django优化和扩展(一)
mysql优化基础
进行django产品开发或上线之前,有必要了解一下mysql的基础知识,orm太过抽象,导致很多朋友对于mysql了解得太少,而且orm不像sqlalchemy那样可以跟mysql走的那么近!如果要设计出合理的表结构(在orm中就是model类),显然把一个ip设置成64个字符是大大地浪费。本文结合mysql手册,做一些建表优化。
一、尽可能地使用最有效(最小)的数据类型
class Customer(models.Model):
qq = models.CharField(u"QQ号",max_length=64,unique=True)
name = models.CharField(u"姓名",max_length=32,blank=True,null=True)
phone = models.BigIntegerField(u'手机号',blank=True,null=True)
stu_id = models.CharField(u"学号",blank=True,null=True,max_length=64)
上面这个类从优化角度显然是不合理的,一个qq号占64个字符,姓名32个字符,手机号用的bigint,学号64位,一行数据得占多大空间,下面两张图写明了主要数据类型的区别!
(一)、整形列的应用
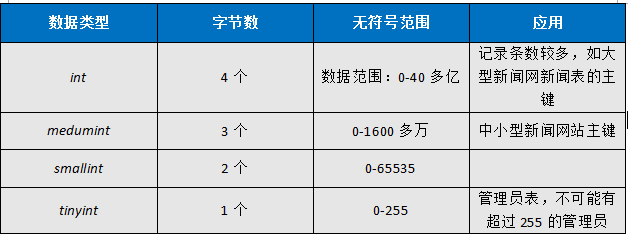
整形列的选择要慎重,一定要坚持最小化的原则,而且一定要选择无符号的整数,在orm无符号的声明如下:
class cj_user(models.Model):
cjid = models.PositiveIntegerField() # Positive 开头一般都是无符号
# 在声明非主键字段时可以如上应用,如果优化主键,必须重写AutoField,因为orm默认生成的是int类型,且是有符号的,优化方法可以参照我最后写的
(二)、char、varchar、text的区别
讲之前问2个问题:
1,char(5)和varchar(5) 能不能存下'abcdefg'?
2,char(5)和varchar(20)同样存'abcd'各占几个字符?几个字节?
()中的数字都是字符数,如果要算字节数必须utf-8*3 gbk*2,但varchar是变长,内容多少就占多少,他有一点比较特殊,varchar(20)存'abc'的时候占4个字符,因为在末尾加\0
在工作中应尽量使用定长,如char和上面的整形列 都是定长,有利加速,变长通常用一对一的形式存在附加表中,也可以综合应用,但最佳的优化还是分表存储!手机,身份证、姓名、密码都是比较固定的字段,如密码,无论设几位,最后都会被加密成32位字符串!以下是我的用户表( FixCharField是我自定义的char,因为在orm中不支持char,CharField生成的是varchar变长类型。在本文的最后我会讲一下,如何自定义!)
class hwj_user(models.Model):
xm = FixCharField(max_length=4)
tel = FixCharField(max_length=11)
sfz = FixCharField(max_length=18)
pwd = FixCharField(max_length=32)
注:varchar(max)的单位是字节即最多存65535个字节,以utf-8为例,约2万多个汉字!
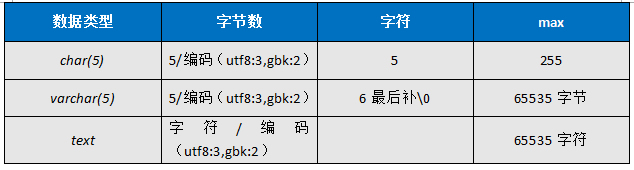
(三)主键和非空字段要用not null
手册上说:如果可能,声明列为NOT NULL。它使任何事情更快而且每列可以节省一位。这点orm中已经默认这么干了,当然这里也建议你不要把
null=True写上去
二、慎用索引
索引是会加快速度,但我觉除了主键、多对多的表无法避免外,其他都要慎用,因为索引会加快查询速度,却会降低写入速度,如果你的表有类似频繁写入的功能,如抢购等,那你就不要使用,像唯一这种都属于索引,尽量在业务中去判断他是否存在。
三、多设默认值
默认值的设置也是优化的一方面,也能使数据层避免产生错误,即便是not null的列,也应该给他设上default='',数值类型default=0等等!
四、随机排序的实现
由于orm不支持随机排序,如果要实现数据的随机排机,只能借助于python(也可以重写oder_by但太复杂了)
ids = models.Tk.objects.filter(eid_id=exam_data.id).all().values('id')
rand_id=[]
for id in ids:
rand_id.append(id["id"])
rand_num = random.sample(rand_id,5)
print(rand_num)
tks = models.Tk.objects.filter(eid_id=exam_data.id,id__in=rand_num).all()
1,先取出所有的id,把他们放到列表
2,利用random.sample 在列中随机选择5个id
3,利用orm的id__in过滤出id所在行的记录
五、自定义数据类型
class FixCharField(models.Field):
def __init__(self, *args, **kwargs):
super(FixCharField, self).__init__(*args, **kwargs) def db_type(self, connection):
return 'char(%s)' % self.max_length class hwj(models.Model):
my_field = FixCharField(max_length=25)
只是重写了,具体可看django源码
六、模板中的计数 上层循环计数
有的时候要输出上层循环的计数值,在相关书籍上也只看到当前循环{{ forloop.counter }},看了底层才知道还有forloop.parentloop.counter
以向是我模板中用反向查找实现了在题目下显示题目的方法,用嵌套循环实现的!
{% for o in tks %}
<div class="panel panel-info">
<!-- Default panel contents -->
<div class="panel-heading" name="ks{{ o.attr }}">{{ forloop.counter }}、{{ o.subject }}</div>
<div class="panel-body">
{% for i in o.op_set.all %}
<p><input type="radio" name="dx{{ forloop.parentloop.counter }}" title="{{o.answer}}" class="option-input radio" value="{{i.opstr}}"> {{i.opstr}} {{i.opname}}</p>
<p style="padding:0; margin:0; height:5px;"></p>
{% endfor %}
马上开会了,今天就写到这里。
django优化和扩展(一)的更多相关文章
- Django 优化杂谈
Django 优化杂谈 Apr 21 2017 总结下最近看过的一些文章,然后想到的一些优化点,整理一下. 数据库连接池 http://mt.dbanotes.net/arch/instagram.h ...
- Python学习---Django的request扩展[获取用户设备信息]
关于Django的request扩展[获取用户设备信息] settings.py INSTALLED_APPS = [ ... 'app01', # 注册app ] STATICFILES_DIRS ...
- Flume FileChannel优化(扩展)实践指南
本文系微博运维数据平台(DIP)在Flume方面的优化扩展经验总结,在使用Flume FileChannel的场景下将吞吐率由10M/s~20M/s提升至80M/s~90M/s,分为四个部分进行介绍: ...
- 谱聚类算法(Spectral Clustering)优化与扩展
谱聚类(Spectral Clustering, SC)在前面的博文中已经详述,是一种基于图论的聚类方法,简单形象且理论基础充分,在社交网络中广泛应用.本文将讲述进一步扩展其应用场景:首先是User- ...
- django用户信息扩展
Django封装了好多东西,拿来用就可以了,帮我们封装类用户的登录认证,用户的表 所以Django自带有用户表,当扩展用户表后一些表就会被替换 用户认证相关的 功能放在django.contri ...
- PostgreSQL 欺骗优化器之扩展统计信息
一.什么是扩展统计 扩展统计对象, 追踪指定表.外部表或物化视图的数据. 目前支持的种类: 启用n-distinct统计的 ndistinct. 启用功能依赖性统计的dependencies. 启用最 ...
- 优化与扩展Mybatis的SqlMapper解析
接上一篇博文,这一篇来讲述怎么实现SchemaSqlMapperParserDelegate——解析SqlMapper配置文件. 要想实现SqlMapper文件的解析,还需要仔细分析一下mybatis ...
- ecshop二次开发系统缓存优化之扩展数据缓存的必要性与方法
1.扩展数据缓存的必要性 大家都知道ecshop系统使用的是静态模板缓存,在后台可以设置静态模板的缓存时间,只要缓存不过期,用户访问页面就相当于访问静态页面,速度可想而知,看似非常完美,但是ecsho ...
- django优化--ORM查询
ORM提供了两个方法用来优化查询效率 1. select_related 有两张表:表结构如下: class Scheme(models.Model): """ 套餐类 ...
随机推荐
- B/S和C/S架构图解
软件:B/S和C/S两种架构模式.接下来用三张图片解释,什么是B/S什么是C/S. 图片一:软件架构模式 图片二:C/S结构模式 图片三:B/S结构模式 相信图解胜过冗长文字的解释,什么是B/S什么是 ...
- Css技术入门笔记01
在学习html的时候,html中的标签都具备了特定功能,或者含义,以及相应的样式效果.可是在有些时候我们可能仅仅希望使用 html标签把要显示的数据封装起来,而不需要任何的样式效果.这时就需要单独的标 ...
- XML 处理利器 : XStream
XStream 概述 XStream 是一套简洁易用的开发类库,用于将Java对象序列化为XML或者将XML反序列化为JAVA对象,是JAVA对象和XML之间一个双向转换器. 举例 ...
- 【Android 应用开发】分析各种Android设备屏幕分辨率与适配 - 使用大量真实安卓设备采集真实数据统计
.主要是为了总结一下 对这些概念有个直观的认识; . 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/198 ...
- Leetcode_141_Linked List Cycle
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/42833739 Given a linked list, d ...
- SpriteBuilder中pivot关节中的Collide bodies属性
在SpriteBuilder中,pivot类型的关节表示两个物体围绕一个中心旋转运动的关节,也称之为pin关节. 默认情况下Collide bodies是不选的.因为在大多数情况下你不希望pivot连 ...
- LDA实现
topic model本质上就一个套路,在doc-word user-url user-doc等关系中增加topic层,扩充为2层结构,一方面可以降维,另一方面挖掘深层次的关系,用户doc word ...
- PS 图像调整算法——黑白
这个算法是参考自 阿发伯 的博客: http://blog.csdn.net/maozefa 黑白调整 Photoshop CS的图像黑白调整功能,是通过对红.黄.绿.青.蓝和洋红等6种颜色的比例调节 ...
- C语言之可变参实现scanf函数
既然有printf函数可变参实现,那就一定有scanf函数的可变参实现.废话不多说,源码奉上: 本源码不过多分析,如要明白原理,请翻本博客以往的文章看说明. 欢迎关注新浪微博:http://weibo ...
- 关于UIView中相关坐标及改变的相关方法
// 将像素point由point所在视图转换到目标视图view中,返回在目标视图view中的像素值 - (CGPoint)convertPoint:(CGPoint)point toView:(UI ...