scrapy抓取小说
用scrapy建立一个project,名字为Spider
scrapy startproject Spider
因为之前一直用的是电脑自带的python版本,所以在安装scrapy时,有很多问题,也没有装成功,所以就重新给本机安装了一个python3.+,然后安装scrapy和其他的库。新建的Spider文件夹结构如图
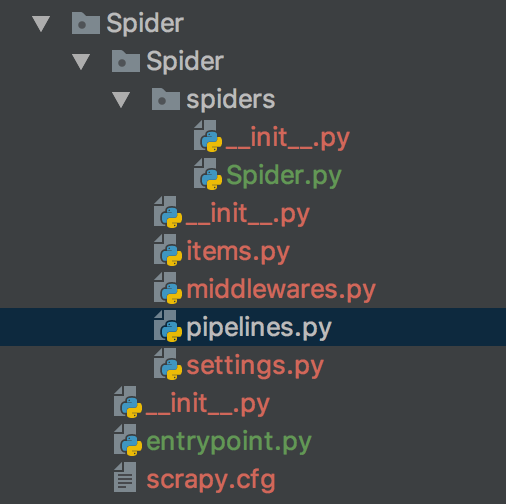
其中Spider.py 是spider程序代码
items.py 文件中定义一些字段,这些字段用来临时存储你需要保存的数据。方便后面保存数据到其他地方,比如数据库 或者 本地文本之类的。
middlewares.py 是一个下载中间件
pipelines.py 中存储自己的数据,我们需要将这些爬取到数据存储到数据库当中
settings.py 是一些设置,比如mysql、mongodb、代理ip
entrypoint.py
然后我是根据教程抓取了dingdian小说网站的所有小说的信息,初始调试的时候,遇见类似下面提示的错误
DEBUG: Crawled (403) <GET http://zipru.to/robots.txt> (referer: None) ['partial']
然后在settings.py中添加了user-Agent,然后就没有出现下面的403了,这是因为这个文件中规定了本站点允许的爬虫机器爬取的范围(比如你不想让百度爬取你的页面,就可以通过robot来限制),因为默认scrapy遵守robot协议,所以会先请求这个文件查看自己的权限,而我们现在访问这个url得到
DEBUG: Crawled (403) <GET http://zipru.to/robots.txt> (referer: None) ['partial']
然后在初始调试的时候设置了固定的一页进行数据抓取,然后就遇见了类似下图的错误
2016-01-13 15:01:39 [scrapy] DEBUG: Filtered duplicate request: - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
然后百度得,在scrapy engine把request给scheduler后,scheduler会给request去重,所以对相同的url不能同时访问两次,所以在修改了抓取的页面的url后,就不会出现上述错误。
然后代码写的很随性,在抓取的时候顶点小说会封ip,因为我没有对数据抓取settings.py中设置dewnload_delay,所以会有封ip,想要用代理ip,但是在网上找的代理ip总是连接不上,所以就放弃了。
Spider.py
#-*-coding:utf-8-*- import re
import scrapy
import time
from bs4 import BeautifulSoup
from scrapy.http import Request
from Spider.items import SpiderItem class spider(scrapy.Spider):
name = 'Spider'
allowed_domains = ['x23us.com']
bash_url = 'http://www.x23us.com/class/'
bashurl = '.html' def start_requests(self):
for i in range(1, 11):
url = self.bash_url + str(i) + '_1' + self.bashurl
print(url)
yield Request(url, self.parse) def parse(self, response):
soup = BeautifulSoup(response.text,'lxml')
max_nums = soup.find_all('div',class_ = 'pagelink')[0]
max_num = max_nums.find_all('a')[-1].get_text()
print(max_num)
bashurl = str(response.url)[:-7]
for num in range(1, int(max_num) + 1):
url = bashurl + '_' + str(num) + self.bashurl
print(url)
yield Request(url, self.get_name) def get_name(self, response):
soup = BeautifulSoup(response.text,'lxml')
tds = soup.find_all('tr', bgcolor='#FFFFFF')
for td in tds:
novelname = td.find_all('a')[1].get_text()
novelurl = td.find_all('a')[1]['href']
author = td.find_all('td')[-4].get_text()
serialnumber = td.find_all('td')[-3].get_text()
last_update = td.find_all('td')[-2].get_text()
serialstatus = td.find_all('td')[-1].get_text()
print("%s %s %s %s %s %s"%(novelname,author,novelurl,serialnumber,last_update,serialstatus))
item = SpiderItem()
item['name'] = novelname
item['author'] = author
item['novelurl'] = novelurl
item['serialstatus'] = serialstatus
item['serialnumber'] = serialnumber
item['last_update'] = last_update
yield item
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class SpiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() #小说名
author = scrapy.Field() #作者名
novelurl = scrapy.Field() #小说地址
serialstatus = scrapy.Field() #状态
serialnumber = scrapy.Field() #连载字数
last_update = scrapy.Field() #文章上次更新时间
settings.py中添加的设置,因为在存储的时候,是将数据存储在本地的mongodb的test.novel中
BOT_NAME = 'Spider' SPIDER_MODULES = ['Spider.spiders']
NEWSPIDER_MODULE = 'Spider.spiders'
ITEM_PIPELINES = {
'Spider.pipelines.SpiderPipeline': 300,
}
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "test"
MONGODB_COLLECTION = "novel"
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log class SpiderPipeline(object):
def __init__(self):
connection=pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db=connection[settings['MONGODB_DB']]
self.collection=db[settings['MONGODB_COLLECTION']] def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem('Missing{0}!'.format(data))
if valid:
self.collection.insert(dict(item))
log.msg('question added to mongodb database!',
level=log.DEBUG, spider=spider)
return item
entrypoint.py
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'Spider'])
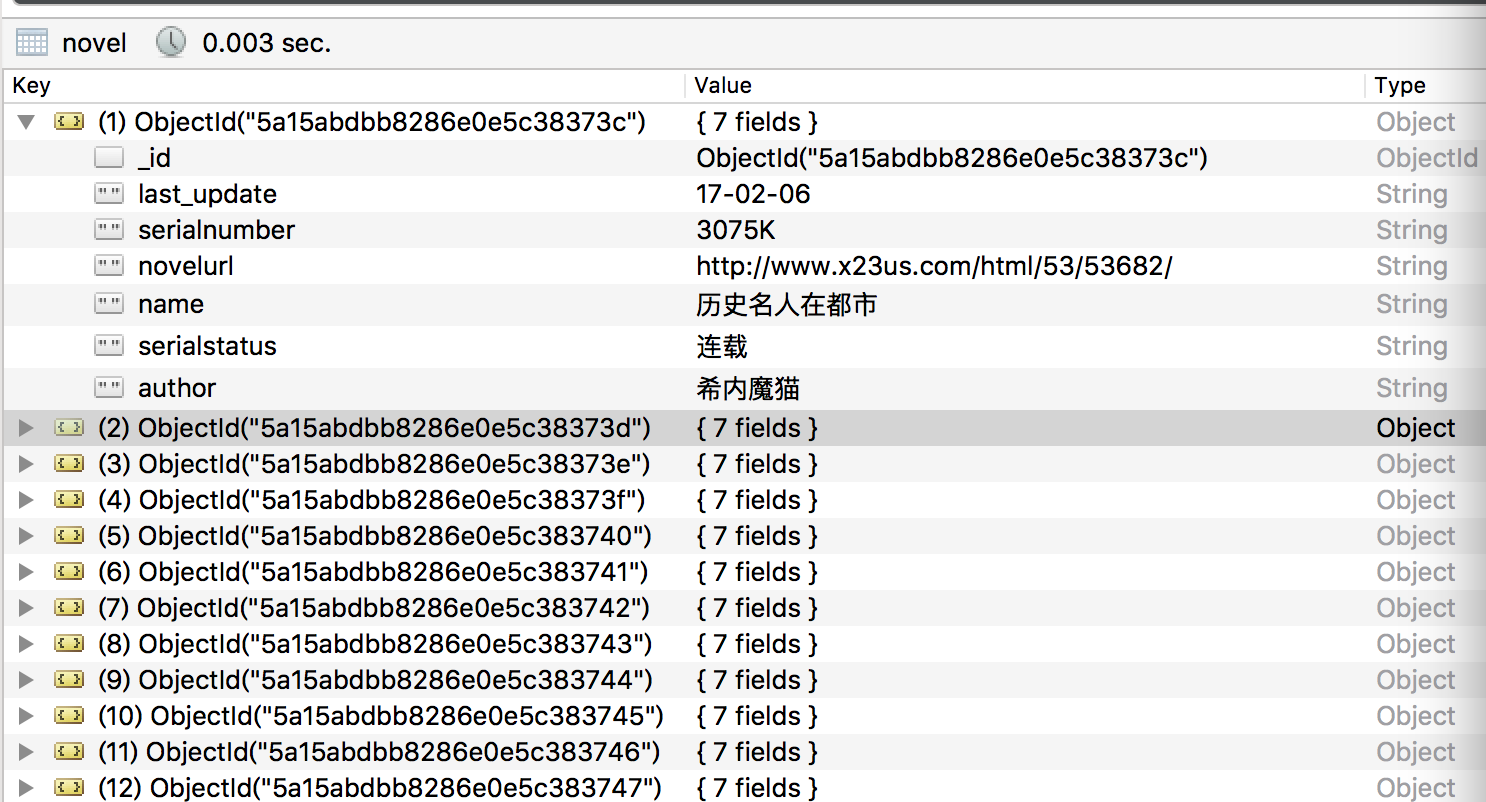
mongodb中的存储结构如图
在抓取数据的过程中,如果download将request的下载失败,那么会将request给scrapy engine,然后让scrapy engine稍后重新请求。
有当scheduler中没有任何request了,整个过程才会停止。
scrapy抓取小说的更多相关文章
- 通过Scrapy抓取QQ空间
毕业设计题目就是用Scrapy抓取QQ空间的数据,最近毕业设计弄完了,来总结以下: 首先是模拟登录的问题: 由于Tencent对模拟登录比较讨厌,各个防备,而本人能力有限,所以做的最简单的,手动登录后 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- C# 爬虫 抓取小说
心血来潮,想研究下爬虫,爬点小说. 通过百度选择了个小说网站,随便找了一本小书http://www.23us.so/files/article/html/13/13655/index.html. 1. ...
- C# 爬虫 正则、NSoup、HtmlAgilityPack、Jumony四种方式抓取小说
心血来潮,想爬点小说.通过百度选择了个小说网站,随便找了一本小说http://www.23us.so/files/article/html/13/13655/index.html. 1.分析html规 ...
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取的中文结果乱码解决办法
使用scrapy抓取的结果,中文默认是Unicode,无法显示中文. 中文默认是Unicode,如: \u5317\u4eac\u5927\u5b66 在setting文件中设置: FEED_EXPO ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
- 解决Scrapy抓取中文网页保存为json文件时中文不显示而是显示unicode的问题
注意:此方法跟之前保存成json文件的写法有少许不同之处,注意区分 情境再现: 使用scrapy抓取中文网页,得到的数据类型是unicode,在控制台输出的话也是显示unicode,如下所示 {'au ...
随机推荐
- mysql主从配置的过程
首先参考MySQL5.5官方手册 以下章节: 6.4节如何设置复制 13.6.1节 用于控制主服务器的SQL语句 13.6.2节 用于控制从服务器的SQL语句 6.8节 复制启动选项 6.5节 不同M ...
- 【bzoj2402】陶陶的难题II
Portal -->bzoj2402 Solution 这题的话,看到答案的形式想到分数规划(Portal -->[learning]) 套路一波,记当前二分的\(mid\)为\(\lam ...
- 【字符串】manacher算法
Definition 定义一个回文串为从字符串两侧向中心扫描时,左右指针指向得字符始终相同的字符串. 使用manacher算法可以在线性时间内求解出一个字符串的最长回文子串. Solution 考虑回 ...
- Linux之时间相关操作20170607
一.Linux常用时间相关函数 -asctime,ctime,getttimeofday,gmtime,localtime,mktime,settimeofday,time asctime ...
- form, table表示表格的时候有什么区别?
http://zhidao.baidu.com/link?url=1DFrMJlzV_fHSyGmKEi77ki6g2IrjrMfRGwVYNHL5Y8iJC9Diu2BoMGEiB3wbnkTCHm ...
- Codeforces 932.D Tree
D. Tree time limit per test 2 seconds memory limit per test 512 megabytes input standard input outpu ...
- CodeChef DGCD
You're given a tree on N vertices. Each vertex has a positive integer written on it, number on the i ...
- vue 一开始
项目安装 vue init webpack bibivue-router Y npm run dev
- 26 THINGS I LEARNED IN THE DEEP LEARNING SUMMER SCHOOL
26 THINGS I LEARNED IN THE DEEP LEARNING SUMMER SCHOOL In the beginning of August I got the chance t ...
- logstash 收集 IIS 日志实践
IIS日志示例: 2017-02-20 00:55:40 127.0.0.1 GET /MkWebAPI/swagger/ui/index - 80 - 127.0.0.1 Mozilla/5.0+( ...