java操作hbase1.3.1的增删改查
我的eclipse程序在windows7机器上,hbase在linux机器上
1,首先在C:\Windows\System32\drivers\etc下面的HOSTS文件,加上linux 集群
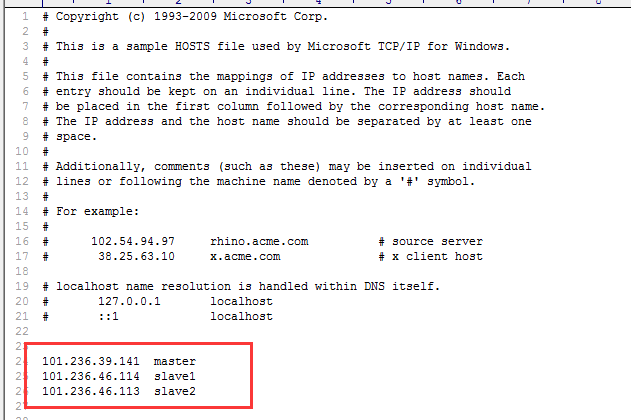
2.直接附上代码:
package com.yilian.util; import java.io.File;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes; public class HbaseTest2 {
public static Configuration configuration;
public static Connection connection;
public static Admin admin; public static void main(String[] args) throws IOException {
//createTable("t2", new String[] { "cf1", "cf2" });
listTables();
/*
* insterRow("t2", "rw1", "cf1", "q1", "val1"); getData("t2", "rw1",
* "cf1", "q1"); scanData("t2", "rw1", "rw2");
* deleRow("t2","rw1","cf1","q1"); deleteTable("t2");
*/
} // 初始化链接
public static void init() {
configuration = HBaseConfiguration.create();
/*
* configuration.set("hbase.zookeeper.quorum",
* "10.10.3.181,10.10.3.182,10.10.3.183");
* configuration.set("hbase.zookeeper.property.clientPort","2181");
* configuration.set("zookeeper.znode.parent","/hbase");
*/
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "101.236.39.141,101.236.46.114,101.236.46.113");
configuration.set("hbase.master", "101.236.39.141:60000");
File workaround = new File(".");
System.getProperties().put("hadoop.home.dir",
workaround.getAbsolutePath());
new File("./bin").mkdirs();
try {
new File("./bin/winutils.exe").createNewFile();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
} // 关闭连接
public static void close() {
try {
if (null != admin)
admin.close();
if (null != connection)
connection.close();
} catch (IOException e) {
e.printStackTrace();
} } // 建表
public static void createTable(String tableNmae, String[] cols) throws IOException { init();
TableName tableName = TableName.valueOf(tableNmae); if (admin.tableExists(tableName)) {
System.out.println("talbe is exists!");
} else {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
for (String col : cols) {
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(col);
hTableDescriptor.addFamily(hColumnDescriptor);
}
admin.createTable(hTableDescriptor);
}
close();
} // 删表
public static void deleteTable(String tableName) throws IOException {
init();
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);
admin.deleteTable(tn);
}
close();
} // 查看已有表
public static void listTables() throws IOException {
init();
HTableDescriptor hTableDescriptors[] = admin.listTables();
for (HTableDescriptor hTableDescriptor : hTableDescriptors) {
System.out.println(hTableDescriptor.getNameAsString());
}
close();
} // 插入数据
public static void insterRow(String tableName, String rowkey, String colFamily, String col, String val)
throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowkey));
put.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(col), Bytes.toBytes(val));
table.put(put); // 批量插入
/*
* List<Put> putList = new ArrayList<Put>(); puts.add(put);
* table.put(putList);
*/
table.close();
close();
} // 删除数据
public static void deleRow(String tableName, String rowkey, String colFamily, String col) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowkey));
// 删除指定列族
// delete.addFamily(Bytes.toBytes(colFamily));
// 删除指定列
// delete.addColumn(Bytes.toBytes(colFamily),Bytes.toBytes(col));
table.delete(delete);
// 批量删除
/*
* List<Delete> deleteList = new ArrayList<Delete>();
* deleteList.add(delete); table.delete(deleteList);
*/
table.close();
close();
} // 根据rowkey查找数据
public static void getData(String tableName, String rowkey, String colFamily, String col) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowkey));
// 获取指定列族数据
// get.addFamily(Bytes.toBytes(colFamily));
// 获取指定列数据
// get.addColumn(Bytes.toBytes(colFamily),Bytes.toBytes(col));
Result result = table.get(get); showCell(result);
table.close();
close();
} // 格式化输出
public static void showCell(Result result) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println("RowName:" + new String(CellUtil.cloneRow(cell)) + " ");
System.out.println("Timetamp:" + cell.getTimestamp() + " ");
System.out.println("column Family:" + new String(CellUtil.cloneFamily(cell)) + " ");
System.out.println("row Name:" + new String(CellUtil.cloneQualifier(cell)) + " ");
System.out.println("value:" + new String(CellUtil.cloneValue(cell)) + " ");
}
} // 批量查找数据
public static void scanData(String tableName, String startRow, String stopRow) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
// scan.setStartRow(Bytes.toBytes(startRow));
// scan.setStopRow(Bytes.toBytes(stopRow));
ResultScanner resultScanner = table.getScanner(scan);
for (Result result : resultScanner) {
showCell(result);
}
table.close();
close();
} }
3.项目下面还要放上linux环境上配置hadoop和hbase配置文件,hbase-site.xml和hdfs-site.xml,下面是我项目的简单结构
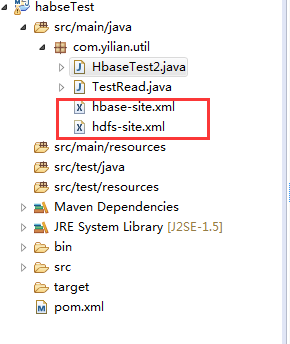
4.按要求贴上pom.xml文件,我这项目还用了hive,redis连接,所以pom.xml写的jar比较多,但其实只需要hbase连接的jar就行
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yilian.hbase</groupId>
<artifactId>habseTest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>habseTest</name> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency> <dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.3.1</version>
</dependency> <dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.1</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency> <dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jms</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-expression</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.33</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
</dependency>
</dependencies>
</distributionManagement>
</project>
java操作hbase1.3.1的增删改查的更多相关文章
- java操作elasticsearch实现基本的增删改查操作
一.在进行java操作elasticsearch之前,请确认好集群的名称及对应的ES节点ip和端口 1.查看ES的集群名称 #进入elasticsearch.yml配置文件/opt/elasticse ...
- AD 域服务简介(三)- Java 对 AD 域用户的增删改查操作
博客地址:http://www.moonxy.com 关于AD 域服务器搭建及其使用,请参阅:AD 域服务简介(一) - 基于 LDAP 的 AD 域服务器搭建及其使用 Java 获取 AD 域用户, ...
- java jdbc 连接mysql数据库 实现增删改查
好久没有写博文了,写个简单的东西热热身,分享给大家. jdbc相信大家都不陌生,只要是个搞java的,最初接触j2ee的时候都是要学习这么个东西的,谁叫程序得和数据库打交道呢!而jdbc就是和数据库打 ...
- Java通过JDBC进行简单的增删改查(以MySQL为例)
Java通过JDBC进行简单的增删改查(以MySQL为例) 目录: 前言:什么是JDBC 一.准备工作(一):MySQL安装配置和基础学习 二.准备工作(二):下载数据库对应的jar包并导入 三.JD ...
- 第三百零七节,Django框架,models.py模块,数据库操作——表类容的增删改查
Django框架,models.py模块,数据库操作——表类容的增删改查 增加数据 create()方法,增加数据 save()方法,写入数据 第一种方式 表类名称(字段=值) 需要save()方法, ...
- 五 Django框架,models.py模块,数据库操作——表类容的增删改查
Django框架,models.py模块,数据库操作——表类容的增删改查 增加数据 create()方法,增加数据 save()方法,写入数据 第一种方式 表类名称(字段=值) 需要save()方法, ...
- java+jsp+sqlserver实现简单的增删改查操作 连接数据库代码
1,网站系统开发需要掌握的技术 (1)网页设计语言,html语言css语言等 (2)Java语言 (3)数据库 (4)等 2,源程序代码 (1) 连接数据库代码 package com.jaovo.m ...
- Java对XML文档的增删改查
JAVA增删改查XML文件 最近总是需要进行xml的相关操作. 不免的要进行xml的读取修改等,于是上网搜索,加上自己的小改动,整合了下xml的常用操作. 读取XML配置文件 首先我们需要通过Do ...
- Java描述数据结构之链表的增删改查
链表是一种常见的基础数据结构,它是一种线性表,但在内存中它并不是顺序存储的,它是以链式进行存储的,每一个节点里存放的是下一个节点的"指针".在Java中的数据分为引用数据类型和基础 ...
随机推荐
- Android中Parcel的分析以及使用
简单点来说:Parcel就是一个存放读取数据的容器, Android系统中的binder进程间通信(IPC)就使用了Parcel类来进行客户端与服务端数据的交互,而且AIDL的数据也是通过Parcel ...
- ERROR 1045 (28000): Access denied for user 'ODBC'@'localhost' (using password: N O) MYSQL
ERROR 1045 (28000): Access denied for user ODBC@localhost 刚使用mysql, 碰到这个问题.. C:\Program Files\MySQL\ ...
- jQuery--- .hasOwnProperty 用法
☆ obj.hasOwnProperty('prop'): 是用来判断一个对象是否有你给出名称的属性或对象.不过需要注意的是, 此方法无法检查该对象的原型链中是否具有该属性,该属性必须是对象本身的一个 ...
- test20180922 打铁的匠
题意 分析 法一:吉司机线段树 这是一个在线的\(O( n + q \cdot \log^2 n)\)做法. 考虑维护节点到根的权值前缀和cost,那么查询的时候区间减去子树根节点的cost就是价值. ...
- dns over https 简单测试(docker 运行)
dns over https 已经成为了标准了,给予我们的dns 解析添加了安全的支持 测试项目使用docker && docker-compose 运行 一张参考图 环境准备 d ...
- streamsets k8s 部署试用
使用k8s 进行 streamsets的部署(没有使用持久化存储) k8s deploy yaml 文件 deploy.yaml apiVersion: extensions/v1beta1 kind ...
- 时间操作(JavaScript版)—页面显示格式:年月日 上午下午 时分秒 星期
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/wangshuxuncom/article/details/35222531 <!DOCTYPE ...
- TensorFlow 官方文档中文版学习
TensorFlow 官方文档中文版 地址:http://wiki.jikexueyuan.com/project/tensorflow-zh/
- ShareMemory
项目地址 : https://github.com/kelin-xycs/ShareMemory ShareMemory 一个用 C# 实现的 No Sql 数据库 , 也可以说是 分布式 缓存 , ...
- 【转】每天一个linux命令(51):lsof命令
原文网址:http://www.cnblogs.com/peida/archive/2013/02/26/2932972.html lsof(list open files)是一个列出当前系统打开文件 ...