hadoop入门手册5:Hadoop【2.7.1】初级入门之命令:文件系统shell2
问题导读
1.改变hdfs文件的权限,需要修改哪个配置文件?
2.获取一个文件的或则目录的权限,哪个命令可以实现?
3.哪个命令可以实现设置访问控制列表(ACL)的文件和目录?

接上篇:
Hadoop【2.7.1】初级入门之命令:文件系统shell1
http://www.aboutyun.com/thread-15824-1-1.html
getfacl
用法: hadoop fs -getfacl [-R] <path>
显示访问控制列表(ACL)的文件和目录. 如果一个目录有默认的ACL, getfacl 也显示默认的ACL.
选项:
- -R: 递归目录和列出所有文件的ACLs.
- path: 文件或目录列表。
例子:
- hadoop fs -getfacl /file
- hadoop fs -getfacl -R /dir
返回代码:
返回 0成功返回 非0 错误
<ignore_js_op>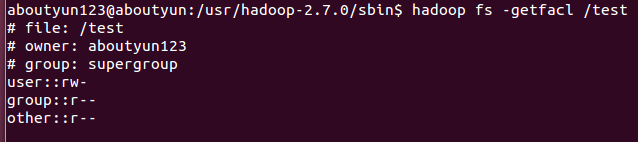
getfattr
用法: hadoop fs -getfattr [-R] -n name | -d [-e en] <path>
显示文件和目录扩展属性名字和值[如果有的话]
选项:
- -R: 递归显示文件和目录属性.
- -n name: Dump the named extended attribute value.
- -d: Dump all extended attribute values associated with pathname.
- -e encoding: 检索后的值进行编码。 有效的编码是 “text”, “hex”, and “base64”. 值编码作为文本字符串是用双引号括起来的(“),
值编码作为16进制和64进制,前缀分别为 0x 和 0s
- path: 文件或则目录
例子:
- hadoop fs -getfattr -d /file
- hadoop fs -getfattr -R -n user.myAttr /dir
返回代码:
返回 0成功返回 非0 错误
getmerge
用法: hadoop fs -getmerge <src> <localdst> [addnl]
源目录和目标文件作为输入和连接文件合并到本地目标文件。addnl选项可以设置在文件末尾添加一个换行符。
help
用法: hadoop fs -help
返回使用输出。
ls
用法: hadoop fs -ls [-d] [-h] [-R] [-t] [-S] [-r] [-u] <args>
选项:
- -d: 目录被列为纯文件。
- -h: 文件格式变为易读 (例如 67108864显示 64.0m).
- -R: 递归子目录列表中。
- -t: 按修改时间排序输出(最近一次)。
- -S: 按文件大小排序输出。
- -r: 倒序排序
- -u: 对使用时间显示和排序而不是修改时间
文件返回下面信息:
|
1
2
|
permissions number_of_replicas userid groupid filesize modification_date modification_time filename权限 副本数 用户名 所属组 文件大小 修改日期 修改时间 文件名 |
目录返回下面信息
权限 用户 所属组 修改日期 修改时间 目录名
目录内的文件默认按文件名排序
例子:
- hadoop fs -ls /user/hadoop/file1
退出代码:
返回0成功,返回-1错误
lsr
用法: hadoop fs -lsr <args>
ls递归
注意: 这个命令被启用的,替换为hadoop fs -ls -R
mkdir
用法: hadoop fs -mkdir [-p] <paths>
以URI的路径作为参数并创建目录。
选项:
- -p 选项与Linux -p功能一样,会创建父目录
例子:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://nn1.example.com/user/hadoop/dir hdfs://nn2.example.com/user/hadoop/dir
退出代码:
返回0成功,-1错误
moveFromLocal
用法: hadoop fs -moveFromLocal <localsrc> <dst>
类似put命令,但是它是本地源文件复制后被删除
moveToLocal
用法: hadoop fs -moveToLocal [-crc] <src> <dst>
显示 “Not implemented yet” 消息
mv
用法: hadoop fs -mv URI [URI ...] <dest>移动文件,这个命令允许移动多个文件到某个目录
例子:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://nn.example.com/file1 hdfs://nn.example.com/file2 hdfs://nn.example.com/file3 hdfs://nn.example.com/dir1
退出代码:
返回0成功,-1错误
put
用法: hadoop fs -put <localsrc> ... <dst>
复制单个或则多个源文件到目标系统文件。从stdin读取输入并写入到目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -put - hdfs://nn.example.com/hadoop/hadoopfile 从stdin读取输入。
退出代码:
返回0成功,-1错误
renameSnapshot
See HDFS Snapshots Guide.
rm
用法: hadoop fs -rm [-f] [-r |-R] [-skipTrash] URI [URI ...]
删除指定的参数文件。
选项:
- -f 选项 如果该文件不存在,则该选项将不显示诊断信息或修改退出状态以反映错误。
- -R选项递归删除目录下任何内容
- -r与-R效果一样
- -skipTrash选项绕过垃圾回收器,如果启用,将会立即删除指定文件。这是非常有用对于超过配额的目录
例子:
- hadoop fs -rm hdfs://nn.example.com/file /user/hadoop/emptydir
退出代码:
返回0成功,-1错误
rmdir
用法: hadoop fs -rmdir [--ignore-fail-on-non-empty] URI [URI ...]
删除目录
选项:
- --ignore-fail-on-non-empty: 当使用通配符,一个目录还包含文件,不会失败.
例子:
- hadoop fs -rmdir /user/hadoop/emptydir
rmr
用法: hadoop fs -rmr [-skipTrash] URI [URI ...]
递归删除
说明:这个命令被弃用了,而是使用hadoop fs -rm -r
setfacl
用法: hadoop fs -setfacl [-R] [-b |-k -m |-x <acl_spec> <path>] |[--set <acl_spec> <path>]
设置访问控制列表(ACL)的文件和目录。
选项:
- -b:移除所有除了基本的ACL条目。用户、组和其他的条目被保留为与权限位的兼容性。
- -k:删除默认的ACL。
- -R: 递归应用于所有文件和目录的操作。
- -m:修改ACL。新的项目添加到ACL,并保留现有的条目。
- -x: 删除指定的ACL条目。其他保留ACL条目。
- --set:完全替换ACL,丢弃所有现有的条目。acl_spec必须包括用户,组,和其他有权限位的兼容性。
- acl_spec:逗号分隔的ACL条目列表。
- path:修改文件或目录。
例子:
- hadoop fs -setfacl -m user:hadoop:rw- /file
- hadoop fs -setfacl -x user:hadoop /file
- hadoop fs -setfacl -b /file
- hadoop fs -setfacl -k /dir
- hadoop fs -setfacl --set user::rw-,user:hadoop:rw-,group::r--,other::r-- /file
- hadoop fs -setfacl -R -m user:hadoop:r-x /dir
- hadoop fs -setfacl -m default:user:hadoop:r-x /dir
退出代码:
返回0成功,非0错误
以上需要开启acl:
开启acls,配置hdfs-site.xml
|
1
2
3
4
5
|
vi etc/hadoop/hdfs-site.xml<property> <name>dfs.namenode.acls.enabled</name> <value>true</value></property> |
setfattr
用法: hadoop fs -setfattr -n name [-v value] | -x name <path>
设置一个文件或目录的扩展属性名和值。
选项:
-b: 移除所有的条目除了基本的ACL条目。用户、组和其他的条目被保留为与权限位的兼容性。
-n name:扩展属性名。
-v value:扩展属性值。有三种不同编码值,如果该参数是用双引号括起来的,则该值是引号内的字符串。如果参数是前缀0x或0X,然后作为一个十六进制数。如果参数从0或0,然后作为一个base64编码。
-x name: 移除所有属性值
path: 文件或则路径
例子:
- hadoop fs -setfattr -n user.myAttr -v myValue /file
- hadoop fs -setfattr -n user.noValue /file
- hadoop fs -setfattr -x user.myAttr /file
退出代码:
返回0成功,非0错误
setrep
用法: hadoop fs -setrep [-R] [-w] <numReplicas> <path>
更改文件的备份. 如果是一个目录,会递归改变目录下文件的备份。
选项:
-w标识,要求备份完成,这可能需要很长时间。
-R标识,是为了兼容,没有实际效果
例子:
- hadoop fs -setrep -w 3 /user/hadoop/dir1
退出代码:
返回0成功,非0错误
stat
用法: hadoop fs -stat [format] <path> ...按指定格式打印文件/目录的打印统计。
格式接受文件块 (%b), 类型 (%F), groutp拥有者 (%g), 名字 (%n), block size (%o), replication (%r), 用户拥有者(%u), 修改日期 (%y, %Y). %y 显示 UTC 日期如 “yyyy-MM-dd HH:mm:ss” 和 %Y 1970年1月1日以来显示毫秒UTC. 如果没有指定, 默认使用%y.
例子:
- hadoop fs -stat "%F %u:%g %b %y %n" /file
退出代码:
返回0成功
返回-1错误
tail
用法: hadoop fs -tail [-f] URI
显示文件内容,最后千字节的文件发送到stdout,
选项:
- f选项将输出附加数据随着文件的增长,如同Unix
例子:
- hadoop fs -tail pathname
退出代码:
返回0成功
返回-1错误
test
用法: hadoop fs -test -[defsz] URI
选项:
-d:如果路径是一个目录,返回0
-e:如果路径已经存在,返回0
-f: 如果路径是一个文件,返回0
-s:如果路径不是空,返回0
-z:如果文件长度为0,返回0
例子:
- hadoop fs -test -e filename
text
用法: hadoop fs -text <src>
一个源文件,以文本格式输出文件。允许的格式是zip和textrecordinputstream。
touchz
用法: hadoop fs -touchz URI [URI ...]
创建一个零长度的文件。
例子:
- hadoop fs -touchz pathname
退出代码:返回0成功,-1error
truncate
用法: hadoop fs -truncate [-w] <length> <paths>
截断指定文件模式指定的长度匹配的所有文件。
选项:
-w 选项需要等待命令完成块恢复。如果没有-w选项,在恢复的过程中可能是未闭合的
例子:
- hadoop fs -truncate 55 /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -truncate -w 127 hdfs://nn1.example.com/user/hadoop/file1
usage
用法: hadoop fs -usage command
返回单个命令的帮助。
相关内容
hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
hadoop入门手册2:hadoop【2.7.1】【多节点】集群配置【必知配置知识2】
hadoop入门手册3:Hadoop【2.7.1】初级入门之命令指南
hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1
hadoop入门手册5:Hadoop【2.7.1】初级入门之命令:文件系统shell2
hadoop2.X使用手册1:通过web端口查看主节点、slave1节点及集群运行状态
http://www.aboutyun.com/thread-7712-1-1.html
hadoop入门手册5:Hadoop【2.7.1】初级入门之命令:文件系统shell2的更多相关文章
- hadoop入门手册4:Hadoop【2.7.1】初级入门之命令:文件系统shell1
问题导读1.Hadoop文件系统shell与Linux shell有哪些相似之处?2.如何改变文件所属组?3.如何改变hdfs的文件权限?4.如何查找hdfs文件,并且不区分大小写? 概述文件系统 ( ...
- hadoop入门手册3:Hadoop【2.7.1】初级入门之命令指南
问题导读1.hadoop daemonlog管理员命令的作用是什么?2.hadoop如何运行一个类,如何运行一个jar包?3.hadoop archive的作用是什么? 概述 hadoop命令被bin ...
- hadoop入门手册2:hadoop【2.7.1】【多节点】集群配置【必知配置知识2】
问题导读 1.如何实现检测NodeManagers健康?2.配置ssh互信的作用是什么?3.启动.停止hdfs有哪些方式? 上篇: hadoop[2.7.1][多节点]集群配置[必知配置知识1]htt ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...
- Spark入门——什么是Hadoop,为什么是Spark?
#Spark入门#这个系列课程,是综合于我从2017年3月分到今年7月份为止学习并使用Spark的使用心得感悟,暂定于每周更新,以后可能会上传讲课视频和PPT,目前先在博客园把稿子打好.注意:这只是一 ...
- 大数据入门第五天——离线计算之hadoop(下)hadoop-shell与HDFS的JavaAPI入门
一.Hadoop Shell命令 既然有官方文档,那当然先找到官方文档的参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/had ...
- Hadoop概念学习系列之Hadoop新手学习指导之入门需知(二十)
不多说,直接上干货! 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.从一开始什么都不懂,到能够搭建集群,开发.整个过程,只要有Linux基础,虚拟机化和java基础,其实hadoo ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- Hadoop学习笔记—6.Hadoop Eclipse插件的使用
开篇:Hadoop是一个强大的并行软件开发框架,它可以让任务在分布式集群上并行处理,从而提高执行效率.但是,它也有一些缺点,如编码.调试Hadoop程序的难度较大,这样的缺点直接导致开发人员入门门槛高 ...
随机推荐
- java_zlib_资料
1.网页资料 1.1.http://bbs.csdn.net/topics/190020986 1.2. http://cdn.verydemo.com/demo_c89_i166794.html h ...
- SSH密钥登陆免密码方法
原帖地址:http://ask.apelearn.com/question/798 用Putty实现A机器远程登陆B机器,具体实现请看链接:http://www.cnblogs.com/ImJerry ...
- 如何使移动web页面禁止横屏?
https://segmentfault.com/q/1010000005813183 一般只有移动版有这种需求,我们一般不去禁止,而是比例缩放,css实现,竖屏1rem = 9pt ,横屏1rem ...
- CSS之按钮过滤
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- django from验证组件
from django.shortcuts import render,redirect from django.forms import Form,fields class loginForm(Fo ...
- CSS布局框架 960GS
1.960GS 特点 小巧简单,功能单一(仅仅做排版的工作,其他东西靠自己.)(三个文件:reset.css,960.css,font.css) 界面宽960px,适合目前主流1/2以上显示器都满屏宽 ...
- MS SQL2008执行大脚本文件时,提示“内存不足”的解决办法
问题描述: 当客户服务器不允许直接备份时,往往通过导出数据库脚本的方式来部署-还原数据库, 但是当数据库导出脚本很大,用Microsoft SQL Server Management Studio执行 ...
- nyoj117——树状数组升级版(树状数组+离散化)
求逆序数 时间限制:2000 ms | 内存限制:65535 KB 难度:5 描述 在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么它们就称为一个逆序.一个排列中 ...
- angularJS---service
service ng的服务是这样定义的: Angular services are singletons objects or functions that carry out specific ta ...
- Linux服务器通过拷贝的方式安装多个tomcat
Tomcat占用资源少.运行速度快.安装配置简单,在个人开发中拥有广泛的使用者.很多人在使用中存在以下的误区:1.Tomcat必须通过eclipse启动2.Tomcat必须通过安装才能使用运行3.一台 ...