Lloyd’s 算法 和 K-Means算法
在讲Lloyd’s 算法之前先介绍Voronoi图
在数学中,Voronoi图是基于到平面的特定子集中的点的距离将平面划分成区域。预先指定一组点(称为种子,站点或生成器),并且对于每个种子,存在相应的区域,该区域由更接近该种子的所有点组成,而不是任何其他点。这些区域称为Voronoi细胞。

在最简单的情况下,如图所示,我们在欧几里德平面上给出了一组有限的点{p1,...,pn}。在这种情况下每个站点pk只是一个点,其相应的Voronoi单元Rk由欧几里德平面中的每个点组成,其与pk的距离小于或等于其与任何其他pk的距离。每个这样的单元是从半空间的交点获得的,因此它是凸多边形。 Voronoi图的边界是平面中与两个最近的站点等距的所有点。 Voronoi顶点(节点)是与三个(或更多)站点等距的点。
Lloyd’s algorithm 过程:
(1)首先在数据集中随机选定k个初始点
(2) 计算k个站点的Voronoi图。
(3)整合Voronoi图的每个单元格,并计算质心。
(4)然后将每个站点(k)移动到其Voronoi单元的质心。
如下图迭代过程
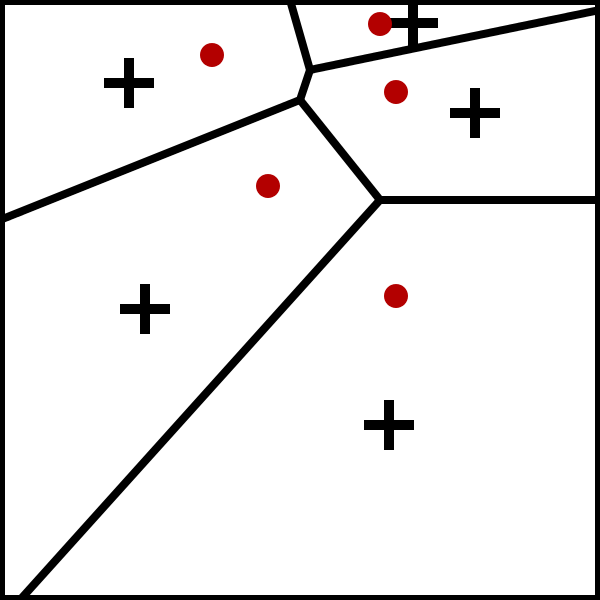
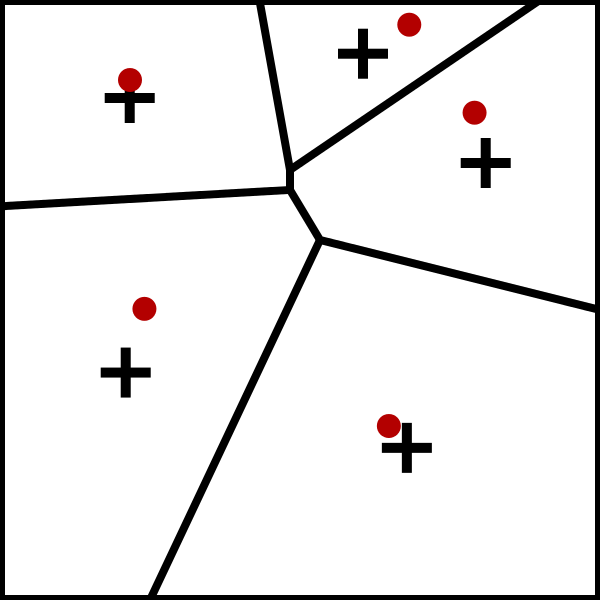
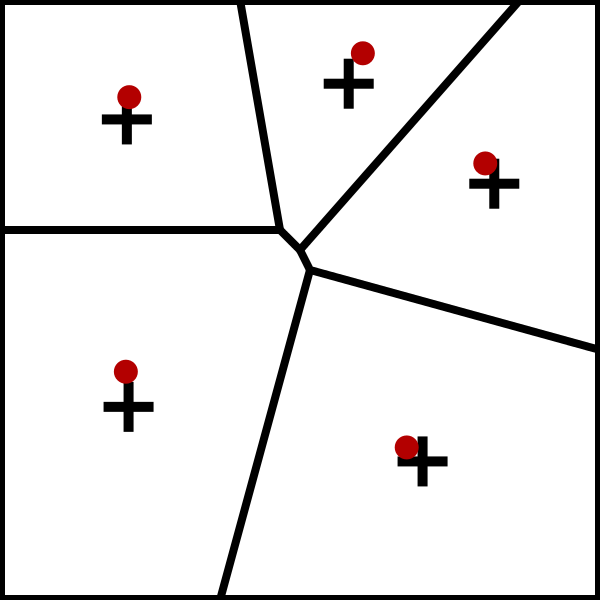
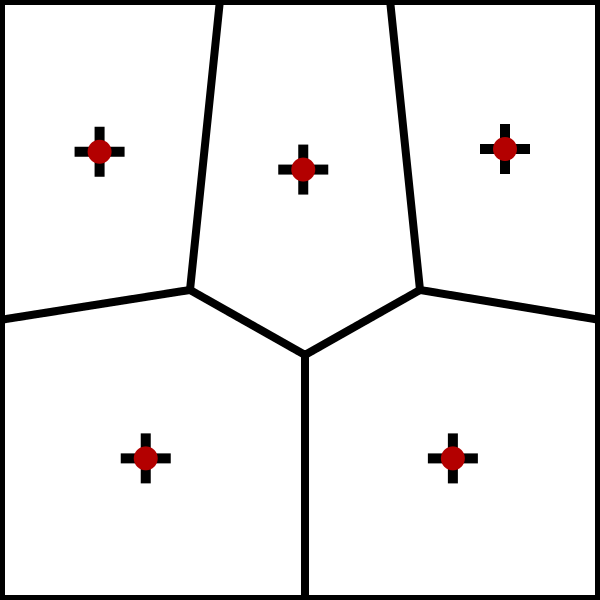
K-Means算法过程:
(1)随机初始化k个聚类中心的位置
(2)计算每一个点到聚类中心的距离,选取最小值分配给k(i)
(3)移动聚类中心(其实就是对所属它的样本点求平均值,就是它移动是位置)
(4)重复(2),(3)直到损失函数(也就是所有样本点到其所归属的样本中心的距离的和最小)
最后整体分类格局会变得稳定。
如下图
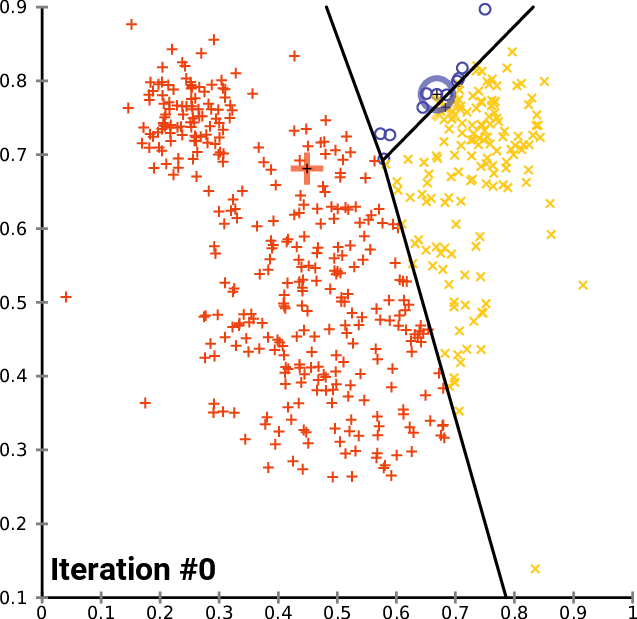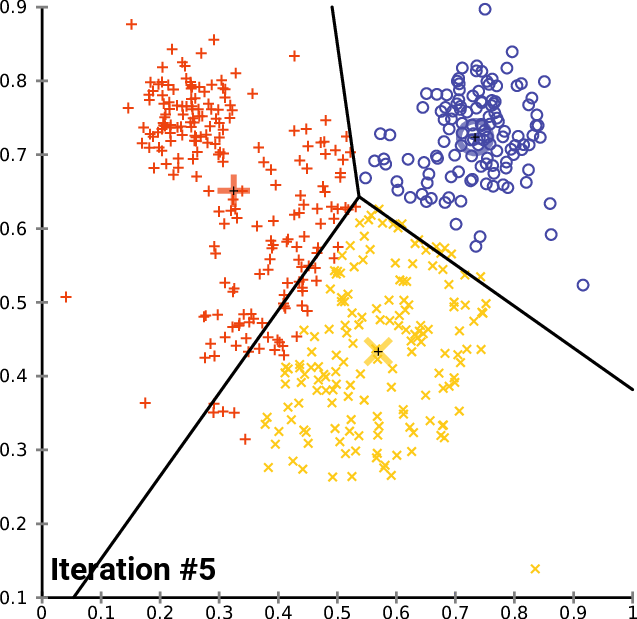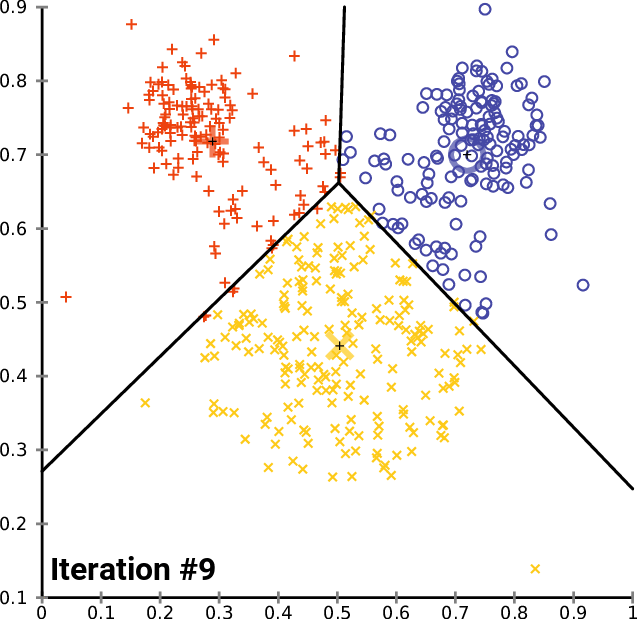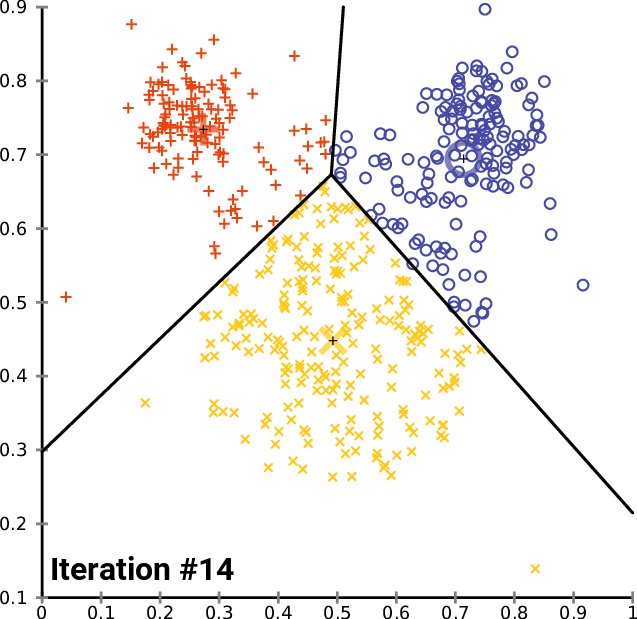
通过对比,可以发现这两个算法之间有许多相似之处,都是迭代的寻找聚族中心的位置。
然而,Lloyd’s算法与k均值聚类的不同之处在于,Lloyd’s的输入是一个连续的几何区域,而不是一组离散的点。
因此,当重新划分输入时,劳埃德算法使用Voronoi图而不是像k-means算法那样简单地确定每个有限点集的最近中心。
Lloyd’s 算法 和 K-Means算法的更多相关文章
- 机器学习算法之Kmeans算法(K均值算法)
Kmeans算法(K均值算法) KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- Python实现机器学习算法:K近邻算法
''' 数据集:Mnist 训练集数量:60000 测试集数量:10000(实际使用:200) ''' import numpy as np import time def loadData(file ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
随机推荐
- offsetLeft 解析
前言:先看下w3c与之相关的介绍: element.offsetHeight 返回元素的高度. element.offsetWidth 返回元素的宽度. element.offsetLeft 返回元素 ...
- SpringAOP(5)
2019-03-08/14:22:58 演示:登陆核心业务类与日志周边功能实现AOP面向切面思想 jar包:https://share.weiyun.com/5GOFouP 学习资料:http://h ...
- UEFI引导的简单恢复方法
装系统,尤其是双系统,总是无法绕过引导的坑. linux的grub是非常复杂的引导系统,学习它非常累.而windows又不能引导linux.你可能会想,怎么就没有一种简单的引导方式,就好像引导光盘,引 ...
- 测者的测试技术手册:智能化测试框架EvoSuite的一个坑以及填坑方法
问题 最近在不断地学习和探索EvoSuite框架的时候,在生产JUnit单元测试框架后,出现如下问题: Exception: Caused by: org.evosuite.runtime.TooMa ...
- 基于FPM制作nginx RPM包
目录 环境 配置 FPM安装 环境 系统 其它 CentOS 7.5 需提前配置好epel 配置 [root@localhost ~]# yum clean all && yum ma ...
- [LeetCode] 21. 合并两个有序链表
题目链接:https://leetcode-cn.com/problems/merge-two-sorted-lists/ 题目描述: 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定 ...
- springmvc源码分析——入门看springmvc的加载过程
本文将分析springmvc是如何在容器启动的时候将各个模块加载完成容器的创建的. 我知道在web.xml文件中我们是这样配置springmvc的: 可以看到,springmvc的核心控制器就是Dis ...
- Python--day10(函数(使用、分类、返回值))
1. 函数 1. 函数: 完成特定功能的代码块,作为一个整体,对其进行特定的命名,该名字就代表这函数 现实中:很多问题要通过一些工具进行处理 => 可以将工具提前生产出来并命名 =>通 ...
- 电梯调度编写(oo-java编程)
第二单元的问题是写一个关于电梯调度的程序. 需要模拟一个多线程实时电梯系统,从标准输入中输入请求信息,程序进行接收和处理,模拟电梯运行,将必要的运行信息通过输出接口进行输出. 主要锻炼学生的多线程程序 ...
- Recovering Low-Rank Matrices From Few Coefficients In Any Basis
目录 引 主要结果 定理2,3 定理4 直观解释 Recovering Low-Rank Matrices From Few Coefficients In Any Basis-David Gross ...