Apache Hive (二)Hive安装
转自:https://www.cnblogs.com/qingyunzong/p/8708057.html
Hive的下载
下载地址http://mirrors.hust.edu.cn/apache/
选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3
Hive的安装
1、使用MySQL做为Hive的元数据库,所以先安装MySQL。
MySql安装过程http://www.cnblogs.com/qingyunzong/p/8294876.html
2、上传Hive安装包

3、解压安装包
[hadoop@hadoop3 ~]$ tar -zxvf apache-hive-2.3.3-bin.tar.gz -C apps/
4、修改配置文件
配置文件所在目录apache-hive-2.3.3-bin/conf
[hadoop@hadoop3 apps]$ cd apache-hive-2.3.3-bin/
[hadoop@hadoop3 apache-hive-2.3.3-bin]$ ls
bin binary-package-licenses conf examples hcatalog jdbc lib LICENSE NOTICE RELEASE_NOTES.txt scripts
[hadoop@hadoop3 apache-hive-2.3.3-bin]$ cd conf/
[hadoop@hadoop3 conf]$ ls
beeline-log4j2.properties.template ivysettings.xml
hive-default.xml.template llap-cli-log4j2.properties.template
hive-env.sh.template llap-daemon-log4j2.properties.template
hive-exec-log4j2.properties.template parquet-logging.properties
hive-log4j2.properties.template
[hadoop@hadoop3 conf]$ pwd
/home/hadoop/apps/apache-hive-2.3.3-bin/conf
[hadoop@hadoop3 conf]$
新建hive-site.xml并添加以下内容
[hadoop@hadoop3 conf]$ touch hive-site.xml
[hadoop@hadoop3 conf]$ vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop1:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 为 localhost -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
以下可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
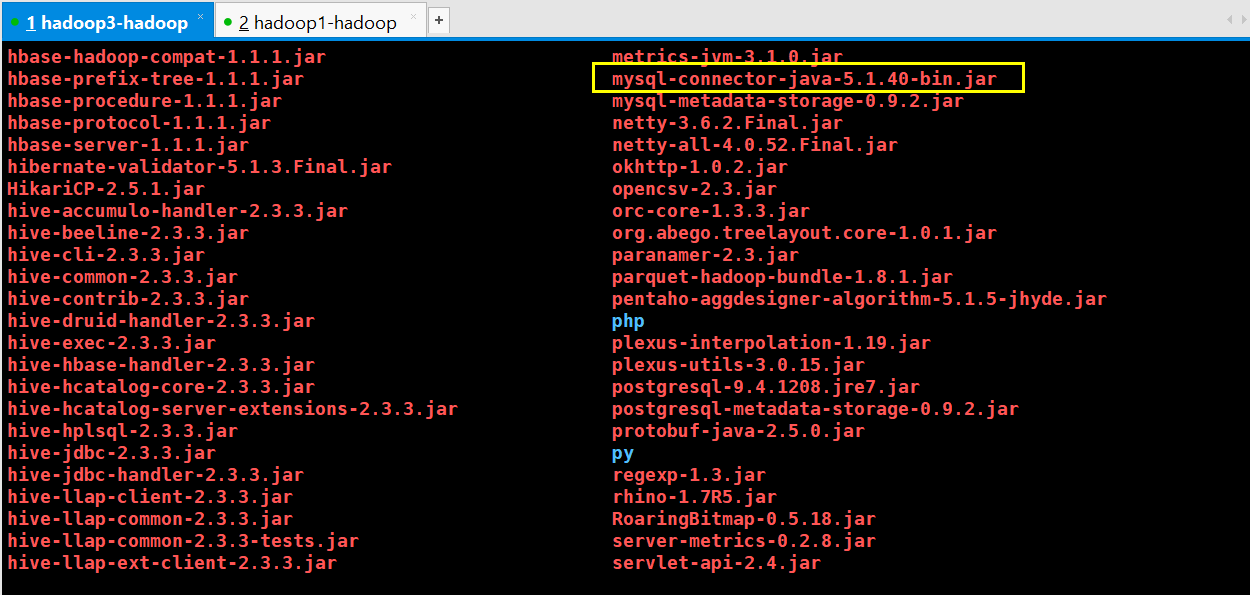
5、 一定要记得加入 MySQL 驱动包(mysql-connector-java-5.1.40-bin.jar)该 jar 包放置在 hive 的根路径下的 lib 目录
6、 安装完成,配置环境变量
[hadoop@hadoop3 lib]$ vi ~/.bashrc
#Hive
export HIVE_HOME=/home/hadoop/apps/apache-hive-2.3.3-bin
export PATH=$PATH:$HIVE_HOME/bin
使修改的配置文件立即生效
[hadoop@hadoop3 lib]$ source ~/.bashrc
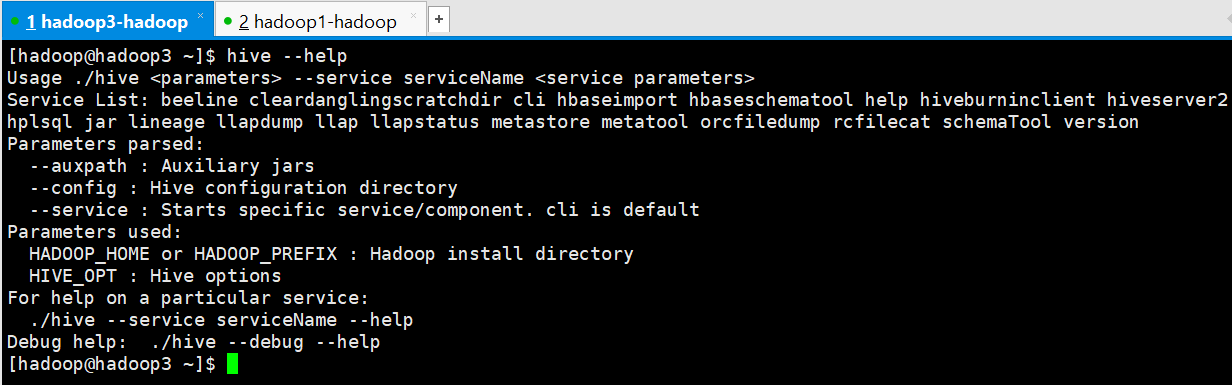
7、 验证 Hive 安装
[hadoop@hadoop3 ~]$ hive --help
Usage ./hive <parameters> --service serviceName <service parameters>
Service List: beeline cleardanglingscratchdir cli hbaseimport hbaseschematool help hiveburninclient hiveserver2 hplsql jar lineage llapdump llap llapstatus metastore metatool orcfiledump rcfilecat schemaTool version
Parameters parsed:
--auxpath : Auxiliary jars
--config : Hive configuration directory
--service : Starts specific service/component. cli is default
Parameters used:
HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory
HIVE_OPT : Hive options
For help on a particular service:
./hive --service serviceName --help
Debug help: ./hive --debug --help
[hadoop@hadoop3 ~]$
8、 初始化元数据库
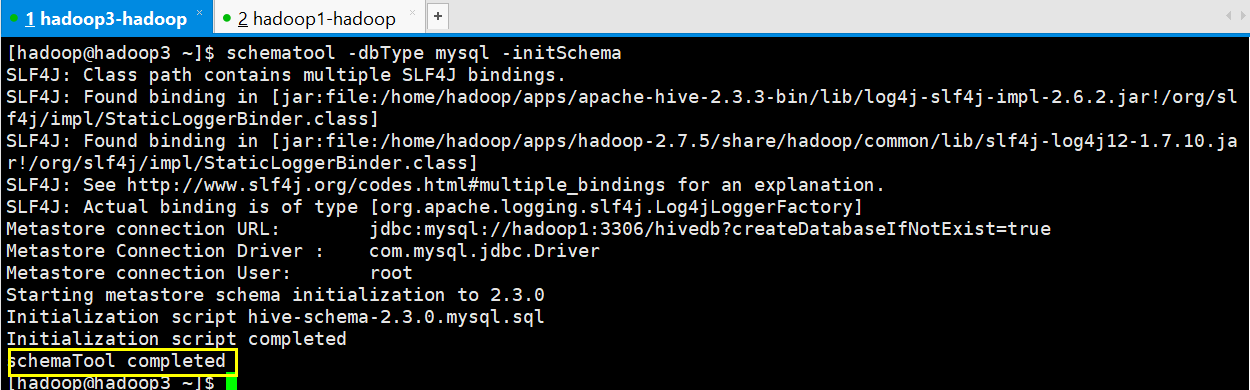
注意:当使用的 hive 是 2.x 之前的版本,不做初始化也是 OK 的,当 hive 第一次启动的 时候会自动进行初始化,只不过会不会生成足够多的元数据库中的表。在使用过程中会 慢慢生成。但最后进行初始化。如果使用的 2.x 版本的 Hive,那么就必须手动初始化元 数据库。使用命令:
[hadoop@hadoop3 ~]$ schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://hadoop1:3306/hivedb?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
[hadoop@hadoop3 ~]$
9、 启动 Hive 客户端
hive --service cli和hive效果一样
[hadoop@hadoop3 ~]$ hive --service cli
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
基本使用
现有一个文件student.txt,将其存入hive中,student.txt数据格式如下:
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS
95020,赵钱,男,21,IS
95003,王敏,女,22,MA
95004,张立,男,19,IS
95012,孙花,女,20,CS
95010,孔小涛,男,19,CS
95005,刘刚,男,18,MA
95006,孙庆,男,23,CS
95007,易思玲,女,19,MA
95008,李娜,女,18,CS
95021,周二,男,17,MA
95022,郑明,男,20,MA
95001,李勇,男,20,CS
95011,包小柏,男,18,MA
95009,梦圆圆,女,18,MA
95015,王君,男,18,MA
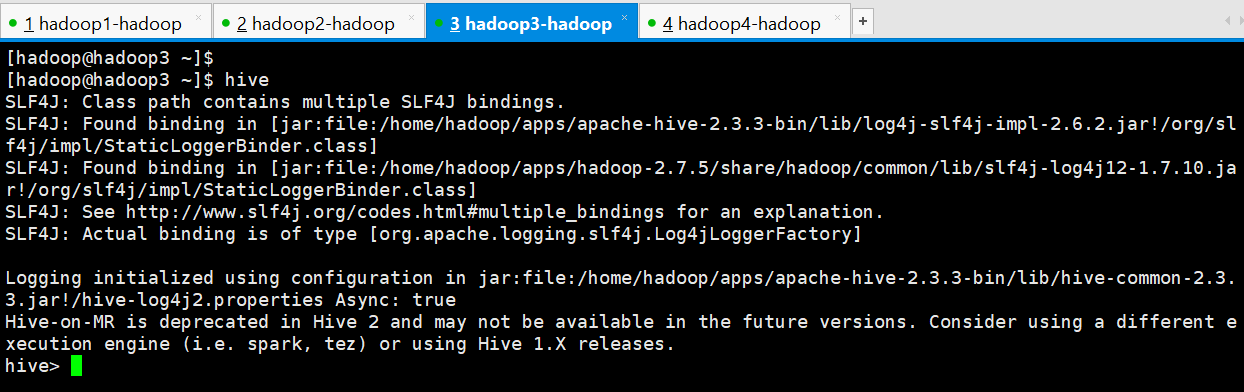
1、创建一个数据库myhive
hive> create database myhive;
OK
Time taken: 7.847 seconds
hive>
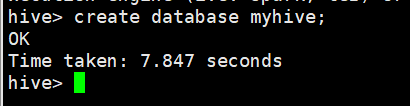
2、使用新的数据库myhive
hive> use myhive;
OK
Time taken: 0.047 seconds
hive>
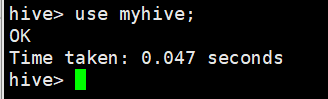
3、查看当前正在使用的数据库
hive> select current_database();
OK
myhive
Time taken: 0.728 seconds, Fetched: 1 row(s)
hive>
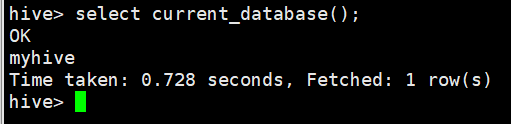
4、在数据库myhive创建一张student表
hive> create table student(id int, name string, sex string, age int, department string) row format delimited fields terminated by ",";
OK
Time taken: 0.718 seconds
hive>

5、往表中加载数据
hive> load data local inpath "/home/hadoop/student.txt" into table student;
Loading data to table myhive.student
OK
Time taken: 1.854 seconds
hive>

6、查询数据
hive> select * from student;
OK
95002 刘晨 女 19 IS
95017 王风娟 女 18 IS
95018 王一 女 19 IS
95013 冯伟 男 21 CS
95014 王小丽 女 19 CS
95019 邢小丽 女 19 IS
95020 赵钱 男 21 IS
95003 王敏 女 22 MA
95004 张立 男 19 IS
95012 孙花 女 20 CS
95010 孔小涛 男 19 CS
95005 刘刚 男 18 MA
95006 孙庆 男 23 CS
95007 易思玲 女 19 MA
95008 李娜 女 18 CS
95021 周二 男 17 MA
95022 郑明 男 20 MA
95001 李勇 男 20 CS
95011 包小柏 男 18 MA
95009 梦圆圆 女 18 MA
95015 王君 男 18 MA
Time taken: 2.455 seconds, Fetched: 21 row(s)
hive>
7、查看表结构
hive> desc student;
OK
id int
name string
sex string
age int
department string
Time taken: 0.102 seconds, Fetched: 5 row(s)
hive>
hive> desc extended student;
OK
id int
name string
sex string
age int
department string Detailed Table Information Table(tableName:student, dbName:myhive, owner:hadoop, createTime:1522750487, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null), FieldSchema(name:sex, type:string, comment:null), FieldSchema(name:age, type:int, comment:null), FieldSchema(name:department, type:string, comment:null)], location:hdfs://myha01/user/hive/warehouse/myhive.db/student, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=,, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{transient_lastDdlTime=1522750695, totalSize=523, numRows=0, rawDataSize=0, numFiles=1}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE, rewriteEnabled:false)
Time taken: 0.127 seconds, Fetched: 7 row(s)
hive>
hive> desc formatted student;
OK
# col_name data_type comment id int
name string
sex string
age int
department string # Detailed Table Information
Database: myhive
Owner: hadoop
CreateTime: Tue Apr 03 18:14:47 CST 2018
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://myha01/user/hive/warehouse/myhive.db/student
Table Type: MANAGED_TABLE
Table Parameters:
numFiles 1
numRows 0
rawDataSize 0
totalSize 523
transient_lastDdlTime 1522750695 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 0.13 seconds, Fetched: 34 row(s)
hive>
Apache Hive (二)Hive安装的更多相关文章
- Apache Hive 简介及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. 主要用途:用来 ...
- Hive学习笔记(二)—— 安装配置
Hive安装配置及基本操作 1. Hive安装及配置 (1). 上传文件到Hadoop102节点,解压到/opt/moudle (2). 修改/opt/module/hive/conf目录下的hive ...
- Hive数据仓库工具安装
一.Hive介绍 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单SQL查询功能,SQL语句转换为MapReduce任务进行运行. 优点是可以通过类S ...
- Hive(2)-Hive的安装,使用Mysql替换derby,以及一丢丢基本的HQL
一. Hive下载 1. Hive官网地址 http://hive.apache.org/ 2. 文档查看地址 https://cwiki.apache.org/confluence/display/ ...
- Hive 教程(一)-安装与配置解析
安装就安装 ,不扯其他的 hive 依赖 在 hive 安装前必须具备如下条件 1. 一个可连接的关系型数据库,如 Mysql,postgresql 等,用于存储元数据 2. hadoop,并启动 h ...
- Hive集成HBase;安装pig
Hive集成HBase 配置 将hive的lib/中的HBase.jar包用实际安装的Hbase的jar包替换掉 cd /opt/hive/lib/ ls hbase-0.94.2* rm -rf ...
- Hive介绍、安装(转)
1.Hive介绍 1.1 Hive介绍 Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据.它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语 ...
- 【转】 hive简介,安装 配置常见问题和例子
原文来自: http://blog.csdn.net/zhumin726/article/details/8027802 1 HIVE概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化 ...
- HA分布式集群二hive配置
一,概念 hive:是一种数据仓库,数据储存在:hdfs上,hsql是由替换简单的map-reduce,hive通过mysql来记录映射数据 二,安装 1,mysql安装: 1,检测是否有mariad ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
随机推荐
- BZOJ1725,POJ3254 [Usaco2006 Nov]Corn Fields牧场的安排
题意 Farmer John新买了一块长方形的牧场,这块牧场被划分成M列N行\((1 \leq M \leq 12, 1 \leq N \leq 12)\),每一格都是一块正方形的土地.FJ打算在牧场 ...
- jeecg选择按钮带入其他单据值
前端的标签 <input class="inputxt" id="fshimian" name="fshimian" ignore=& ...
- Unit05: 实战技巧 、 资费列表 、 拦截器
Unit05: 过滤器解决表单写中文乱码.拦截器 1. 使用过滤器解决表单中文参数值乱码问题 注意: a. 表单提交方式必须为POST. b. 过滤器的编码应该与浏览器端设置的编码一致. 2. 拦截器 ...
- (转)Inno Setup入门(十六)——Inno Setup类参考(2)
本文转载自:http://blog.csdn.net/yushanddddfenghailin/article/details/17250967 这里将接着在前面的基础上介绍如何在自定义页面上添加按钮 ...
- java代码-----String数组进行排序。是英文的字符串
总结:主要是方法不同了.是compareTo()方法比较字符串大小 package com.s.x; import java.util.Arrays; public class Jay { publi ...
- python 将html实体转回去
参考资料: http://www.360doc.com/content/17/0620/16/44530822_664927373.shtml https://blog.csdn.net/guzhou ...
- linux环境下搭建MySQL
linux下搭建mysql的方式很多,网上也详解了很多种搭建方式,有直接yum的.有rpm的..总之,“坑”是层出不穷,有相关文件依赖性.权限.GPG keys等等. 本人也在今天搭建了一下.是出“坑 ...
- node+express+socket.io制作一个聊天室功能
首先是下载包: npm install express npm install socket.io 建立文件: 服务器端代码:server.js var http=require("http ...
- 【POJ】2329 Nearest number - 2(搜索)
题目 传送门:QWQ 分析 在dp分类里做的,然而并不会$ O(n^3) $ 的$ dp $,怒写一发搜索. 看起来是$ O(n^4) $,但仔细分析了一下好像还挺靠谱的? poj挂了,没在poj交, ...
- 浅谈PHP面向对象编程(四、类常量和静态成员)
4.0 类常量和静态成员 通过上几篇博客我们了解到,类在实例化对象时,该对象中的成员只被当前对象所有.如果希望在类中定义的成员被所有实例共享. 此时可以使用类常量或静态成员来实现,接下来将针对类常量和 ...