Scrapy爬虫框架第七讲【ITEM PIPELINE用法】
ITEM PIPELINE用法详解:
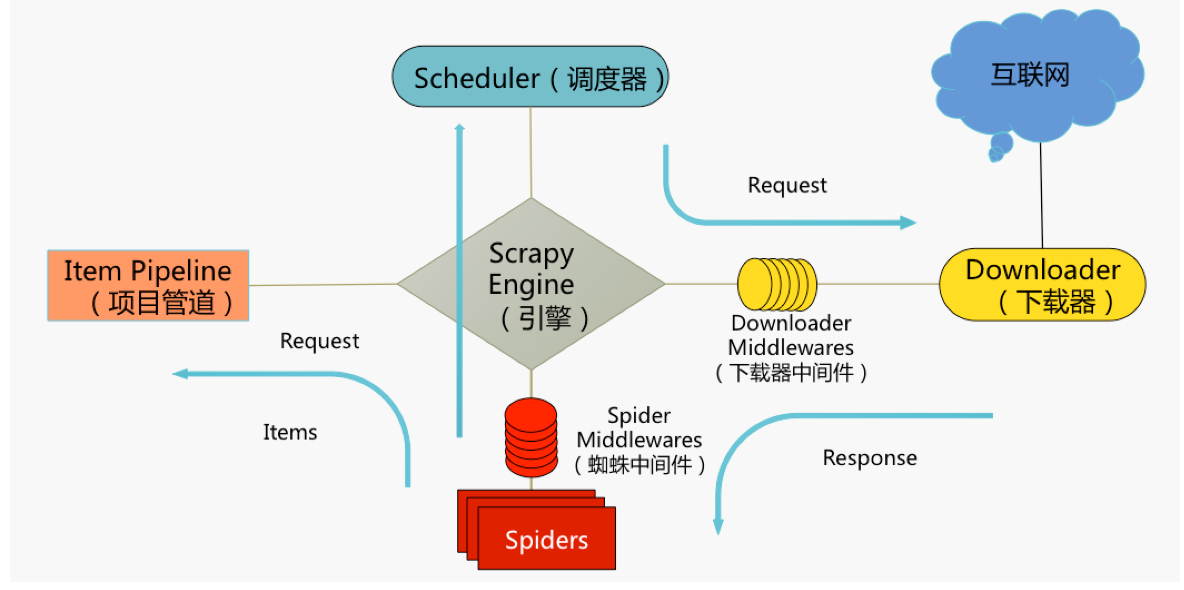
ITEM PIPELINE作用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 去重(并丢弃)【预防数据去重,真正去重是在url,即请求阶段做】
- 将爬取结果保存到数据库中

ITEM PIPELINE核心方法(4个)
(1)、open_spider(spider)
(2)、close_spider(spider)
(3)、from_crawler(cls,crawler)
(4)、process_item(item,spider)
下面小伙伴们我们依次来分析:
1、open_spider(spider) 【参数spider 即被开启的Spider对象】
该方法非必需,在Spider开启时被调用,主要做一些初始化操作,如连接数据库等
2、close_spider(spider)【参数spider 即被关闭的Spider对象】
该方法非必需,在Spider关闭时被调用,主要做一些如关闭数据库连接等收尾性质的工作
3、from_crawler(cls,crawler)【参数一:Class类 参数二:crawler对象】
该方法非必需,Spider启用时调用,早于open_spider()方法,是一个类方法,用@classmethod标识,它与__init__函有关,这里我们不详解(一般我们不对它进行修改)
4、process_item(item,spider)【参数一:被处理的Item对象 参数二:生成该Item的Spider对象】
该方法必需实现,定义的Item pipeline会默认调用该方法对Item进行处理,它返回Item类型的值或者抛出DropItem异常
实例分析(以下实例来自官网:https://doc.scrapy.org/en/latest/topics/item-pipeline.html)
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
代码分析:
首先定义了一个PricePipeline类
定义了增值税税率因子为1.15
主函数process_item方法实现了如下功能:判断Item中的price字段,如没计算增值税,则乘以1.15,并返回Item,否则直接抛弃
总结:该方法要么return item给后边的管道处理,要么抛出异常
数据去重
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
代码分析:
首先定义了一个DuplicatesPipeline类
这里比上面多了一个初始化函数__init__,set()---去重函数
主函数process_item方法首先判断item数据中的id是否重复,重复的就将其抛弃,否则就增加到id,然后传给下个管道
将数据写入文件
import json
class JsonWriterPipeline(object):
def open_spider(self, spider):
self.file = open('items.jl', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
代码分析:
首先我们定义了一个JsonWritePipeline类
定义了三个函数:
first:open_spider()在Spider开启时启用作用很简单即打开文件,准备写入数据
second:close_spider()在Spider关闭时启用作用也很简单即关闭文件
third(主要):process_items()作用如下首先将item转换为字典类型,在用json.dumps()序列化为json字符串格式,再写入文件,最后返回修改的item给下一个管道
综合实例
import pymongo
class MongoPipeline(object):
collection_name = 'scrapy_items'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert(dict(item))
return item
代码分析:
首先我们定义了一个MongoPipeline类
这里我们修改了初始化函数__init__,给出了存储到Mongodb的链接地址和数据库名称所以更改了from_crawler()工厂函数函数(生产它的对象),这里指定了链接地址和数据表名称
最后我们定义了三个函数:
first:open_spider()在Spider开启时启用作用是打开mongodb数据库
second:close_spider()在Spider关闭时启用作用是关闭数据库
third:process_items()作用如下在数据库中插入item
项目实战:(我们以58同城镇江房屋出租为例)抓取出租信息的标题、价格、详情页的url
我是在ubuntu16.04环境下跑的
启动终端并激活虚拟环境:source course_python3.5/bin/activate
创建一个新目录project:mkdir project
创建项目:scrapy startproject city58-----cd city58----创建爬虫(这里小伙伴们注意项目名不能与爬虫名重名)scrapy genspider city58_test
下面我们正式开始
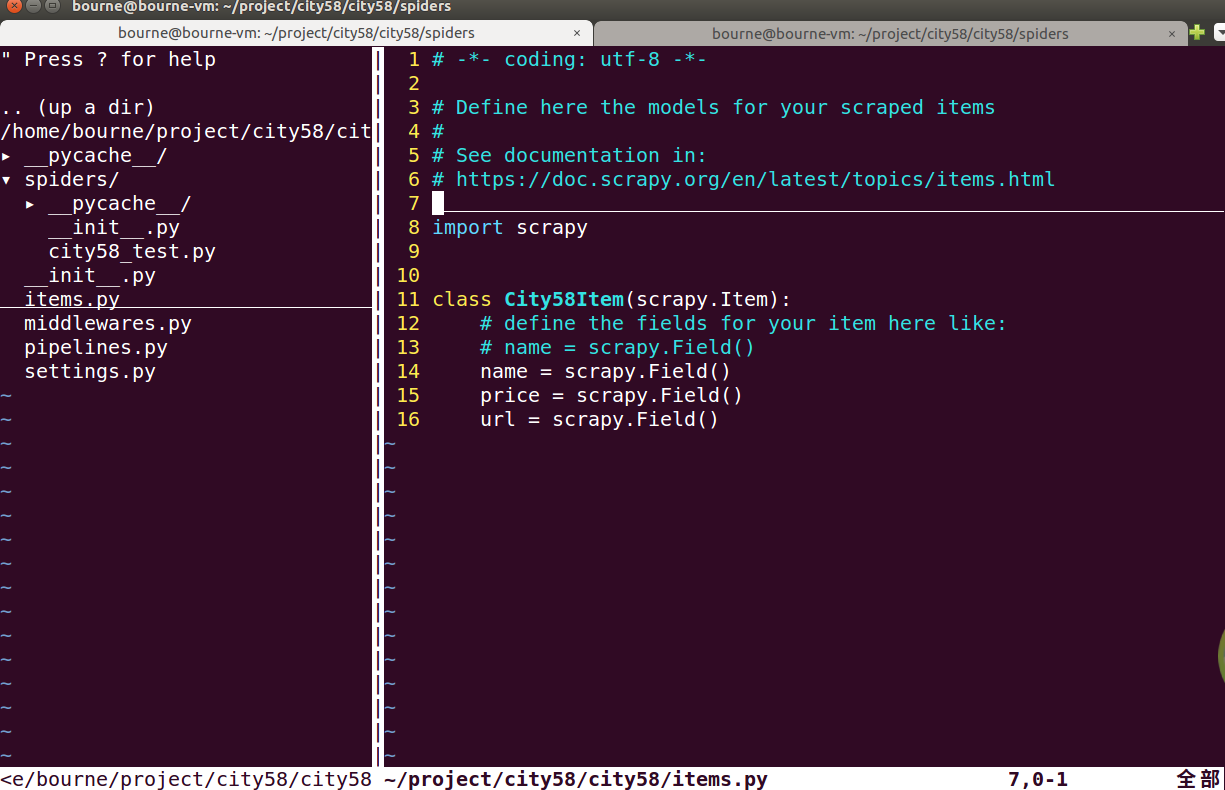
(1)、修改items.py
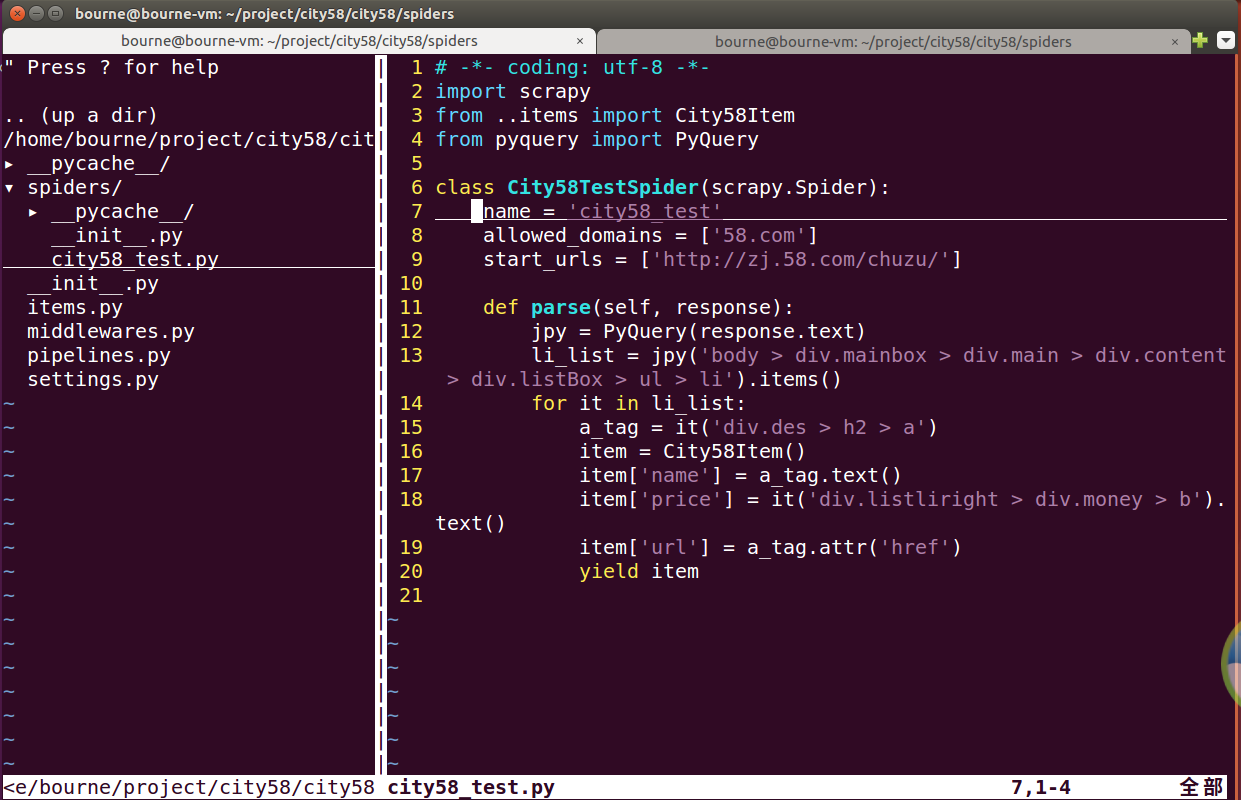
(2)修改city58_test.py文件(这里我们使用pyquery选择器)
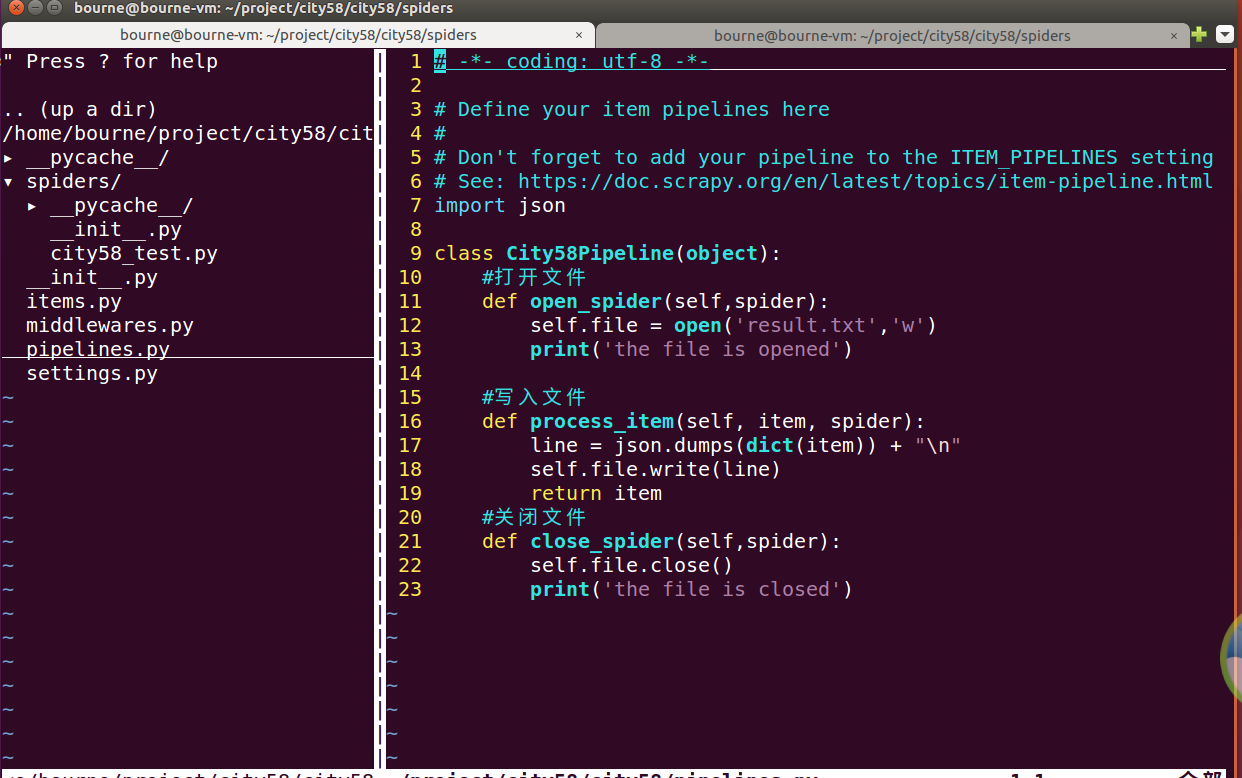
(3)、重点来了,修改pipelines.py文件,小伙伴们可参考上面的案例分析
(4)最后通过settings.py启动pipeline

这里向小伙伴们科普一个小知识点:后面的数字是优先级,数字越小,越优先执行
(5)项目运行结果(部分)----下次小伙伴们想了解出租信息可以找我,我帮你秒下。哈哈!
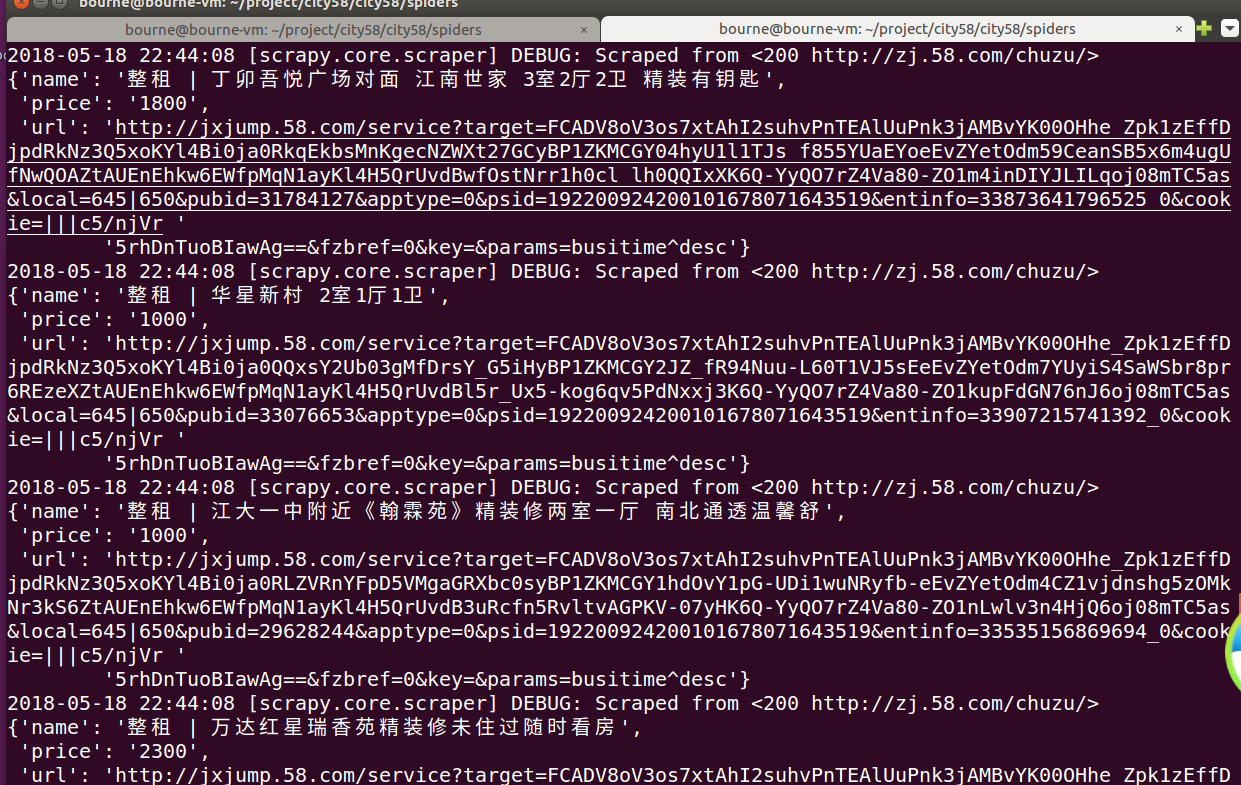
并且我们可以在同级目录下找到我们写入的文件
总结:
(1)、首先了解了管道的作用
(2)、掌握了核心的方法,其中特别是process_item()方法
(3)、最后我们通过实例和项目进行实战,后面我们会继续学习如何使用管道进行高级的操作,敬请期待,记得最后一定要在配置文件中开启Spider中间件
Scrapy爬虫框架第七讲【ITEM PIPELINE用法】的更多相关文章
- Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析: (1)选定起始人(即选择关注数和粉丝数较多的人--大V) (2)获取该大V的个人信息 (3)获取关注列表用户信息 (4)获取粉丝列表用户信息 (5)重复(2)(3)(4)步实现全知乎用户爬 ...
- Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html) Selecto ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
随机推荐
- PS图层混合算法之一(不透明度,正片叠底,颜色加深,颜色减淡)
下列公式中,A代表了上面图层像素的色彩值(A=像素值/255),B代表下面图层像素的色彩值(B=像素值/255),C代表了混合像素的色彩值(真实的结果像素值应该为255*C).该公式也应用于层蒙板. ...
- EBS R12安装升级(FRESH)(四)
7 升级Oracle数据库到11gR2 7.1 先打补丁7303030_zhs,9062910,8919489,8919489_ZHS ,9868229,10163753,11071569,97380 ...
- How tomcat works 读书笔记十五 Digester库 下
在这一节里我们说说ContextConfig这个类. 这个类在很早的时候我们就已经使用了(之前那个叫SimpleContextConfig),但是在之前它干的事情都很简单,就是吧context里的co ...
- MurmurHash
public int hash(byte[] data, int length, int seed) { int m = 0x5bd1e995; int r = 24; int ...
- C标准中关于空指针的那些事
1 C标准不保证用所有二进制位都为0的变量来表示空指针,但它保证空指针与任何对象或函数的指针都不相等,取地址操作符&永远也不会返回空指针: 2 C标准称在指针上下文中的"值为0的整形 ...
- Android平台的Swift—Kotlin
WeTest 导读 Kotlin 已经出来较长一段时间了,有些同学已经对Kotlin进行了深入的学习,甚至已经运用到了自己的项目当中,但是还有较多同学可能只是听过Kotlin或简单了解过,这篇文章的目 ...
- log4j日志的配置
在项目开发中,记录错误日志方便调试.便于发现系统运行过程中的错误.便于后期分析, 在java中,记录日志有很多种方式,比如说log4j log4j需要导入的包: commons-loggin.jar ...
- node_acl 路径通配
最近做一个基于nodejs的权限管理,查阅了一两天,发现大致是这样的: passportjs node-oauth rbac node_acl express_acl connect-roles 需求 ...
- java并发编程——通过ReentrantLock,Condition实现银行存取款
java.util.concurrent.locks包为锁和等待条件提供一个框架的接口和类,它不同于内置同步和监视器.该框架允许更灵活地使用锁和条件,但以更难用的语法为代价. Lock 接口 ...
- Pascal's Triangle(杨辉三角)
Given numRows, generate the first numRows of Pascal's triangle. For example, given numRows = 5,Retur ...