搞懂Redis RDB和AOF持久化及工作原理
前言
因为Redis的数据都储存在内存中,当进程退出时,所有数据都将丢失。为了保证数据安全,Redis支持RDB和AOF两种持久化机制有效避免数据丢失问题。RDB可以看作在某一时刻Redis的快照(snapshot),非常适合灾难恢复。AOF则是写入操作的日志。本文主要讲解RDB、AOF和混合结合使用。
一.探索RDB
RDB就像是一台给Redis内存数据存储拍照的照相机,生成快照保存到磁盘的过程。触发RDB持久化分为手动触发和自动触发。Redis重启读取RDB速度快,但是无法做到实时持久化,因此一般用于数据冷备和复制传输。
手动触发
使用save命令:此命令会使用Redis的主线程进程同步存储,阻塞当前的Redis服务器,造成服务不可用,直到RDB过程完成。无论当前服务器数据量大小,线上不要用。
127.0.0.1:> save
OK
(1.14s)
:M Apr ::51.948 * DB saved on disk
使用bgsave命令:此命令会通过fork()创建子进程,在后台进程存储。只有fork阶段会阻塞当前Redis服务器,不必到整个RDB过程结束,一般时间很短。因此Redis内部涉及到RDB都采用bgsave命令。这里注意一点,无论RDB还是AOF,由于使用了写时复制,fork出来的子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表。
127.0.0.1:> bgsave
Background saving started
:M Apr ::40.312 * Background saving started by pid
:C Apr ::40.314 * DB saved on disk
:M Apr ::40.317 * Background saving terminated with success
自动触发
一般我们是不会直接用命令生成RDB文件的,Redis支持自动触发RDB持久化机制,配置都在redis.conf文件里面,我们先来看一下文件里关于rdb的默认配置,这边都用红色字体标注出来了,英文的文档解释的十分清楚,注释也写的很不错。
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after sec ( min) if at least key changed
# after sec ( min) if at least keys changed
# after sec if at least keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save "" save 900 1
save 300 10
save 60 10000 # By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes # Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes # Since version of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around %) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes # The filename where to dump the DB
dbfilename dump.rdb # The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /usr/local/var/db/redis/
- save m n:代表Redis服务器在m秒内数据存在n次修改时,自动触发rdb。这个参数比较关键。
- stop-writes-on-bgsave-error:如果是yes,当bgsave命令失败时Redis将停止写入操作。
- rdbcompression:是否对RDB文件进行压缩,但是在LZF压缩消耗更多CPU
- rdbchecksum:是否对RDB文件进程校验
- dbfilename:配置文件名称,默认dump.rdb
- dir:配置rdb文件存放的路劲,这个参数比较重要。
工作原理
首先我们来看一下server.h文件内saveparams参数,可以看到,seconds就是秒数,changes就是改变量。是不是就对应着刚刚说的save m n的配置呢?
struct redisServer {
....
struct saveparam *saveparams; /* Save points array for RDB */
...
};
struct saveparam {
time_t seconds;
int changes;
};
接下来我们看这个redis.c文件,有个周期性函数,叫做serverCron,它会周期调用,大概做这几件事情,见注释。用红色标注的说明会触发bgsave和aof rewrite。
/* This is our timer interrupt, called server.hz times per second.
* Here is where we do a number of things that need to be done asynchronously.
* For instance:
*
* - Active expired keys collection (it is also performed in a lazy way on
* lookup).
* - Software watchdog.
* - Update some statistic.
* - Incremental rehashing of the DBs hash tables.
* - Triggering BGSAVE / AOF rewrite, and handling of terminated children.
* - Clients timeout of different kinds.
* - Replication reconnection.
* - Many more...
*
* Everything directly called here will be called server.hz times per second,
* so in order to throttle execution of things we want to do less frequently
* a macro is used: run_with_period(milliseconds) { .... }
*/ int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
在这个方法里面有这样一段代码,这边单独拿出来,这段代码的意思是判断changes是否满足并执行save操作。
/* If there is not a background saving/rewrite in progress check if
* we have to save/rewrite now */
for (j = ; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j; /* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveBackground(server.rdb_filename);
break;
}
}
接着继续看这个方法的部分代码片段,在rdb.c文件里。我们可以看到子进程名为"redis-rdb-bgsave"
int rdbSaveBackground(char *filename) {
pid_t childpid;
long long start;
if (server.aof_child_pid != - || server.rdb_child_pid != -) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
start = ustime();
if ((childpid = fork()) == ) {
int retval;
/* Child */
closeListeningSockets();
redisSetProcTitle("redis-rdb-bgsave");
retval = rdbSave(filename);
if (retval == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty();
if (private_dirty) {
serverLog(LL_NOTICE,
"RDB: %zu MB of memory used by copy-on-write",
private_dirty/(*));
}
}
exitFromChild((retval == C_OK) ? : );
}
最后我们看一下RDB的运作流程图:
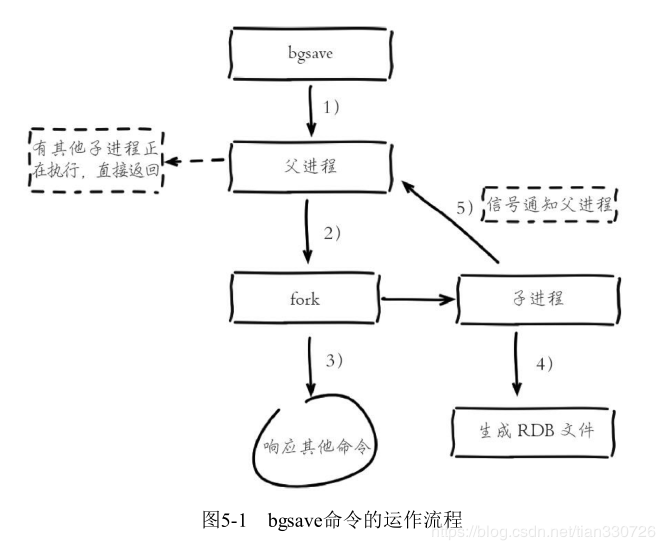
- redis执行bgsave命令,Redis判断当前存在正在进行执行的子进程,如RDB/AOF子进程,存在bgsave命令直接返回
- fork出子进程,fork操作中Redis父进程会阻塞
- fork完成返回 59117:M 13 Apr 13:44:40.312 * Background saving started by pid 59180
- 子进程进程对内存数据生成快找文件
- 子进程告诉父进程处理完成
探索RDB文件
我们可以使用redis-rdb-tools来分析rdb快照文件,他可以把rdb快照文件生成json文件,看起来比较方便。
rdb -c memory dump.rdb > testMjx.csv
然后我们看下生成的文件长啥样
database,type,key,size_in_bytes,encoding,num_elements,len_largest_element,expiry
,string,mjx3,,string,,,
,string,mjx5,,string,,,
,string,mjx2,,string,,,
,string,mjx,,string,,,
,string,mjx4,,string,,,
生成的数据有database(key在Redis的db)、type(key类型)、key(key值)、size_in_bytes(key的内存大小)、encoding(value的存储编码形式)、num_elements(key中的value的个数)、len_largest_element(key中的value的长度)、超时时间。
优缺点
RDB持久化方式的优点:
- 非常适合全量备份
- 恢复速度比AOF快
RDB持久化方式的缺点:
- RDB方式没有办法做到实时持久化
- 版本兼容RDB格式问题
二.探索AOF
RDB方式不能提供强一致性,如果Redis进程崩溃,那么两次RDB之间的数据也随之消失。那么AOF的出现很好的解决了数据持久化的实时性,AOF以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令来恢复数据。AOF会先把命令追加在AOF缓冲区,然后根据对应策略写入硬盘(appendfsync),具体参数后面有讲。接下来介绍一下AOF重写命令。
手动触发
使用bgrewriteaof命令:Redis主进程fork子进程来执行AOF重写,这个子进程创建新的AOF文件来存储重写结果,防止影响旧文件。因为fork采用了写时复制机制,子进程不能访问在其被创建出来之后产生的新数据。Redis使用“AOF重写缓冲区”保存这部分新数据,最后父进程将AOF重写缓冲区的数据写入新的AOF文件中然后使用新AOF文件替换老文件。
127.0.0.1:> bgrewriteoaf
OK
自动触发
和RDB一样,配置在redis.conf文件里,当然你也可以通过调用CONFIG SET命令设置。我们先看来看AOF相关配置:
############################## APPEND ONLY MODE ############################### # By default Redis asynchronously dumps the dataset on disk. This mode is
# good enough in many applications, but an issue with the Redis process or
# a power outage may result into a few minutes of writes lost (depending on
# the configured save points).
#
# The Append Only File is an alternative persistence mode that provides
# much better durability. For instance using the default data fsync policy
# (see later in the config file) Redis can lose just one second of writes in a
# dramatic event like a server power outage, or a single write if something
# wrong with the Redis process itself happens, but the operating system is
# still running correctly.
#
# AOF and RDB persistence can be enabled at the same time without problems.
# If the AOF is enabled on startup Redis will load the AOF, that is the file
# with the better durability guarantees.
#
# Please check http://redis.io/topics/persistence for more information. appendonly no # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # The fsync() call tells the Operating System to actually write data on disk
# instead of waiting for more data in the output buffer. Some OS will really flush
# data on disk, some other OS will just try to do it ASAP.
#
# Redis supports three different modes:
#
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
#
# The default is "everysec", as that's usually the right compromise between
# speed and data safety. It's up to you to understand if you can relax this to
# "no" that will let the operating system flush the output buffer when
# it wants, for better performances (but if you can live with the idea of
# some data loss consider the default persistence mode that's snapshotting),
# or on the contrary, use "always" that's very slow but a bit safer than
# everysec.
#
# More details please check the following article:
# http://antirez.com/post/redis-persistence-demystified.html
#
# If unsure, use "everysec". # appendfsync always
appendfsync everysec
# appendfsync no # When the AOF fsync policy is set to always or everysec, and a background
# saving process (a background save or AOF log background rewriting) is
# performing a lot of I/O against the disk, in some Linux configurations
# Redis may block too long on the fsync() call. Note that there is no fix for
# this currently, as even performing fsync in a different thread will block
# our synchronous write() call.
#
# In order to mitigate this problem it's possible to use the following option
# that will prevent fsync() from being called in the main process while a
# BGSAVE or BGREWRITEAOF is in progress.
#
# This means that while another child is saving, the durability of Redis is
# the same as "appendfsync none". In practical terms, this means that it is
# possible to lose up to seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability. no-appendfsync-on-rewrite no # Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature. auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb # An AOF file may be found to be truncated at the end during the Redis
# startup process, when the AOF data gets loaded back into memory.
# This may happen when the system where Redis is running
# crashes, especially when an ext4 filesystem is mounted without the
# data=ordered option (however this can't happen when Redis itself
# crashes or aborts but the operating system still works correctly).
#
# Redis can either exit with an error when this happens, or load as much
# data as possible (the default now) and start if the AOF file is found
# to be truncated at the end. The following option controls this behavior.
#
# If aof-load-truncated is set to yes, a truncated AOF file is loaded and
# the Redis server starts emitting a log to inform the user of the event.
# Otherwise if the option is set to no, the server aborts with an error
# and refuses to start. When the option is set to no, the user requires
# to fix the AOF file using the "redis-check-aof" utility before to restart
# the server.
#
# Note that if the AOF file will be found to be corrupted in the middle
# the server will still exit with an error. This option only applies when
# Redis will try to read more data from the AOF file but not enough bytes
# will be found.
aof-load-truncated yes # When rewriting the AOF file, Redis is able to use an RDB preamble in the
# AOF file for faster rewrites and recoveries. When this option is turned
# on the rewritten AOF file is composed of two different stanzas:
#
# [RDB file][AOF tail]
#
# When loading Redis recognizes that the AOF file starts with the "REDIS"
# string and loads the prefixed RDB file, and continues loading the AOF
# tail.
#
# This is currently turned off by default in order to avoid the surprise
# of a format change, but will at some point be used as the default.
aof-use-rdb-preamble no
- appendonly:是否打开AOF持久化功能
- appendfilename:AOF文件名称
- appendfsync:同步频率
- auto-aof-rewrite-min-size:如果文件大小小于此值不会触发AOF,默认64MB
- auto-aof-rewrite-percentage:Redis记录最近的一次AOF操作的文件大小,如果当前AOF文件大小增长超过这个百分比则触发一次重写,默认100
这里介绍一下appendfsync参数的可配置值
- always:命令写入aof缓冲区后,每一次写入都需要同步,直到写入磁盘(阻塞,系统调用fsync)结束后返回。显然和Redis高性能背道而驰,不建议配置
- everysec:命令写入aof缓冲区后,在写入系统缓冲区直接返回(系统调用write),然后有专门线程每秒执行写入磁盘(阻塞,系统调用fsync)后返回
- no:命令写入aof缓冲区后,在写入系统缓冲区直接返回(系统调用write)。之后写入磁盘(阻塞,系统调用fsync)的操作由操作系统负责,通常最长30s
工作原理
这里看一段aof.c的代码,我们可以看到fork出名为"redis-aof-rewrite"的子进程
/* This is how rewriting of the append only file in background works:
*
* 1) The user calls BGREWRITEAOF
* 2) Redis calls this function, that forks():
* 2a) the child rewrite the append only file in a temp file.
* 2b) the parent accumulates differences in server.aof_rewrite_buf.
* 3) When the child finished '2a' exists.
* 4) The parent will trap the exit code, if it's OK, will append the
* data accumulated into server.aof_rewrite_buf into the temp file, and
* finally will rename(2) the temp file in the actual file name.
* The the new file is reopened as the new append only file. Profit!
*/
int rewriteAppendOnlyFileBackground(void) {
pid_t childpid;
long long start; if (server.aof_child_pid != - || server.rdb_child_pid != -) return C_ERR;
if (aofCreatePipes() != C_OK) return C_ERR;
start = ustime();
if ((childpid = fork()) == ) {
char tmpfile[]; /* Child */
closeListeningSockets();
redisSetProcTitle("redis-aof-rewrite");
snprintf(tmpfile,,"temp-rewriteaof-bg-%d.aof", (int) getpid());
if (rewriteAppendOnlyFile(tmpfile) == C_OK) {
size_t private_dirty = zmalloc_get_private_dirty(); if (private_dirty) {
serverLog(LL_NOTICE,
"AOF rewrite: %zu MB of memory used by copy-on-write",
private_dirty/(*));
}
exitFromChild();
} else {
exitFromChild();
}
}
...
...
同样我们也看一下AOF的运作流程图:

- 所有的写入命令追加到aof缓冲区
- AOF缓冲区根据对应appendfsync配置向硬盘做同步操作
- 定期对AOF文件进行重写
- Redis重启时,可以加载AOF文件进行数据恢复
探索AOF文件
首先打开aof功能
127.0.0.1:> CONFIG SET appendonly yes
OK :M Apr ::53.940 * Background append only file rewriting started by pid
:M Apr ::53.964 * AOF rewrite child asks to stop sending diffs.
:C Apr ::53.965 * Parent agreed to stop sending diffs. Finalizing AOF...
:C Apr ::53.965 * Concatenating 0.00 MB of AOF diff received from parent.
:C Apr ::53.966 * SYNC append only file rewrite performed
:M Apr ::53.996 * Background AOF rewrite terminated with success
:M Apr ::53.996 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
:M Apr ::53.997 * Background AOF rewrite finished successfully
然后我们放一些数据,并执行bgrewriteaof命令
127.0.0.1:> CONFIG SET appendonly yes
OK
127.0.0.1:> set miao
OK
127.0.0.1:> set miao
OK
127.0.0.1:> lpush mlist
(integer)
127.0.0.1:> lpush mlist
(integer)
127.0.0.1:> lpush mlist
(integer)
127.0.0.1:> keys *
) "miao"
) "mlist"
接下来看一下aof文件:
*
$
SELECT
$ *
$
SET
$
miao
$ *
$
SELECT
$ *
$
lpush
$
mlist
$ *
$
lpush
$
mlist
$ *
$
lpush
$
mlist
$
这时候我们手动执行aof重写命令:
127.0.0.1:> bgrewriteaof
Background append only file rewriting started :M Apr ::31.017 * changes in seconds. Saving...
:M Apr ::31.017 * Background saving started by pid
:C Apr ::31.020 * DB saved on disk
:M Apr ::31.120 * Background saving terminated with success
:M Apr ::49.409 * Background append only file rewriting started by pid
:M Apr ::49.433 * AOF rewrite child asks to stop sending diffs.
:C Apr ::49.433 * Parent agreed to stop sending diffs. Finalizing AOF...
:C Apr ::49.434 * Concatenating 0.00 MB of AOF diff received from parent.
:C Apr ::49.434 * SYNC append only file rewrite performed
:M Apr ::49.533 * Background AOF rewrite terminated with success
:M Apr ::49.533 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
:M Apr ::49.534 * Background AOF rewrite finished successfully
然后再看一下文件:
*
$
SELECT
$ *
$
SET
$
miao
$ *
$
RPUSH
$
mlist
$ $ $
为什么AOF文件会变小?为了解决AOF文件会越来越大,Redis引入重写机制来缩小文件体积,体积变小因为:
- 多条写入命令可以合并成一条。比如上面的lpush命令了3次,最后合并成1条
- 重写后AOF文件只保留最终数据的写入命令
优缺点
AOF持久化方式的优点:
- 做到最多丢失1-2s内的数据(最多丢失2s数据,因为AOF追加阻塞)
AOF持久化方式的缺点:
- AOF文件比RDB文件大
- 可能导致追加阻塞
参考:
书籍参考和上文一样
https://www.cnblogs.com/huangxincheng/p/5010795.html
搞懂Redis RDB和AOF持久化及工作原理的更多相关文章
- redis的 rdb 和 aof 持久化的区别 [转]
aof,rdb是两种 redis持久化的机制.用于crash后,redis的恢复. rdb的特性如下: Code: fork一个进程,遍历hash table,利用copy on write,把整个d ...
- Redis中RDB和AOF持久化区别和联系
RDB和AOF持久化 RDB持久化 RDB是什么? 原理是redis会单独创建(fork) 一个与当前进程一模一 样的子进程来进行持久化,这个子进程的所有数据(变量.环境变量,程序程序计数器等) ...
- RDB和AOF持久化
RDB和AOF持久化 https://www.cnblogs.com/Tu9oh0st/p/11229317.html Redis提供了不同的持久化选项: RDB持久化以指定的时间间隔保存那个时间点的 ...
- [转载] redis 的两种持久化方式及原理
转载自http://www.m690.com/archives/371 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串 ...
- 搞懂分布式技术9:Nginx负载均衡原理与实践
搞懂分布式技术9:Nginx负载均衡原理与实践 本篇摘自<亿级流量网站架构核心技术>第二章 Nginx负载均衡与反向代理 部分内容. 当我们的应用单实例不能支撑用户请求时,此时就需要扩容, ...
- redis的 rdb 和 aof 持久化的区别
aof,rdb是两种 redis持久化的机制.用于crash后,redis的恢复. rdb的特性如下: Code: fork一个进程,遍历hash table,利用copy on write,把整个d ...
- Redis的RDB和AOF持久化
RDB 持久化:在指定的时间间隔内生成数据集的时间点快照. AOF 持久化:记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集. RDB 它只保存了 Redis 在某个 ...
- redis基础:redis下载安装与配置,redis数据类型使用,redis常用指令,jedis使用,RDB和AOF持久化
知识点梳理 课堂讲义 课程计划 1. REDIS 入 门 (了解) (操作) 2. 数据类型 (重点) (操作) (理解) 3. 常用指令 (操作) 4. Jedis (重点) (操作) ...
- Redis - 2 - 聊聊Redis的RDB和AOF持久化 - 更新完毕
1.RDB 1.1).RDB是什么? RDB,全称Redis Database RDB是Redis进行持久化的一种方式,当然:Redis默认的持久化方式也是RDB 1.2).Redis配置RDB 1. ...
随机推荐
- [Noi2016]区间 BZOJ4653 洛谷P1712 Loj#2086
额... 首先,看到这道题,第一想法就是二分答案+线段树... 兴高采烈的认为我一定能AC,之后发现n是500000... nlog^2=80%,亲测可过... 由于答案是求满足题意的最大长度-最小长 ...
- XSS SQL CSRF
XSS(Cross Site Script,跨站脚本攻击)是向网页中注入恶意脚本在用户浏览网页时在用户浏览器中执行恶意脚本的攻击方式.跨站脚本攻击分有两种形式:反射型攻击(诱使用户点击一个嵌入恶意脚本 ...
- 树莓派使用modbus与stm32通信
树莓派+stm32开发板通信树莓派上使用java+jamod实现.jamod官网stm32使用freemodbus实现
- Java相关面试题总结
本文分为十九个模块,分别是: Java 基础.容器.多线程.反射.对象拷贝.Java Web .异常.网络.设计模式.Spring/Spring MVC.Spring Boot/Spring Clou ...
- ES 12 - 配置使用Elasticsearch的动态映射 (dynamic mapping)
目录 1 动态映射(dynamic mapping) 1.1 什么是动态映射 1.2 体验动态映射 1.3 搜索结果不一致的原因分析 2 开启dynamic mapping策略 2.1 约束策略 2. ...
- 你真的了解字典(Dictionary)吗?
从一道亲身经历的面试题说起 半年前,我参加我现在所在公司的面试,面试官给了一道题,说有一个Y形的链表,知道起始节点,找出交叉节点. 为了便于描述,我把上面的那条线路称为线路1,下面的称为线路2. 思路 ...
- 我的Windows装机必备软件与生产力工具
目录 系统工具 工作学习 开发工具 VS插件 2018年12月21日,最近要装新电脑,借此将自己常用的工具总结一下. 系统工具 wox,软件快速启动工具,有翻译等插件 everything,本地文件文 ...
- Postgres全文搜索功能
当构建一个Web应用时,经常被要求加上搜索功能.其实有时候我们也不知道我要搜索个啥,反正就是要有这个功能.搜索确实很重要的特性,这也是为什么像Elasticsearch和Solr这样基于Lucene的 ...
- Postman 安装
前言 安装前的准备: 1.Chrome 浏览器的扩展插件来进行的安装,并非单独应用程序. 2.电脑上已经安装了 Chrome 浏览器 3.本文章适用操作系统 window7 一,非官方安装 个人不建 ...
- ceph 高级运维
追查系统故障,需要找到问题的根源安置组和相关的OSD. 一般来说,归置组卡住时 ceph 的自修复功能往往无能为力,卡住的状态细分为: 1. unclean 不干净:归置组里有些对象的复制数未达到期望 ...