实现Kubernetes跨集群服务应用的高可用
在Kubernetes 1.3版本,我们希望降低跨集群跨地区服务部署相关的管理和运营难度。本文介绍如何实现此目标。
注意:虽然本文示例使用谷歌容器引擎(GKE)来提供Kubernetes集群,您可以在任何的其他环境部署Kubernetes。
我们正式开始。第一步是在谷歌的四个云平台地区通过GKE创建Kubernetes集群。
asia-east1-b
europe-west1-b
us-east1-b
us-central1-b
我们通过下面的命令创建集群:
gcloud container clusters create gce-asia-east1 \
--scopes cloud-platform \
--zone asia-east1-b
gcloud container clusters create gce-europe-west1 \
--scopes cloud-platform \
--zone=europe-west1-b
gcloud container clusters create gce-us-east1 \
--scopes cloud-platform \
--zone=us-east1-b
gcloud container clusters create gce-us-central1 \
--scopes cloud-platform \
--zone=us-central1-b
gcloud container clusters list
NAME ZONE MASTER_VERSION MASTER_IP NUM_NODES STATUS
gce-asia-east1 asia-east1-b 1.2.4 104.XXX.XXX.XXX 3 RUNNING
gce-europe-west1 europe-west1-b 1.2.4 130.XXX.XX.XX 3 RUNNING
gce-us-central1 us-central1-b 1.2.4 104.XXX.XXX.XX 3 RUNNING
gce-us-east1 us-east1-b 1.2.4 104.XXX.XX.XXX 3 RUNNING
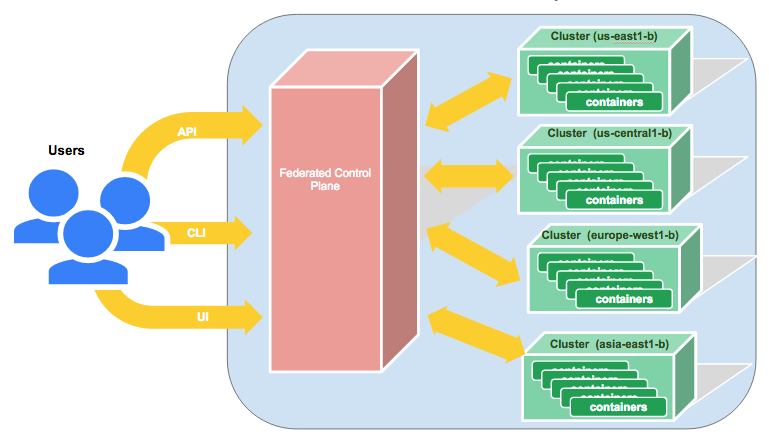
下一步是起动集群并在创建的其中一个集群中部署联邦控制模块(Control Plane)。您可以参考和依照Kelsey Hightower的示例进行这步配置。
从联邦API获取信息,因此您可以通过联邦API制定服务属性。
当服务创建后,联邦服务自动进行如下操作:
在联邦中注册的所有Kubernetes集群中创建服务;
监控服务碎片(以及它们所在集群)的健康状况;
在公共DNS提供商上面创建 DNS记录(如谷歌Cloud DNS,或者AWS Route 53),以此确定你的服务客户端能够在任何时候无缝的获得相关的健康服务终端,即使当集群,可用区或者地区出现服务中断的情况时。
在注册到联邦的Kubernetes集群中的服务客户端,当联邦服务在本地集群碎片工作正常时,会优先使用本地服务碎片,否则会在最近的其他集群中选取健康的服务碎片。
Kubernetes集群联邦能够联合不同的云供应商(比如GCP、AWS)以及私有云(如OpenStack)。您只需在相应的云供应商和位置创建您的集群,并且将每个集群的API Server地址和证书信息注册到联邦集群中。
在我们的示例中,我们在四个区域创建了集群,并且在其中的一个集群中部署了联邦控制模块,我们会用这个环境来部署我们的服务。具体请参考下图。
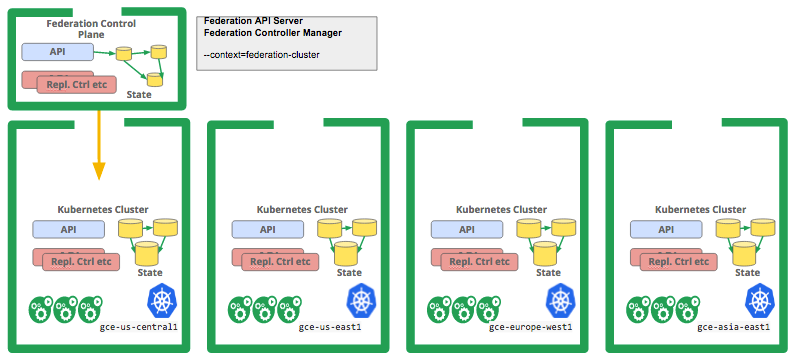
我们先查看联邦中所有注册好的集群:
kubectl --context=federation-cluster get clusters
NAME STATUS VERSION AGE
gce-asia-east1 Ready 1m
gce-europe-west1 Ready 57s
gce-us-central1 Ready 47s
gce-us-east1 Ready 34s
创建联邦服务:
kubectl --context=federation-cluster create -f services/nginx.yaml
--context=federation-cluster参数通知kubectl把带相关证书信息的请求提交至联邦API服务器。联邦服务会自动在联邦中所有集群创建相应的Kubernetes服务。
你可以通过检查每一个集群中的服务进行验证,比如:
kubectl --context=gce-asia-east1a get svc nginx
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx 10.63.250.98 104.199.136.89 80/TCP 9m
上面的命令假设你有一个名为gce-asia-east1a的kubectl的上下文设置,并且你有集群部署在这个区(zone)。Kubernetes服务的名字和名空间自动与你上面创建的集群服务一致。
联邦服务状态会实时体现Kubernetes对应的服务状态,例如:
kubectl --context=federation-cluster describe services nginx
Name: nginx
Namespace: default
Labels: run=nginx
Selector: run=nginx
Type: LoadBalancer
IP:
LoadBalancer Ingress: 104.XXX.XX.XXX, 104.XXX.XX.XXX, 104.XXX.XX.XXX, 104.XXX.XXX.XX
Port: http 80/TCP
Endpoints: <none>
Session Affinity: None
No events.
联邦服务的LoadBalancer Ingress地址会汇总所有注册的Kubernetes集群服务的LoadBalancer Ingress地址。为了让同一联邦服务在不通集群之间以及不同云供应商之间的网络正确工作,你的服务需要有外部可见的IP地址,比如Loadbalancer是常见的服务类型。
请注意我们还没有部署任何后台Pod来接收指向这些地址的网络流量(比如服务终端),所以此时联邦服务还不会认为这些服务碎片是健康的,所以联邦服务对应的DNS记录也尚未创建。
为了渲染底层服务碎片的健康状况,我们需要为服务增加后台Pod。目前需要通过直接操作底层集群的API Server来完成(为节省您的时间,未来我们可以通过一条命令在联邦服务器中创建)。例如我们在底层集群中创建后台Pod:
for CLUSTER in asia-east1-a europe-west1-a us-east1-a us-central1-a
do
kubectl --context=$CLUSTER run nginx --image=nginx:1.11.1-alpine --port=80
done
一旦Pod开始成功启动并开始监听连接,每个集群(通过健康检查)会汇报服务的健康终端至集群联邦。集群联邦会依次认为这些服务碎片是健康的,并且创建相应的公共DNS记录。你可以使用你喜欢的DNS供应商的接口来验证。比如,如果你使用谷歌Cloud DNS配置联邦, 你的DNS域为 ‘example.com’:
$ gcloud dns managed-zones describe example-dot-com
creationTime: '2016-06-26T18:18:39.229Z'
description: Example domain for Kubernetes Cluster Federation
dnsName: example.com.
id: '3229332181334243121'
kind: dns#managedZone
name: example-dot-com
nameServers:
- ns-cloud-a1.googledomains.com.
- ns-cloud-a2.googledomains.com.
- ns-cloud-a3.googledomains.com.
- ns-cloud-a4.googledomains.com.
$ gcloud dns record-sets list --zone example-dot-com
NAME TYPE TTL DATA
example.com. NS 21600 ns-cloud-e1.googledomains.com., ns-cloud-e2.googledomains.com.
example.com. SOA 21600 ns-cloud-e1.googledomains.com. cloud-dns-hostmaster.google.com. 1 21600 3600 1209600 300
nginx.mynamespace.myfederation.svc.example.com. A 180 104.XXX.XXX.XXX, 130.XXX.XX.XXX, 104.XXX.XX.XXX, 104.XXX.XXX.XX
nginx.mynamespace.myfederation.svc.us-central1-a.example.com. A 180 104.XXX.XXX.XXX
nginx.mynamespace.myfederation.svc.us-central1.example.com.
nginx.mynamespace.myfederation.svc.us-central1.example.com. A 180 104.XXX.XXX.XXX, 104.XXX.XXX.XXX, 104.XXX.XXX.XXX
nginx.mynamespace.myfederation.svc.asia-east1-a.example.com. A 180 130.XXX.XX.XXX
nginx.mynamespace.myfederation.svc.asia-east1.example.com.
nginx.mynamespace.myfederation.svc.asia-east1.example.com. A 180 130.XXX.XX.XXX, 130.XXX.XX.XXX
nginx.mynamespace.myfederation.svc.europe-west1.example.com. CNAME 180 nginx.mynamespace.myfederation.svc.example.com.
... etc.
注意:如果您使用AWS Route53来配置联邦,你可以使用相应的AWS工具,例如:
$aws route53 list-hosted-zones $aws route53 list-resource-record-sets --hosted-zone-id Z3ECL0L9QLOVBX
不管您使用什么DNS供应商, 您可以使用DNS查询工具(例如 ‘dig’ 或者 ‘nslookup’)来查看联邦为您创建的DNS记录。
默认情况下,Kubernetes集群有内置的本地域名服务器(KubeDNS),并且有智能的DNS搜索路径确保针对“myservice”、“myservice.mynamespace”、”bobsservice.othernamespace”等等被您运行在Pod中的的应用软件自动扩展和解析至相应的本地集群中的服务IP。
通过引入联邦服务以及跨集群服务发现,这个概念被扩展至全局,覆盖您联邦中所有的集群。为了利用这个扩展带来的便利性,您只需使用稍微不同的服务名(比如,myservice.mynamespace.myfederation)进行解析。
使用不同的DNS名同时避免了您现有的服务在您没有做明确的配置和选择情况下,意外的被解析到不同区(zone)或地域(region)网络,导致额外的网络费用或延迟。
因此,使用我们上面的NGINX 服务,以及刚刚介绍的联邦服务DNS名,我们构想一个示例:在可用性区域us-central1-a的集群中的pod需要访问我们的NGINX服务。与其使用传统的本地集群DNS名 (“nginx.mynamespace”,自动扩展为“nginx.mynamespace.svc.cluster.local”),现在可以使用联邦服务名“nginx.mynamespace.myfederation”。此名称会被自动扩展和解析至我的Nginx服务最近的健康节点,无论它在世界的哪里。如果本地集群存在健康服务碎片,那么本地集群IP地址(通常是10.x.y.z)会被返回(被集群本地KubeDNS)。这与非联邦服务解析完全一致。
如果服务在本地集群不存在(或者服务存在但本地没有健康的后台pod),DNS查询会自动扩充至`”nginx.mynamespace.myfederation.svc.us-central1-a.example.com”。实际的行为是查找离当前可用性区域最近的服务碎片的外部IP。该扩展被KubeDNS自动触发执行,返回相关的CNAME记录。这会遍历上面示例中的DNS记录,直到找到本地us-central1 区域联邦服务的外部IP。
通过明确指定DNS名,直接指向非本地可用区域(AZ)和地域(region)的服务碎片,而不依赖于自动DNS扩展,是可行的。例如,
“nginx.mynamespace.myfederation.svc.europe-west1.example.com”
会被解析至位于欧洲的所有健康服务碎片,即使通过nslookup解析出的服务位于美国,并无论在美国是否有该服务的健康碎片。这对远程监控和其它类似应用很有用。
对于外部客户端,前文描述的DNS自动扩展已不适用。外部客户端需要指定联邦服务的全名(FQDN),可以是区域,地域或全局名。为方便起见,最好为您的服务手工创建CNAME记录,比如:
eu.nginx.acme.com CNAME nginx.mynamespace.myfederation.svc.europe-west1.example.com.
us.nginx.acme.com CNAME nginx.mynamespace.myfederation.svc.us-central1.example.com.
nginx.acme.com CNAME nginx.mynamespace.myfederation.svc.example.com.
这样您的客户端可以一直使用左侧的短名形式,并且会被自动解析到它所在大陆的最近的健康节点上。集群联邦会帮您处理服务的failover。
标准Kubernetes服务集群IP已经确保无响应的Pod会被及时从服务中移除。Kubernetes联邦集群系统自动监控集群以及联邦服务所有碎片对应的终端的健康状况,并按需增加和删除服务碎片。
因为DNS缓存造成的延迟(缓存超时,或者联邦服务DNS记录TTL默认设置为三分钟,但可以调节) 可能需要这么长时间才能在某集群或服务碎片出现问题时,正确将客户端,请求failover到可用集群上。然而,因为每个服务终端可以返回多个ip地址,(如上面的us-central1,有三个选择)很多客户端会返回其中一个可选地址。
| 导读 | 我们在进行生产环境部署时得到的一个明确的需求,是Kubernetes用户希望服务部署能够zone、跨区域、跨集群甚至跨云边界(译者:如跨云供应商)。相比单集群多zone部署,跨集群服务提供按地域分布,支持混合云、多云场景,提升高可用等级。客户希望服务能够跨一到多个集群(可能是本地或者远程集群),并希望这些集群无论内部或外部都有一致稳定的连接。 |
实现Kubernetes跨集群服务应用的高可用的更多相关文章
- Apache shiro集群实现 (六)分布式集群系统下的高可用session解决方案---Session共享
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Apache shiro集群实现 (五)分布式集群系统下的高可用session解决方案
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
- Cluster基础(四):创建RHCS集群环境、创建高可用Apache服务
一.创建RHCS集群环境 目标: 准备四台KVM虚拟机,其三台作为集群节点,一台安装luci并配置iSCSI存储服务,实现如下功能: 使用RHCS创建一个名为tarena的集群 集群中所有节点均需要挂 ...
- k8s集群中部署Rook-Ceph高可用集群
先决条件 为确保您有一个准备就绪的 Kubernetes 集群Rook,您可以按照这些说明进行操作. 为了配置 Ceph 存储集群,至少需要以下本地存储选项之一: 原始设备(无分区或格式化文件系统) ...
- HAProxy+keepalived+MySQL 实现MHA中slave集群负载均衡的高可用
HAProxy+keepalived+MySQL实现MHA中slave集群的负载均衡的高可用 Ip地址划分: 240 mysql_b2 242 mysql_b1 247 haprox ...
- kubeadm安装集群系列-2.Master高可用
Master高可用安装 VIP负载均衡可以使用haproxy+keepalive实现,云上用户可以使用对应的ULB实现 准备kubeadm-init.yaml文件 apiVersion: kubead ...
- MySQL集群搭建(3)-MMM高可用架构
1 MMM 介绍 1.1 简介 MMM 是一套支持双主故障切换以及双主日常管理的第三方软件.MMM 由 Perl 开发,用来管理和监控双主复制,虽然是双主架构,但是业务上同一时间只允许一个节点进行写入 ...
- 分布式集群系统下的高可用session解决方案
目前,为了使web能适应大规模的访问,需要实现应用的集群部署. 而实现集群部署首先要解决session的统一,即需要实现session的共享机制. 目前,在集群系统下实现session统一的有如下几种 ...
随机推荐
- iptables/mysql设置指定主机访问指定端口
本周,运维告知部署的服务被扫描发现漏洞,涉及的软件分别为mysql,ZooKeeper与Elasticsearch. 因为最近任务繁重,人力资源紧张,因此无法抽出更多时间调整代码,添加权限认证. 与软 ...
- Python + PyQt5 实现美剧爬虫可视工具
美剧<权力的游戏>终于要开播最后一季了,作为马丁老爷子的忠实粉丝,为了能够看得懂第八季复杂庞大的剧情架构,本人想着将前几季再稳固一下,所以就上美剧天堂下载来看,可是每次都上去下载太麻烦了, ...
- springboot~zuul实现网关
网关在微服务里的角色 在微服务架构体系里,网关是非常重要的一个环节,它主要实现了一些功能的统一处理,包括了: 统一授权 统一异常处理 路由导向 跨域处理 限流 实践一下 1 添加依赖 dependen ...
- SpringBoot系列——jar包与war包的部署
前言 Spring Boot支持传统部署和更现代的部署形式.jar跟war都支持,这里参考springboot参考手册学习记录 两种方式 jar springboot项目支持创建可执行Jar,参考手册 ...
- 避免SQL全表模糊查询查询
1.模糊查询效率很低: 原因:like本身效率就比较低,应该尽量避免查询条件使用like:对于like %...%(全模糊)这样的条件,是无法使用索引的,全表扫描自然效率很低:另外,由于匹配算法的关系 ...
- 简简单单的Vue4(vue-cie@3.x,vue’Debug[调试],vue‘sHttp)
既然选择了远方,便只顾风雨兼程! __HANS许 系列:零基础搭建前后端分离项目 系列:零基础搭建前后端分离项目 vue-cli@3.x 创建项目 Vue的Debug(调试) Vue的Http请求 提 ...
- 升级SCCM 2012R2 SP1故障解决
故障一: 上周7月5号进行升级sccm至2012 R2 SP1的操作,执行升级程序splash.hta,在最后核心程序安装步骤失败,关闭升级程序,打开SCCM控制台报错如下: Configuratio ...
- windows如何安装memcached
官网上并未提供 Memcached 的 Windows 平台安装包,我们可以使用以下链接来下载,你需要根据自己的系统平台及需要的版本号点击对应的链接下载即可: 32位系统 1.2.5版本:http:/ ...
- vue 项目中引用百度地图
新建map.js export const BaiduMap = { init: function() { const BMapURL = 'https://api.map.baidu.com/api ...
- 适合精致女孩使用的APP软件 不容错过的精彩人生
阳光下灿烂,风雨中奔跑,每个人都会遇见美丽的缘分,或深或浅,或浓或淡.所以人生不管遇到什么难题,都要勇往直前.今天分享的软件也是十分精彩的,非常适合精彩的你哦! 薄荷健康 薄荷健康APP是专为想要减肥 ...