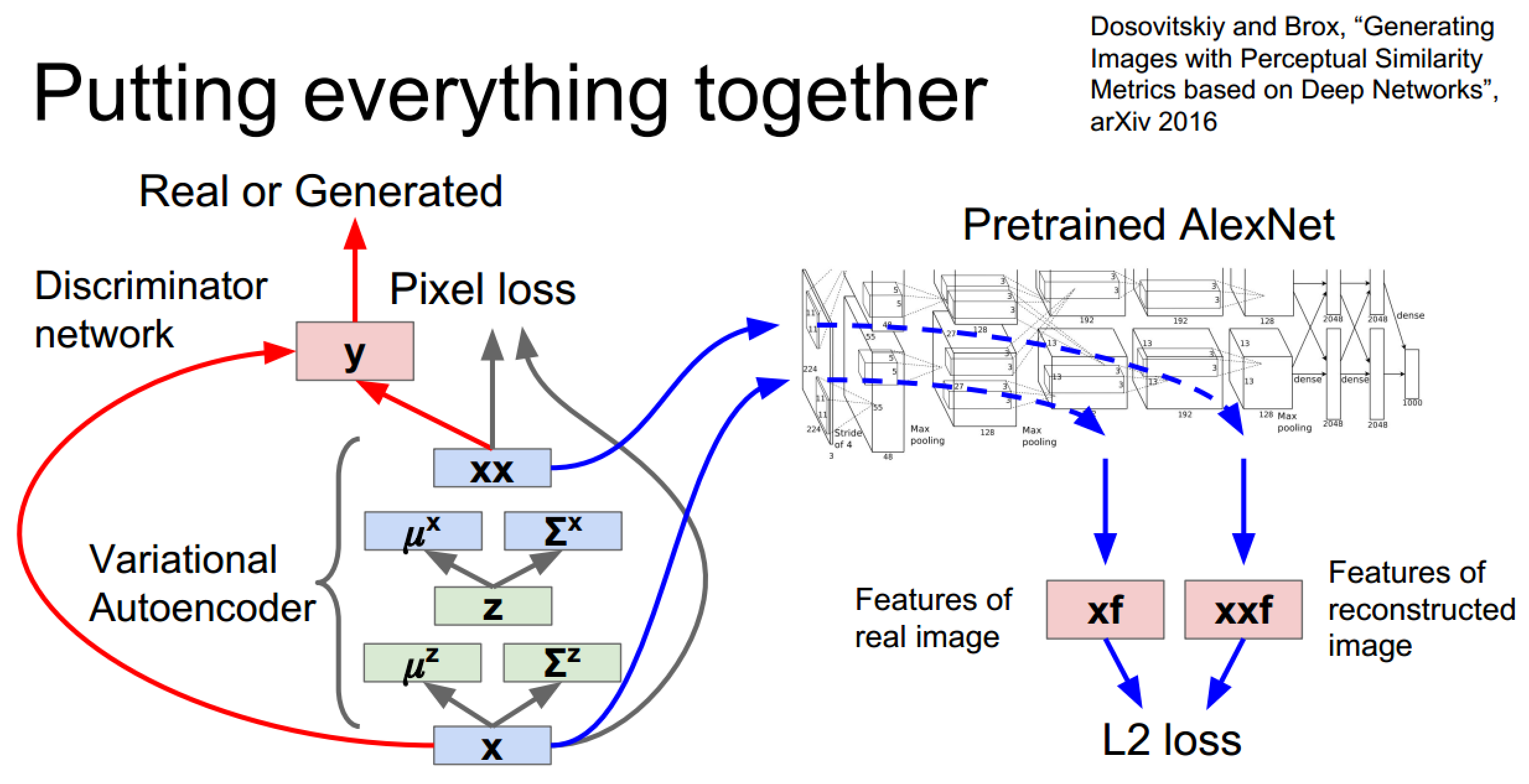
由于这部分内容不是课程重点,实际讲解也不够详细,所以记录的也就比较简洁了,主要把发展脉络理顺,各个PPT页上均有论文出处,如果有需要的话可以从论文入手。
『cs231n』无监督学习的更多相关文章
- 『cs231n』通过代码理解风格迁移
『cs231n』卷积神经网络的可视化应用 文件目录 vgg16.py import os import numpy as np import tensorflow as tf from downloa ...
- 『cs231n』计算机视觉基础
线性分类器损失函数明细: 『cs231n』线性分类器损失函数 最优化Optimiz部分代码: 1.随机搜索 bestloss = float('inf') # 无穷大 for num in range ...
- 『cs231n』卷积神经网络的可视化与进一步理解
cs231n的第18课理解起来很吃力,听后又查了一些资料才算是勉强弄懂,所以这里贴一篇博文(根据自己理解有所修改)和原论文的翻译加深加深理解,其中原论文翻译比博文更容易理解,但是太长,而博文是业者而非 ...
- 『cs231n』通过代码理解gan网络&tensorflow共享变量机制_上
GAN网络架构分析 上图即为GAN的逻辑架构,其中的noise vector就是特征向量z,real images就是输入变量x,标签的标准比较简单(二分类么),real的就是tf.ones,fake ...
- 『cs231n』注意力模型
RNN实现文本标注: 弊端是图像信息只在初始化时有用到 Soft Attention模型: 每一层具有三个输入:隐藏状态 + 注意力特征向量 + 词向量 每一层具有两个输出:新的位置分布(指示下一次‘ ...
- 『cs231n』视频数据处理
视频信息 和我之前的臆想不同,视频数据不仅仅是一帧一帧的图片本身,还包含个帧之间的联系,也就是还有一个时序的信息维度,包含人的动作判断之类的任务都是要依赖动作的时序信息的 视频数据处理的两种基本方法 ...
- 『cs231n』作业1选讲_通过代码理解KNN&交叉验证&SVM
通过K近邻算法探究numpy向量运算提速 茴香豆的“茴”字有... ... 使用三种计算图片距离的方式实现K近邻算法: 1.最为基础的双循环 2.利用numpy的broadca机制实现单循环 3.利用 ...
- 『cs231n』作业3问题3选讲_通过代码理解图像梯度
Saliency Maps 这部分想探究一下 CNN 内部的原理,参考论文 Deep Inside Convolutional Networks: Visualising Image Classifi ...
- 『cs231n』RNN之理解LSTM网络
概述 LSTM是RNN的增强版,1.RNN能完成的工作LSTM也都能胜任且有更好的效果:2.LSTM解决了RNN梯度消失或爆炸的问题,进而可以具有比RNN更为长时的记忆能力.LSTM网络比较复杂,而恰 ...
随机推荐
- mysql函数之四:concat() mysql 多个字段拼接
语法: COUNT(DISTINCT expr ,[expr ...]) 函数使用说明:返回不同的非NULL 值数目.若找不到匹配的项,则COUNT(DISTINCT) 返回 0 Mysql的查询结果 ...
- JavaScript位运算符 2
按位运算符是把操作数看作一系列单独的位,而不是一个数字值.所以在这之前,不得不提到什么是“位”: 数值或字符在内存内都是被存储为0和 1的序列,每个0和1被称之为1个位,比如说10进制数据2在计算机内 ...
- http协议/获得请求/中文参数处理/访问数据库
# 1. http协议(了解)## (1)什么是http协议?一种网络应用层协议,规定了浏览器与web服务器之间如何通信以及相应的的数据包的结构.注:tcp/ip协议:保证数据可靠的传递.(UDP不可 ...
- (四)github之Git的初始设置
设置姓名与邮箱地址 这里的姓名和邮箱地址会用在git的提交日志之中,在github上公开git仓库时会随着提交日志一起公开. 有两种方式, 第一种,在git bash下设置 第二种, 通过直接编辑.g ...
- 使用openssl生成SSL证书完全参考手册
一般来说,配置HTTPS/SSL的步骤为: 1.生成足够强度的私钥.需要考虑:算法,广泛采用的一般是RSA.键长度,RSA默认为512,一般应选择2048.密码,虽然私钥不一定要加密存储,但是加密存储 ...
- 20145227鄢曼君《网络对抗》shellcode注入&Return-to-libc攻击深入
20145227鄢曼君<网络对抗>shellcode注入&Return-to-libc攻击深入 shellcode注入实践 shellcode基础知识 Shellcode实际是一段 ...
- Elasticsearch 基础概念知识
接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒). 集群(cluster) 一个集群就是由一个或多 ...
- User-Defined Table Types 用户自定义表类型
Location 数据库--可编程性--类型--用户定义表类型 select one database--> programmability-->types-->user--defi ...
- java进制转换代码
定义十进制的数直接写,定义8进制的数以0开头,定义二进制的数以0b开头,定义十六进制的数以0x开头需要将十进制的数以二进制的数表示出来可以参照下例: int a = 10; System.out.pr ...
- Spring编译AOP项目报错
警告: Exception encountered during context initialization - cancelling refresh attempt: org.springfram ...