[机器学习Lesson4]多元线性回归
1. 多元线性回归定义
在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。因此多元线性回归比一元线性回归的实用意义更大。
我们现在介绍方程的符号,我们可以有任意数量的输入变量。

这些多个特征的假设函数的多变量形式如下:
hθ(x)=θ0+θ1x1+θ2x2+θ3x3+⋯+θnxn
为了开发这个功能,我们可以想一想,θ0作为房子的基本价格,θ1每平方米的价格,θ2每层楼的价格,等X1将在房子的平方米数,x2楼层数,等等。
利用矩阵乘法的定义,我们的多变量假设函数可以简洁地表示为:

这是对一个训练例子的假设函数的矢量化。
备注:为了方便的原因,在这个过程中我们假设X(i)0 = 1(i∈1,…,m)。这允许我们做矩阵运算与θ和X使两向量的θ和X(i)互相匹配元素(即有相同数目的元素:N + 1)]。
2. 梯度下降
下面我们使用梯度下降法来解决多特征的线性回归问题。

Hypothesis: 假设假设现有多元线性回归并约定x0=1。
Parameters: 该模型的参数是从θ0 到θn。不要认为这是 n+1 个单独的参数。你可以把这 n+1 个 θ 参数想象成一个 n+1 维的向量 θ。所以,现在就可以把这个模型的参数 想象成其本身就是一个 n+1 维的向量。
Cost function: 我们的代价函数是从 θ0 到 θn 的函数 J,并给出了误差项平方的和。但同样地,不要把函数 J想成是一个关于 n+1 个自变量的函数,而是看成带有一个 n+1 维向量的函数。
Gradient descent(梯度下降): 我们将会不停地用 θj 减去 α 倍的导数项,来替代 θj 同样的方法。我们写出函数J(θ) 因此 θj 被更新成 θj 减去学习率 α 与对应导数的乘积 就是代价函数的对参数 θj 的偏导数。
2.1 当特征 n=1 时

我们有两条针对参数 θ0 和 θ1 不同的更新规则。①处是代价函数里部分求导的结果 ,是代价函数相对于 θ0 的偏导数。 同样,对参数 θ1 我们有另一个更新规则 仅有的一点区别是:当我们之前只有一个特征,我们称该特征为x(i)。 但现在我们在新符号里,我们会标记它为 x 上标 (i) 下标1来表示我们的特征。以上就是当我们仅有一个特征时候的算法。
2.2 当有一个以上特征时
现有数目远大于1的很多特征,梯度下降更新规则变成了这样:

有些同学可能知道微积分,代价函数 J 对参数 θj 求偏导数 (蓝线圈出部分),你将会得到多元线性回归的梯度下降算法。
新旧两种算法实际上是两个是类似的算法。为什么它们都是梯度下降算法?考虑这样一个情况:有两个或以上个数的特征,同时我们对θ1、θ2、θ3的三条更新规则,当然可能还有其它参数。如果你观察θ0的更新规则,你会发现这跟之前 n=1的情况相同。它们之所以是等价的这是因为在我们的标记约定里有 x(i)0=1,),也就红线圈起部分的两项是等价的。
同样地,如果你观察θ1的更新规则你会发现这里的这一项是和之前对参数θ1的更新项是等价的。在这里我们只是用了新的符号x(i)1来表示我们的第一个特征。现在我们有个更多的特征,那么就可以用与之前相同的更新规则,我们可以用同样的规则来处理 θ2 等其它参数。
3. Feature Scaling(特征缩放)
如果你有一个机器学习问题,这个问题有多个特征,如果你能确保这些特征都处在一个相近的范围,确保不同特征的取值在相近的范围内,这样梯度下降法就能更快地收敛。
3.1 介绍
假如你有一个具有两个特征的问题:其中,x1是房屋面积大小,它的取值在0到2000之间。x2是卧室的数量,可能这个值取值范围在1到5之间。 如果你画出代价函数J(θ)的轮廓图,那么这个轮廓看起来应该是像下图这样的:
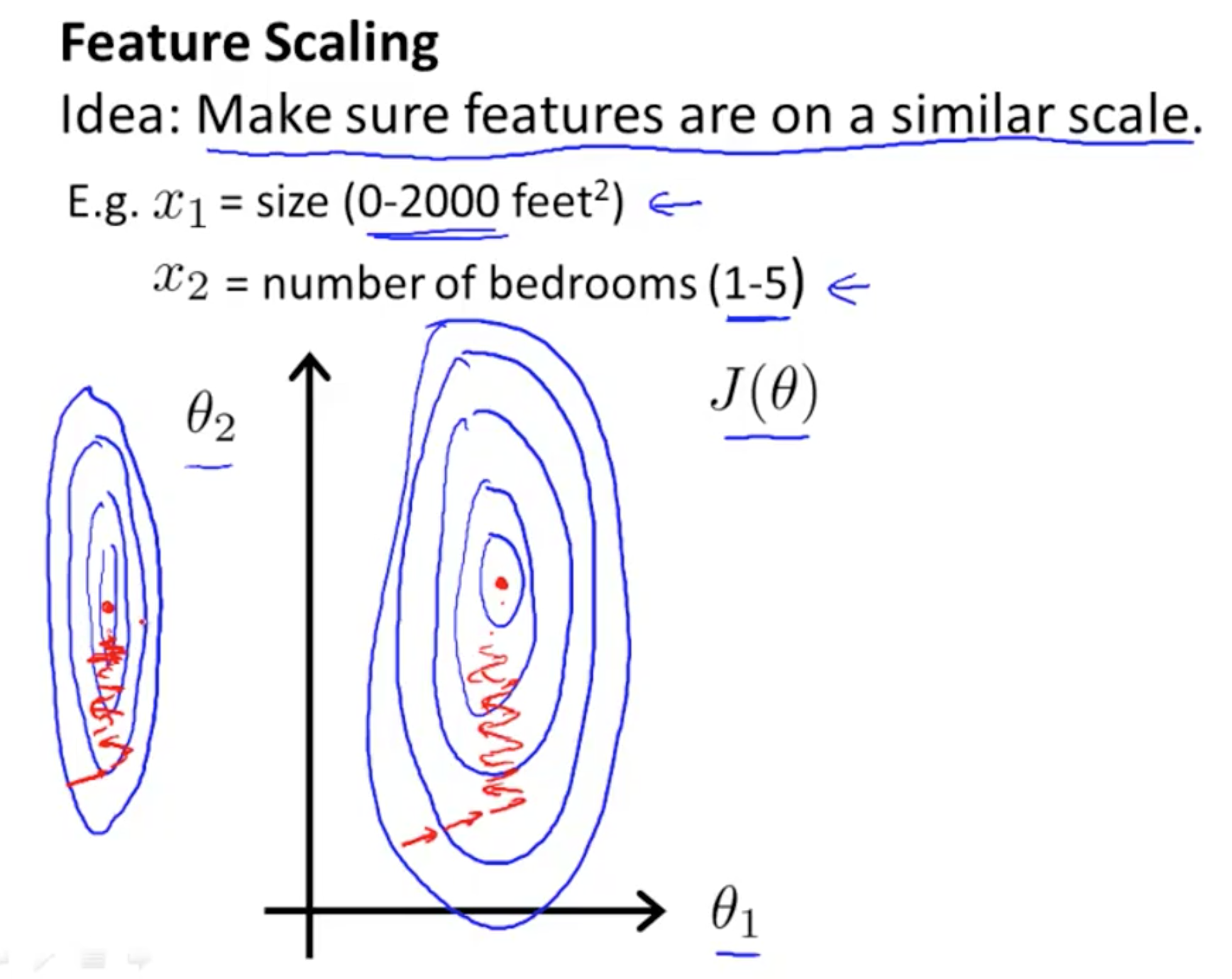
J(θ) 是一个关于参数 θ0 θ1 和 θ2 的函数(此处忽略 θ0 所以暂时不考虑θ0)。并假想一个函数的变量只有 θ1 和 θ2。 但如果x1的取值范围远远大于x2的取值范围的话,那么最终画出来的代价函数J(θ)的轮廓图就会呈现出这样一种非常偏斜,并且椭圆的形状 2000 和 5的比例 会让这个椭圆更加瘦长。所以,这是一个又瘦又高的 椭圆形轮廓图 就是这些非常高大细长的椭圆形构成了代价函数 J(θ) 。
而如果你用这个代价函数来运行梯度下降的话,你要得到梯度值,最终可能需要花很长一段时间并且可能会来回波动,然后会经过很长时间,最终才收敛到全局最小值。
可以想像,如果这些轮廓再被放大一些的话,如果你画的再夸张一些,把它画的更细更长,那么可能情况会更糟糕 。梯度下降的过程可能更加缓慢,需要花更长的时间,反复来回振荡,最终才找到一条正确通往全局最小值的路。
在这样的情况下一种有效的方法是进行特征缩放(feature scaling) 。
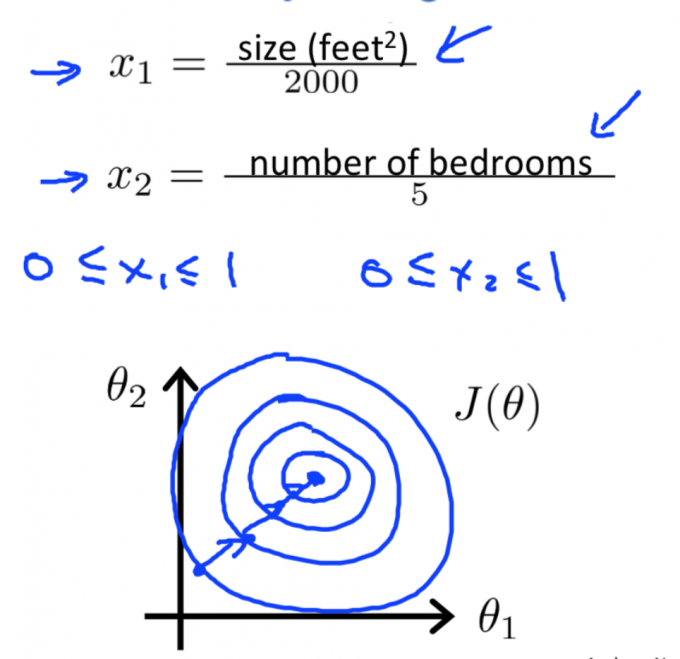
具体来说,把特征x定义为房子的面积大小,除以2000; 并且把x2定义为卧室的数量除以5。那么这样的话 表示代价函数 J(θ) 的轮廓图的形状就会变得偏移没那么严重,可能看起来更圆一些了。
如果你用这样的代价函数来执行梯度下降的话,可以从数学上来证明,梯度下降算法就会找到一条更捷径的路径通向全局最小,而不是像刚才那样沿着一条让人摸不着头脑的路径,一条复杂得多的轨迹,来找到全局最小值。
因此,通过特征缩放,通过"消耗掉"这些值的范围,在这个例子中,我们最终得到的两个特征 x1 和 x2 都在0和1之间,这样你得到的梯度下降算法就会更快地收敛。
3.2 特征范围
我们执行特征缩放时,通常的目的是将特征的取值约束到-1到+1的范围内:

你的特征x0是总是等于1,因此这已经是在这个范围内。
但对其他的特征 你可能需要通过除以不同的数 来让它们处于同一范围内。-1 和 +1这两个数字并不是太重要,所以 如果你有一个特征x1 它的取值在0和3之间,是没问题的。如果你有另外一个特征取值在-2 到 +0.5之间这也没什么关系,这也非常接近 -1 到 +1的范围,这些都可以。
但如果你有另一个特征,比如叫 x3 假如它的范围在 -100到+100之间,那么这个范围跟-1到+1就有很大不同了。所以这可能是一个不那么好的特征。类似地,如果你的特征在一个非常非常小的范围内,比如另外一个特征 x4 它的范围在 0.0001和+0.0001之间,那么这同样是一个 比-1到+1小得多的范围。因此同样会认为这个特征也不太好。
所以,可能你认可的范围也许可以大于或者小于-1到+1,但是也别太大,只要大得不多就可以接受。比如 +100 或者也别太小,比如这里的0.001。不同的人有不同的经验。但是我一般是这么考虑的,如果一个特征是在 -3 到 +3 的范围内,那么你应该认为这个范围是可以接受的。 但如果这个范围大于了-3到+3的范围,我可能就要开始注意了。如果它的取值 在-1/3 到+1/3的话,我觉得 还不错,可以接受。或者是0到1/3或-1/3到0,这些典型的范围,我都认为是可以接受的。但如果特征的范围 取得很小的话,比如像这里的0.0001你就要开始考虑进行特征缩放了。
因此,总的来说不用过于担心你的特征是否在完全 相同的范围或区间内,但是只要他们都只要它们足够接近的话,梯度下降法就会正常地工作。
3.3 Mean Normalization(均值归一化)
除了在特征缩放中将特征除以最大值以外,有时候我们也会进行一个称为均值归一化的工作(mean normalization) 。

如果你有一个特征 xi 你就用xi-μi来替换,通过这样做 让你的特征值具有为0的平均值。我们不需要把这一步应用到x0中,因为x0总是等于1的,所以它不可能有为0的的平均值。但是对其他的特征来说,比如房子的大小,取值介于0到2000,并且假设房子面积的平均值是等于1000的。那么你可以用这个公式将x1的值变为,x1减去平均值μ1再除以2000。类似地,如果你的房子有五间卧室 ,并且平均一套房子有两间卧室,那么可以使用这个公式来归一化你的第二个特征x2。
在这两种情况下,你可以算出新的特征x1和x2这样它们的范围可以在-0.5和+0.5之间,当然这肯定不对。x2的值实际上肯定会大于0.5,但很接近。更一般的规律是 你可以用这样的公式: (x1 - μ1)/S1来替换原来的特征x1。其中定义μ1的意思是: 在训练集中:
- x1:平均值
- S1:特征值的范围(最大值减去最小值 最大值减去最小值,或者学过标准差的同学可以记住 也可以把S1设为变量的标准差,但其实用最大值减最小值就可以了)
类似地,对于第二个 特征 x2 你也可以用同样的这个
特征减去平均值,再除以范围来替换原特征。范围的意思依然是最大值减最小值。这类公式将你的特征 变成这样的范围,也许不是完全这样,但大概是这样的范围。
有些同学可能比较仔细,如果我们用最大值减最小值来表示范围的话。这里的5有可能应该是4 如果最大值为5,那么减去最小值1,这个范围值就是4 。但不管咋说,这些取值都是非常近似的,只要将特征转换为相近似的范围就都是可以的。
特征缩放其实并不需要太精确,只是为了让梯度下降 能够运行得更快一点而已。
4. Learning Rate(学习效率)
这一章节我们来介绍如何选择学习率α 以及怎样确定 梯度下降正常工作。
Debugging gradient descent(调试渐变下降):用X轴上的迭代次数绘制一个图。现在小区的成本函数,J(θ)在梯度下降迭代次数。如果J(θ)不断增加,那么你可能需要减少α。
Automatic convergence test(自动收敛测试) :如果该声明收敛(θ)小于E在一次迭代中减少,其中E是一些小的值,如10−3。然而,在实际应用中很难选择这个阈值。

如果学习率α足够小,那么J(θ)会在每个迭代中减少。
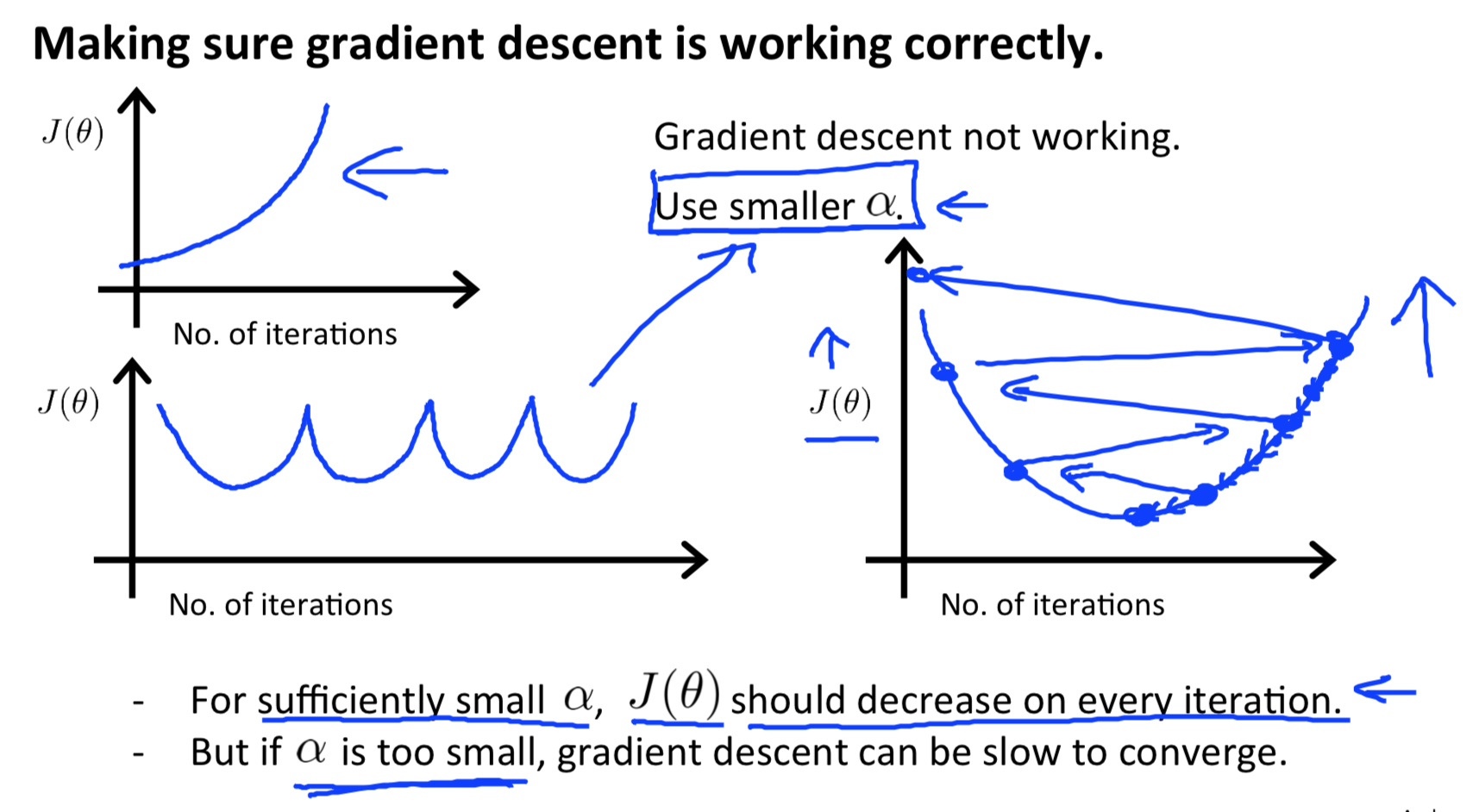
总结:
- 如果α太小:收敛速度慢。
- 如果α太大:可能不会在每次迭代中减少,因此可能不会收敛。
本文资料部分来源于吴恩达 (Andrew Ng) 博士的斯坦福大学机器学习公开课视频教程。
[1] 网易云课堂机器学习课程:
http://open.163.com/special/opencourse/machinelearning.html
[2] coursera课程:
https://www.coursera.org/learn/machine-learning/
[机器学习Lesson4]多元线性回归的更多相关文章
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 【TensorFlow篇】--Tensorflow框架初始,实现机器学习中多元线性回归
一.前述 TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,T ...
- 100天搞定机器学习|Day3多元线性回归
前情回顾 [第二天100天搞定机器学习|Day2简单线性回归分析][1],我们学习了简单线性回归分析,这个模型非常简单,很容易理解.实现方式是sklearn中的LinearRegression,我们也 ...
- 机器学习——Day 3 多元线性回归
写在开头 由于某些原因开始了机器学习,为了更好的理解和深入的思考(记录)所以开始写博客. 学习教程来源于github的Avik-Jain的100-Days-Of-MLCode 英文版:https:// ...
- Andrew Ng机器学习课程笔记--week2(多元线性回归&正规公式)
1. 内容概要 Multivariate Linear Regression(多元线性回归) 多元特征 多元变量的梯度下降 特征缩放 Computing Parameters Analytically ...
- 斯坦福机器学习视频笔记 Week2 多元线性回归 Linear Regression with Multiple Variables
相比于week1中讨论的单变量的线性回归,多元线性回归更具有一般性,应用范围也更大,更贴近实际. Multiple Features 上面就是接上次的例子,将房价预测问题进行扩充,添加多个特征(fea ...
- 机器学习之多变量线性回归(Linear Regression with multiple variables)
1. Multiple features(多维特征) 在机器学习之单变量线性回归(Linear Regression with One Variable)我们提到过的线性回归中,我们只有一个单一特征量 ...
- 多元线性回归----Java简单实现
http://www.cnblogs.com/wzm-xu/p/4062266.html 多元线性回归----Java简单实现 学习Andrew N.g的机器学习课程之后的简单实现. 课程地址:h ...
- machine learning 之 多元线性回归
整理自Andrew Ng的machine learning课程 week2. 目录: 多元线性回归 Multivariates linear regression /MLR Gradient desc ...
随机推荐
- 如何图形化创建oracle数据库
需要注意的几点 1.如果用oracle客户端访问服务器的话必须把服务器的主机名写成(计算机的名称)Oracle创建数据库的方法 2.navigate如何远程oracle数据库 E:\app\lenov ...
- 福州大学W班-alpha冲刺评分
作业链接 https://edu.cnblogs.com/campus/fzu/FZUSoftwareEngineering1715W/homework/1159 作业要求 1.前期准备 阅读学习&l ...
- alpha-咸鱼冲刺day8-紫仪
总汇链接 一,合照 emmmmm.自然还是没有的. 二,项目燃尽图 三,项目进展 正在进行页面整合.然后还有注册跟登陆的功能完善-- 四,问题困难 数据流程大概是搞定了.不过语法不是很熟悉,然后还有各 ...
- C语言数据类型作业
一.PTA实验作业 题目1:7-4 打印菱形图案 1. 本题PTA提交列表 2. 设计思路 1.定义m,n(用于计算空格数,输出"* "数),i,j,k(用于循环) 2.输入n,并 ...
- Mybash的实现
Mybash的实现 要求: 使用fork,exec,wait实现mybash 写出伪代码,产品代码和测试代码 发表知识理解,实现过程和问题解决的博客(包含代码托管链接) 背景知识 1. fork 使用 ...
- VS系列控制台闪退解决
查阅--->总结-->实践--> 按红色标识走 ,完美解决! 至此,完美解决:原理不深究:
- poj2029 Get Many Persimmon Trees
http://poj.org/problem?id=2029 单点修改 矩阵查询 二维线段树 #include<cstdio> #include<cstring> #inclu ...
- 浅谈 ThreadLocal
有时,你希望将每个线程数据(如用户ID)与线程关联起来.尽管可以使用局部变量来完成此任务,但只能在本地变量存在时才这样做.也可以使用一个实例属性来保存这些数据,但是这样就必须处理线程同步问题.幸运的是 ...
- 一句话了解JAVA与大数据之间的关系
大数据无疑是目前IT领域的最受关注的热词之一.几乎凡事都要挂上点大数据,否则就显得你OUT了.如果再找一个可以跟大数据并驾齐驱的IT热词,JAVA无疑是跟大数据并驾齐驱的一个词语.很多人在提到大数据的 ...
- css的内容
块级元素和行内元素的区别: 1. 行内元素部不能够设置宽度和高度.行内元素的宽度和高度是标签内容的宽度和高度.块级元素可以设置宽度和高度. 2. 块级元素会独占一行.而行内元素却部能够独占一行,只能和 ...