Python 数据分析—第七章 数据归整:清理、转换、合并、重塑
一、数据库风格的Dataframe合并
- import pandas as pd
- import numpy as np
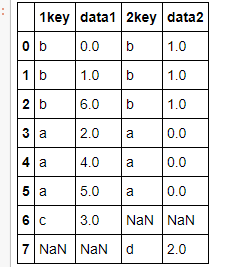
- df1 = pd.DataFrame({'1key':['b','b','a','c','a','a','b'],
- 'data1':np.arange(7)})
- df2 = pd.DataFrame({'2key':['a','b','d'],
- 'data2':np.arange(3)})
- df1
- df2


- pd.merge(df1,df2,left_on='1key',right_on = '2key',how='outer')
- #how还可以选择left right inner 还有一个参数是suffixes对于重复的名字处理 suffixes = ('_left','_right')
- #有时候是通过index连接的这里用left_index = True right_index = True
- #可以通过两个键来做merge
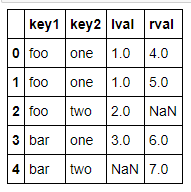
- pd.merge(left,right,on=['key1','key2'],how='outer')
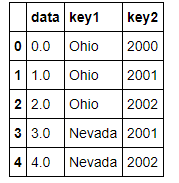
- lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
- 'key2': [2000, 2001, 2002, 2001, 2002],
- 'data': np.arange(5.)})
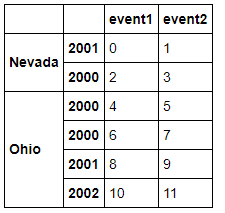
- righth = pd.DataFrame(np.arange(12).reshape((6, 2)),
- index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
- [2001, 2000, 2000, 2000, 2001, 2002]],
- columns=['event1', 'event2'])
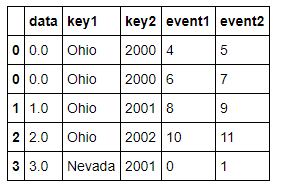
- lefth
- righth
- #多重索引的合并,需要指定多个值
- pd.merge(lefth,righth,left_on=['key1','key2'],right_index=True)
二、轴向连接
- s1 = pd.Series([0, 1], index=['a', 'b'])
- s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
- s3 = pd.Series([5, 6], index=['f', 'g'])
- pd.concat([s1,s2,s3])
- pd.concat([s1,s2,s3],axis=1)


- s4 = pd.concat([s1*5,s3])
- s4
- pd.concat([s1,s4],axis=1)
- pd.concat([s1,s4],axis=1,join='inner')
通过join来选择拼接模式,其实这个就跟merge差不多


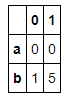
- pd.concat([s1,s2,s4],keys=['one','two','three'])
pd.concat([s1,s2,s4],axis = 1,keys=['one','two','three'])
pd.concat({'one':s1,'two':s2,'three':s3},axis = 1) #这个结果跟上面那个一样的!
这个可以增加一个层次化索引,这个跟你axis有关系,

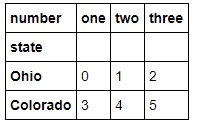
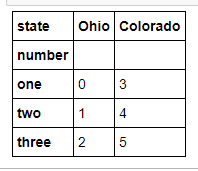
- data = pd.DataFrame(np.arange(6).reshape((2, 3)),
- index=pd.Index(['Ohio', 'Colorado'], name='state'),
- columns=pd.Index(['one', 'two', 'three'], name='number'))
- data
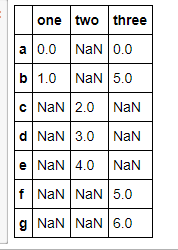
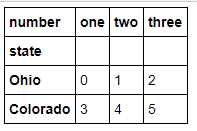
- data.stack()
- temp = data.stack()
- temp.unstack(0)
- temp.unstack() #后面跟的数字看看差别就知道,其实这样就相当于装置.T

数据转换
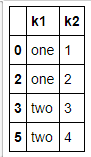
- data = pd.DataFrame({'k1': ['one'] * 3 + ['two'] * 4,
- 'k2': [1, 1, 2, 3, 3, 4, 4]})
- data
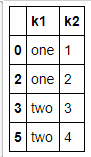
- data[~data.duplicated()]
- data.drop_duplicates() #里面可以指定列['k1'] 默认保留第一个,传入take_lase = True 保留最后一个
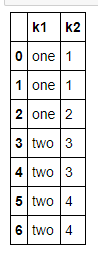
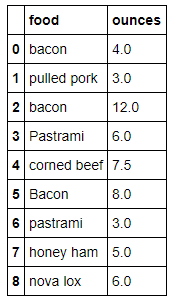
- data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon', 'Pastrami',
- 'corned beef', 'Bacon', 'pastrami', 'honey ham',
- 'nova lox'],
- 'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
- data
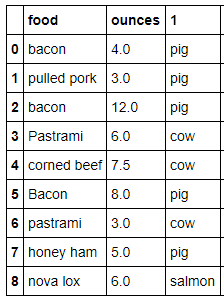
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
data['1'] = data['food'].map(str.lower).map(meat_to_animal)
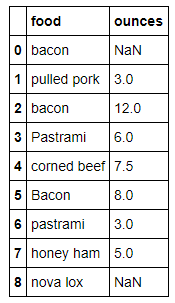
- data.replace(-999,np.nan) #data.replace([-999,1000],np.nan) 在dataframe上面也是一样的
- ages = np.arange(10,80,10)
- ages
- pd.cut(ages,bins=[10,30,50,71],right=False,labels=['a','b','c'])

- df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
- 'data1': range(6)})
- pd.get_dummies(df['key'])

Python 数据分析—第七章 数据归整:清理、转换、合并、重塑的更多相关文章
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 2003031121——浦娟——Python数据分析第七周作业——MySQL的安装及使用
项目 要求 课程班级博客链接 20级数据班(本) 作业要求链接 Python第七周作业 博客名称 2003031121--浦娟--Python数据分析第七周作业--MySQL的安装及使用 要求 每道题 ...
- python数据分析---第04章 NumPy基础:数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- 《利用python进行数据分析》读书笔记--第七章 数据规整化:清理、转换、合并、重塑(三)
http://www.cnblogs.com/batteryhp/p/5046433.html 5.示例:usda食品数据库 下面是一个具体的例子,书中最重要的就是例子. #-*- encoding: ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 进击的Python【第七章】:Python的高级应用(四)面向对象编程进阶
Python的高级应用(三)面向对象编程进阶 本章学习要点: 面向对象高级语法部分 静态方法.类方法.属性方法 类的特殊方法 反射 异常处理 Socket开发基础 一.面向对象高级语法部分 静态方法 ...
- 进击的Python【第七章】:python各种类,反射,异常处理和socket基础
Python的高级应用(三)面向对象编程进阶 本章学习要点: 面向对象高级语法部分 静态方法.类方法.属性方法 类的特殊方法 反射 异常处理 Socket开发基础 一.面向对象高级语法部分 静态方法 ...
- Python笔记·第七章—— IO(文件)处理
一.文件处理简介 计算机系统分为:计算机硬件,操作系统,应用程序三部分. 我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知 ...
- Python数据分析:大众点评数据进行选址
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:砂糖侠 如果你处于想学Python或者正在学习Python,Pyth ...
随机推荐
- Idea2016远程调试Java项目
一.在IDEA中配置远程tomcat 1.打开配置页面 选择"+" → "Tomcat Server" → "Remote" 填写名称和目标 ...
- python覆盖率统计
啦啦啦,最近在跟离线脚本写自动化,真麻烦呀~ 离线任务是python写的,自动化写完了,就得统计覆盖率了. coverage.py是一个用来统计python程序代码覆盖率的工具.网上有很多资料,使用起 ...
- Tkinter place() 方法
Python GUI - Tkinter place() 方法的使用例子: 这个的几何管理器组织放置在一个特定的位置,在他们的父widget部件. 语法: widget.place( place_ ...
- C++ primer plus
给cout指针,默认打印指针地址,但如果指针的类型的char*,将打印指向的字符串,如果要显示的是字符串的地址,将指针强制转换为另一种类型 char* animal cout << ani ...
- C# 重构
重构是在编写代码后在不更改代码的外部行为的前提下通过更改代码的内部结构来改进代码的过程. 一.何时需要重构 1.代码中存在重复的代码: 如果类中有重复的代码块,需将其提炼出一个新的独立方法,如果是不同 ...
- t讯src的一点小秘密
1.腾讯网首页发表评论未做限制 风险url:http://coral.qq.com/2774166934 使用burp的intruder模块生成payload 未做任何限制导致可批量提交大量的评论…… ...
- jbpm角色审批
可分配是一个部门或角色组,也可以选择一个表达式操作,提交任务时可以根据权限过滤这个部门或组的用户中选择一个可操作用户 <task name="审核"> ...
- overflow与underflow
是新近的firefox浏览器中支持overflow, underflow这两个事件,当某一元素的大小超出父元素的显示范围就会触发overflow事件,如果从超出显示再变回不超出的状态则触发underf ...
- 封装basedao及动态创建新类型的java数组
package com.huawei.base; import java.io.Serializable;import java.lang.reflect.Array;import java.lang ...
- node模块示例
来源于慕课网课程:http://www.imooc.com/video/6701 (视频) 模块的流程图如下: 做一个学校的模块示例 建一个学生的js studet.js function add(s ...