kappa系数在大数据评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html
前言
最近打算把翻译质量的人工评测好好的做一做。
首先废话几句,介绍下我这边翻译质量的人工评测怎么做。先找一批句子,然后使用不同的引擎对其进行翻译,然后将原文和译文用下面的方式进行呈现,把这些交给专业的人士去进行打分,打完分之后,对结果进行统计,得出评测结果。
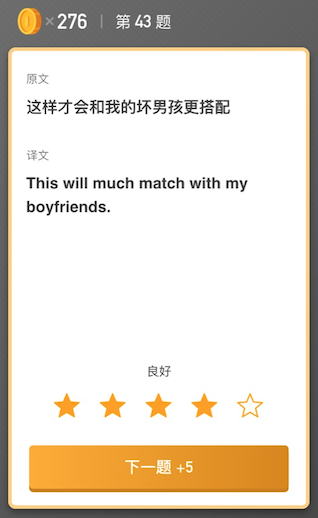
看似流程很顺利,且结果也有参考价值。然而实际操作的过程中发现如果一个用户的能力或者态度有问题的话,就会影响一个打分的效果。因此评测人员究竟是否靠谱也成了我们需要考虑的一项因素。
通过向专业人士请教,得知了kappa系数可以进行一致性的校验且可用来衡量分类精度。因此我决定试试它。
好了先看看kappa系数的概念和计算公式。
kappa系数概念
它是通过把所有地表真实分类中的像元总数(N)乘以混淆矩阵对角线(Xkk)的和,再减去某一类地表真实像元总数与被误分成该类像元总数之积对所有类别求和的结果,再除以总像元数的平方减去某一类中地表真实像元总数与该类中被误分成该类像元总数之积对所有类别求和的结果所得到的。
——来自百科
kappa计算结果为-1~1,但通常kappa是落在 0~1 间,可分为五组来表示不同级别的一致性:0.0~0.20极低的一致性(slight)、0.21~0.40一般的一致性(fair)、0.41~0.60 中等的一致性(moderate)、0.61~0.80 高度的一致性(substantial)和0.81~1几乎完全一致(almost perfect)。
计算公式:

po是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度
假设每一类的真实样本个数分别为a1,a2,...,aC
而预测出来的每一类的样本个数分别为b1,b2,...,bC
总样本个数为n
则有:pe=a1×b1+a2×b2+...+aC×bC / n×n
运算举例
为了更好的理解上述运算的过程,这里举例说明一下:
学生考试的作文成绩,由两个老师给出 好、中、差三档的打分,现在已知两位老师的打分结果,需要计算两位老师打分之间的相关性kappa系数:
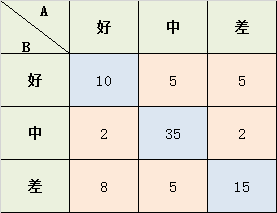 Po = (10+35+15) / 87 = 0.689
Po = (10+35+15) / 87 = 0.689
a1 = 10+2+8 = 20; a2 = 5+35+5 = 45; a3 = 5+2+15 = 22;
b1 = 10+5+5 = 20; b2 = 2+35+2 = 39; b3 = 8+5+15 = 28;
Pe = (a1*b1 + a2*b2 + a3*b3) / (87*87) = 0.455
K = (Po-Pe) / (1-Pe) = 0.4293578
这样我们就得到了kappa系数。
实际应用
像开头说的一样,真实的问卷回收回来后,我一般都会对用户的结果进行kappa系数计算之后才会发放奖励,因为我的奖励价格不低,也算是为了公司节省成本吧。
一般一个问卷我会让5个人去做,当然人越多越准确,但是为了考虑成本且就能得到有效的结果,我这里选了5个人,起初我的想法是用5个人的平均分做为标准答案,然后让每个人的打分去和平均分算kappa,后来思考后发现这样有些不太合理,如果有一个人乱答,那么他的结果就会影响平均分,从而影响到整个结果。于是最终换成了一个人和所有人直接计算kappa,然后再求平均。这样当一个人乱作答的时候,我们在算出两两kappa的时候就可以发现这个人,然后在最终计算平均kappa的时候,去掉这个所有人和这个人之间的值即可。
刚开始我用python实现了kappa系数计算的代码,直接算出了一组结果,然后发现大家相互之前的kappa系数都非常的低,大概在0.1-0.2左右,后来分析是由于5分制导致数据太离散,因此针对翻译引擎的评测,我将用户打分的5分制换算成了3分制,1、2分归为一类,2为一类,4、5为一类。
当然在完成了这些之后,为了再多一轮保险,每一份问卷中的5个人中,有一个我非常信任的专业评测者,因此我还会计算所有人和她直接的kappa,这样更加的保证每一个打分的结果合理性和相关性都竟在掌握之中。
下面是我实现的python脚本。
#-*- coding:utf-8 -*-
# 脚本用途:算出所有人的kappa 和 第一个人和所有人的kappa默认第一个人是 优质用户
# 脚本使用方法:
# get**.py 优秀用户文件 其他用户文件。。。。
import sys reload(sys)
sys.setdefaultencoding("utf-8") # (用户1)
#avg_file = sys.argv[1]
avglist = [] # (用户2)
#user_file = sys.argv[2]
userlist = [] # 二维矩阵
matrix = [[0 for col in range(4)] for i in range(4)] # 数据读取到list中
def initList(file1, file2):
#print 'avg file: ' + file1 + '; user file: ' + file2
global avglist
global userlist
avglist = []
userlist = [] for line in open(file1):
line = line.strip()
avglist.append(float(line)) for line in open(file2):
line = line.strip()
userlist.append(float(line))
#print avglist, userlist # 处理平均分为标准分
def avgFormat():
global avglist
global userlist
for i in range(0, len(avglist)):
num = avglist[i]
if num < 2.499:
avglist[i] = 1
elif num > 2.499 and num < 3.499:
avglist[i] = 2
elif num > 3.499 :
avglist[i] = 3
else:
print 'num is error! ', num for i in range(0, len(userlist)):
num = userlist[i]
if num < 2.499:
userlist[i] = 1
elif num > 2.499 and num < 3.499:
userlist[i] = 2
elif num > 3.499 :
userlist[i] = 3
else:
print 'num is error! ', num
#print avglist, userlist # 输出,调试用
def printlist(listname):
for l in listname:
print l # 计算矩阵
def getMatrix():
num1 = len(avglist)
num2 = len(userlist)
if num1 != num2:
print 'two list num is not same!'
return global matrix
matrix = [[0 for col in range(4)] for i in range(4)] for i in range(0, num1):
x = int(avglist[i])
y = int(userlist[i])
matrix[x][y] = matrix[x][y] + 1 # 输出矩阵
def printmatrix():
#print '\nmatrix is:'
for num in range(1, 4):
print matrix[num][1], matrix[num][2],matrix[num][3]
#print '\n' # 得到kappa值
def getkappa():
# 对角线之和
dsum = 0.0
# 总数
allsum = float(len(avglist)) global matrix # 计算对角线的和
for i in range(1, 4):
dsum = dsum + matrix[i][i] #print dsum
#print 'diagonal sum is :', dsum
p0 = float(dsum)/allsum
#print 'p0 is :', p0 , '\n' # 计算a1*b1+a2*b2+...ac*bc的和(a1 等于 matrix[1][x]的和 b1等于matrix[x][1]的和)
a = 0
al = []
b = 0
bl = []
for j in range(1, 4):
a = 0
b = 0
for k in range(1, 4):
a = a + matrix[j][k]
b = b + matrix[k][j]
al.append(a)
bl.append(b) #print 'a list is ', al
#print 'b list is ', bl tmpsum = 0
for l in range (0, 3):
tmpsum = tmpsum + al[l]*bl[l]
#print 'pe fenzi sum is: ', tmpsum pe = float(tmpsum)/float(allsum*allsum)
#print 'pe is: ',pe , '\n' kappa = (p0-pe)/(1-pe)
#print 'kappa is : ', kappa
return kappa def gettwokappa(file_one, file_two):
initList(file_one, file_two)
avgFormat()
#printlist(avglist)
getMatrix()
#printmatrix()
return getkappa() file_list = sys.argv[1:] i = 0
for user_file in file_list:
allkappa = 0
for other_file in file_list:
if user_file != other_file:
#print user_file, other_file,':'
kapp = gettwokappa(user_file, other_file)
allkappa = allkappa + kapp
# 第一个优质用户 需要输出一下别人和她的kappa
if i == 0:
print user_file, other_file, ':', kapp
i= i+1 print user_file, ' avg kappa: ', allkappa/(len(file_list)-1)
运行的时候,需要 python getallKappa_ref_3level.py 用户1的文件 用户2的文件 .. (默认认为用户1是优秀的用户)
这里用户文件中就是用户的打分信息:

好,我们运行一下看下真实的运行结果。
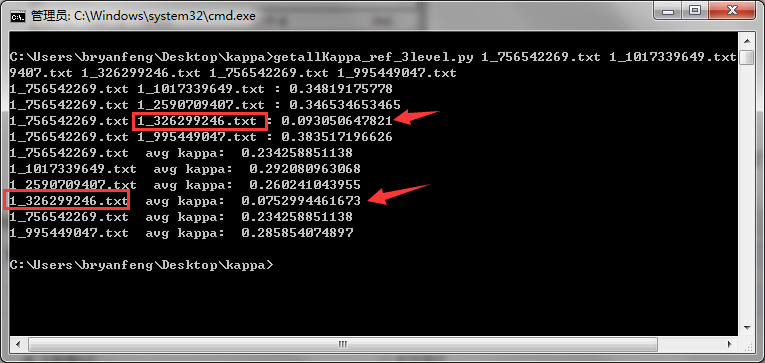
下面是其中一次问卷,我计算的 “所有人之间kappa的平均分” 和 “所有人和优秀评测者之间的kappa” 不言而喻,很明显下图中标红的这位用户的打分就不合格,无论是他和优秀者之间的kappa还是他和别人之间kappa的平均值,都是非常低的。经过我人工筛查,果然这个用户的打分的确非常的不合理。 这样就被我们过滤掉了。
有了kappa系数的计算规则后,对于一些类似这样的打分规则,我们就有了更多的把握以及更了解我们的评测结果是否准确可靠。
算法优化
按照上面的步骤,确实可以滤除一些不好的用户,但是我又仔细思考了一下整个过程。
首先我的做法是:我在已经有了这些翻译的的平均得分的情况下,将平均分首先四舍五入,然后和新用户的打分结果计算kappa,这里我选择了“10个新的用户的数据”和“四舍五入后的数据”进行kappa计算:


我们可以看到,人员之间的差距其实比较明显了,但是有一个致命的问题就是:kappa系数普遍较低,难度没有一个人做的和正确答案比较的相似吗?经过仔细分析以及向有经验的人请教得知:由于5分制导致数据太离散,因此结果会很低,其实应该将4分5分归为同样的结果,3分一个结果,1分2分看做为同样的结果,因此我将代码修改了将用户打分的5分制换算成了3分制。具体可以看看代码,最终计算的结果:

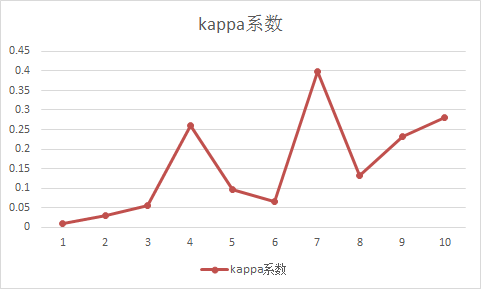
可以看到,kappa系数的分值明显提高了,但是新的问题来了:改用3分制后,曲线的部分趋势和5分值不一致了。那么到底哪个更趋近于真实呢?造成的误差在哪里呢?我自己的想了一下,将平均分(一般都是小数)转换为整数的时候,势必会丢掉一些信息,而将五分制转换为三分制的时候同样也会面临这样的问题,并且丢失的信息更多。那么我们回到最初的那个问题上,如何在不损失以后数据信息的情况下,计算kappa。其实还是刚才那个问题,举个简单例子:一道题平均分4.4,一个用户打了5分,一个打了4分,按照5分制计算的话,4.4会被转换为4,因此4分会被加到P0的分子里,但是5分的不会,但其实5分的也应该算很高相似度的,因为正是有了很多人打5分,平均值才能在4分之上,那么我们是否可以不转4.4,而是用用户打分和平均分之间的差值来决定是否要被加到P0的分子中,那么新的问题就来了,这个值我应该选多少合适,这里我做了一组实验,将这个值在0.1~0.9的结果都进行了计算:
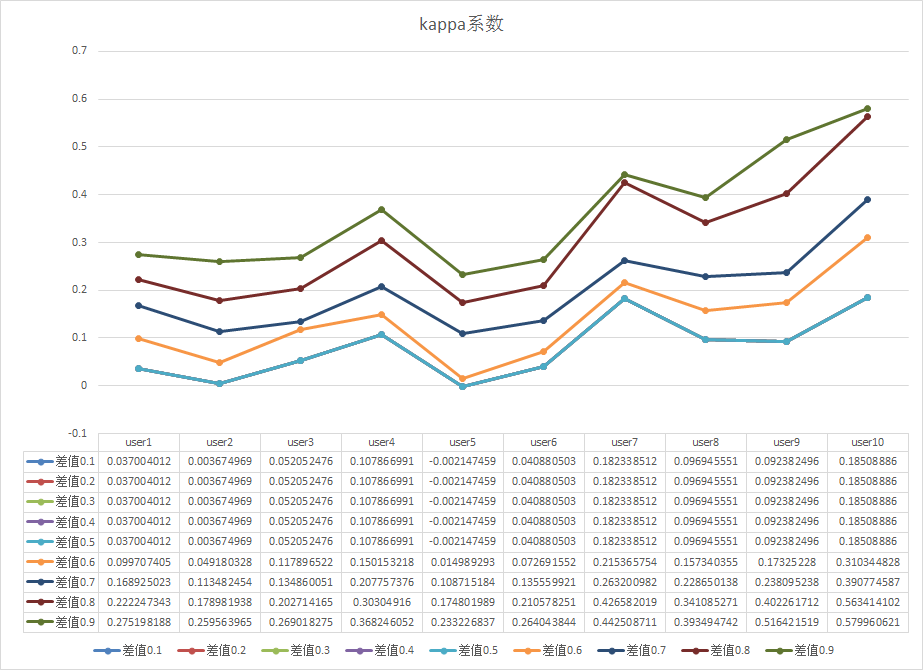
图中可以看到差值越小,得到的kappa值越小,差值越大,kappa值就越大,之前的方案都是因为只抓了一个点,而实际上这些数据我们都需要考虑,差值越小,说明和平均分越接近,如果在越接近的情况下,kappa值高,那就说明相关性更高,因此我们需要给差值小的更大的权重。
0.1~0.9 我们都给分配不同的权重,暂时按照:1x+2x+3x+4x+5x+6x+7x+8x+9x = 1 解得 x = 0.0222..
所以最终公式:=F:F*0.199+G:G*0.177+H:H*0.155+I:I*0.133+J:J*0.11+K:K*0.088+L:L*0.066+M:M*0.044+N:N*0.022 (excel公式,从F列开始的),得到:

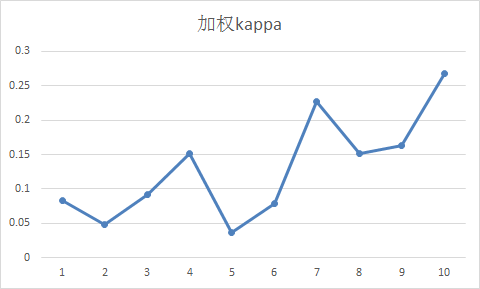
相关资料:这里

由于0.1的值小于0,所以这里我们将这个值忽略,
0.021689*8x + 0.378608*7x + 0.6713388*6x + 1*5x + 1*4x + 1*3x + 1*2x + 1*1x = 1,得:x=0.045
所以每个差值(0.1的差值我们就不取了)对应的权重值为:8x、7x、6x、5x、4x、3x、2x、1x
即 0.36、0.315、0.27、0.225、0.18、0.135、0.09、0.045
kappa系数在大数据评测中的应用的更多相关文章
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
- 聊聊自学大数据flume中容易被人忽略的细节
前言:老刘不敢保证说的有多好,但绝对是非常良心地讲述自学大数据开发路上的一些经历和感悟,保证会讲述一些不同于别人技术博客的细节. 01 自学flume的细节 老刘现在想写点有自己特色的东西,讲讲自学 ...
- 大数据SQL中的Join谓词下推,真的那么难懂?
听到谓词下推这个词,是不是觉得很高大上,找点资料看了半天才能搞懂概念和思想,借这个机会好好学习一下吧. 引用范欣欣大佬的博客中写道,以前经常满大街听到谓词下推,然而对谓词下推却总感觉懵懵懂懂,并不明白 ...
- 大数据项目中的Oracle查询优化
今天发现自己之前写的一些SQL查询在执行效率方面非常不理想,于是尝试做了些改进. 需求为查询国地税表和税源表中,国税有而税源没有的条目数,之前的查询如下: SELECT COUNT(NAME) FRO ...
- 大数据项目中js中代码和java中代码(解决Tomcat打印日志中文乱码)
Idea2018中集成Tomcat9导致OutPut乱码找到tomcat的安装目录,打开logging.properties文件,增加一行代码,覆盖默认设置,将日志编码格式修改为GBK.java.ut ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 深入理解大数据架构之——Lambda架构
目录 传统系统的问题 Lambda架构简介 Lambda架构关键特性 数据系统的本质 Lambda的三层架构 Lambda架构组件选型 总结 原文链接:https://jiang-hao.com/ar ...
- hadoop--大数据生态圈中最基础、最重要的组件
hadoop是什么? hadoop是一个由Apache基金会所开发的分布式系统基础架构,hdfs分布式文件存储.MapReduce并行计算.主要是用来解决海量数据的存储和海量数据的分析计算问题,这是狭 ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
随机推荐
- cocos2dx 3.x 精灵重叠时点击最上层的精灵
ps. 这个方法只适用设置精灵的触摸.. //注册触摸事件..3.X后可以在这样写..不需要重新声明 EventListenerTouchOneByOne *listener = EventListe ...
- eclipse上的.properties文件中文编辑显示处理
最近在对接银联备份金,将相应的SDK导入到eclipse后,打开.properties文件中文注释变成了如下样子,很不方便查阅参照: 平常开发我们希望看到的是如下样子,很直观能明确配置的参数代表的信息 ...
- Qt 编码问题QTextCodec
在学习计算机语言的时候, 关于字体编码问题, 一直是大家开始学习新语言比较头痛的问题, 在这边总结一下关于Qt图形框架开发的编码问题. 一般在Window开发环境里,是GBK编码,在Linux开发环境 ...
- 20145329 《Java程序设计》实验一总结
实验指导教师:娄嘉鹏老师 实验日期:2016.4.8 实验时间:16:30~18:30 实验序号:实验一 实验名称:Java开发环境的熟悉 实验目的与要求: 使用JDK编译.运行简单的Java程序. ...
- TCP/IP的相关协议
- HA-web-services
一.HA部署 本次实验的程序选型为heartbeat v1 + hearesources.资源有IP和httpd,filesystem 配置HA集群的前提: (1)各节点资源一致,硬件或软件环境一致 ...
- mybatis动态sql中的bind绑定
知识点:bind在模糊查询中的用法 在我的博客 mybatis中使用mysql的模糊查询字符串拼接(like) 中也涉及到bind的使用 <!-- List<Employee> ...
- c# iText 生成PDF 有文字,图片,表格,文字样式,对齐方式,页眉页脚,等等等,
#region 下载说明书PDF protected void lbtnDownPDF_Click(object sender, EventArgs e) { int pid = ConvertHel ...
- 2017 ACM/ICPC Asia 南宁区 L The Heaviest Non-decreasing Subsequence Problem
2017-09-24 20:15:22 writer:pprp 题目链接:https://nanti.jisuanke.com/t/17319 题意:给你一串数,给你一个处理方法,确定出这串数的权值, ...
- 网络软中断与NAPI函数分析
网卡只有rx硬中断,外设通过中断控制器向CPU发出有数据包来临的通知, 而没有tx硬中断,因为发送数据包是cpu向外设发出的命令. ixgbe驱动的rx软中断和tx软中断在同一个CPU上处理. htt ...