c#抽取pdf文档标题(3)
上一篇介绍了整体流程以及利用库读取pdf内容形成字符集合。这篇着重介绍下,过滤规则,毕竟我们是使用规则过滤,最后得到标题的。
首先看归一化处理,什么是归一化呢?就是使结果始终处于0-1之间(包括0,1)。
private static double GetMark(BlockInfo block, double maxHeight, double maxWidth, double maxYSize, double maxXSize, double maxSpace)
{
double result = ; if (maxYSize > )
result += 0.4 * ((double)block.CharAveYSize / maxYSize); if (maxXSize > )
result += 0.3 * ((double)block.CharAveXSize / maxXSize); if (maxSpace > ) result += (block.CharAveSpace / maxSpace) * 0.1; if (maxHeight > ) result += (block.CharAveHeight / maxHeight) * 0.1; if (maxWidth > )
result += (block.CharAveWidth / maxWidth) * 0.1;
if (block.RepresentativeChar.IsBold) result += 0.1;
return result;
}
这段代码,就是给块打分的一个方法。它包含了投票思想以及归一处理问题的思想。对于一个块,我们从不同的角度,也就是不同方面的特征值给分,每个特征所占的权重是不同的。YSize权重:0.4,XSize权重:0.3,它们的分值是这样计算的:
权重*(块的平均特征值 / 文档中最大特征值),拿YSize来说,假如块的CharAveYSize=40,maxYSize=60,那么结果:0.4*(40/60)= 0.267。
在这里,我想说的是,特征一定要选正确,还有特征的权重也要相对正确,否则会影响到结果的匹配率。记得之前是以Space特征为主选取的,那时候还没有采用评分系统,经测试,提取标题的准确率在30%左右,后来,看了那个同事以前的代码,发现人家的代码写的如此简单,据说准确率在60%,“大道至简”,我就又重新找到核心属性,于是经过摸索,YSize这个属性相当重要,于是准确度到了70%左右。到最后,采用了评分机制,准确度到了85%左右,再经过努力,不断完善代码,准确度提升到了92%左右。有截图为证:
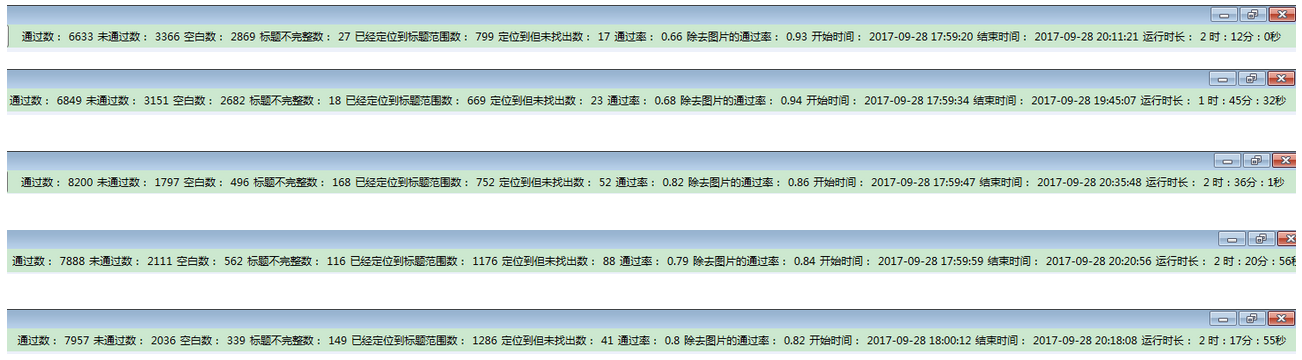
针对完全图片类型的pdf文档,我们现阶段不予处理。那么除了规则外,还有没有其它途径,来筛选标题呢?答案是肯定的,机器学习是当下一个热门领域,好了,我们下一篇就讨论这方面的话题。
c#抽取pdf文档标题(3)的更多相关文章
- c#抽取pdf文档标题——前言
由于工作的需要,研究c#抽取pdf文档标题有3个月了.这项工作是一项"伟大而艰巨"的任务.应该是我目前研究工作中最长的一次.我觉得在长时间忙碌后,应该找些时间,把自己的心路历程归纳 ...
- c#抽取pdf文档标题(1)
首先看看我的项目结构: 从上面的结果图中,我们可以看出,主要用了两个库:itextsharp.dll 和 pdfbox-1.8.9.dll,dll文件夹存放引用的库,handles文件夹存放抽取的处理 ...
- c#抽取pdf文档标题(2)
public class IETitle { public static List<WordInfo> WordsInfo = new List<WordInfo>(); pr ...
- c#抽取pdf文档标题(4)——机器学习以及决策树
我的一位同事告诉我,pdf抽取标题,用机器学习可以完美解决问题,抽取的准确率比较高.于是,我看了一些资料,就动起手来,实践了下. 我主要是根据以往历史块的特征生成一个决策树,然后利用这棵决策树,去判断 ...
- Python处理Excel和PDF文档
一.使用Python操作Excel Python来操作Excel文档以及如何利用Python语言的函数和表达式操纵Excel文档中的数据. 虽然微软公司本身提供了一些函数,我们可以使用这些函数操作Ex ...
- C#给PDF文档添加文本和图片页眉
页眉常用于显示文档的附加信息,我们可以在页眉中插入文本或者图形,例如,页码.日期.公司徽标.文档标题.文件名或作者名等等.那么我们如何以编程的方式添加页眉呢?今天,这篇文章向大家分享如何使用了免费组件 ...
- 将w3cplus网站中的文章页面提取并导出为pdf文档
最近在看一些关于CSS3方面的知识,主要是平时看到网页中有很多用CSS3实现的很炫的效果,所以就打算系统的学习一下.在网上找到很多的文章,但都没有一个好的整理性,比较凌乱.昨天看到w3cplus网站中 ...
- PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示解决方法
问题:PDF2SWF转换只有一页的PDF文档,在FlexPaper不显示! FlexPaper 与 PDF2SWF 结合是解决在线阅读PDF格式文件的问题的,多页的PDF文件转换可以正常显示,只有一页 ...
- 【PDF】java使用Itext生成pdf文档--详解
[API接口] 一.Itext简介 API地址:javadoc/index.html:如 D:/MyJAR/原JAR包/PDF/itext-5.5.3/itextpdf-5.5.3-javadoc/ ...
随机推荐
- JDK1.7源码分析01-Collection
同步发布:http://www.yuanrengu.com/index.php/20180221.html Java的集合类主要由两个接口派生而出:Collection和Map.Collection是 ...
- springMvc学习笔记一
什么是springmvc springmvc就是spring框架的一个模块 所以springmvc与spring之间无需通过中间整合层进行整合的. springmvc又是基于mvc的web框架 mv ...
- ASP.NET根据当前时间获取,本周,本月,本季度等时间段
DateTime dt = DateTime.Now; //当前时间 DateTime startWeek = dt.AddDays(1 - Convert.ToInt32(dt.DayOfWeek. ...
- js创建数组的三个方式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- MysqL 磁盘写入策略之innodb_flush_log_at_trx_commit
本文从参数含义,性能,安全角度阐述两个参数为不同的值时对db 性能,数据的影响,引擎是Innodb的前提下. 取值:0/1/2 innodb_flush_log_at_trx_commit=0,表示每 ...
- Qt 信号如何自动连接槽函数?
on_objectName_signal [static] void QMetaObject::connectSlotsByName(QObject *object) void on_<obje ...
- HZAU 1199: Little Red Riding Hood 01背包
题目链接:1199: Little Red Riding Hood 思路:dp(i)表示前i朵花能取得的最大价值,每一朵花有两种选择,摘与不摘,摘了第i朵花后第i-k到i+k的花全部枯萎,那么摘的话d ...
- react按需加载(getComponent优美写法),并指定输出模块名称解决缓存(getComponent与chunkFilename)
react配合webpack进行按需加载的方法很简单,Route的component改为getComponent,组件用require.ensure的方式获取,并在webpack中配置chunkFil ...
- Android开发Toast Notifications
Android开发Toast Notifications 关键类 Toast toast通知是一种在窗口表面弹出的消息.它只占用信息显示所需的空间,用户当前的activity仍保持可见并可交互.该通知 ...
- mysql 主从同步 mysql代理服务器
搭建mysql主从同步(实现数据自动备份)实例:把主机192.168.4.100的数据库配置为主机192.168.4.99的从数据库 主数据库服务器配置修改配置文件: [root@mysql ~]# ...