机器学习:PCA(降噪)
一、噪音
- 噪音产生的因素:可能是测量仪器的误差、也可能是人为误差、或者测试方法有问题等;
- 降噪作用:方便数据的可视化,使用样本特征更清晰;便于算法操作数据;
- 具体操作:从 n 维降到 k 维,再讲降维后的数据集升到 n 维,得到的新的数据集为去燥后的数据集;
- 降维:X_reduction = pca.transform ( X )
- 升维:X_restore = pca.inverse_transform ( X_reduction ),数据集 X_restore 为去燥后的数据集;
二、实例
1)例一
模拟并绘制样本信息
import numpy as np
import matplotlib.pyplot as plt X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100, size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 5, size=100) plt.scatter(X[:, 0], X[:, 1])
plt.show()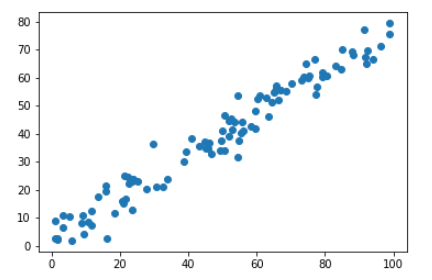
- 实际上,样本的状态看似在直线上下抖动式的分布,其实抖动的距离就是噪音;
使用 PCA 降维,达到降噪的效果
- 操作:数据降维后,再升到原来维度;
- inverse_transform(低维数据):将低维数据升为高维数据
from sklearn.decomposition import PCA pca = PCA(n_components=1)
pca.fit(X)
X_reduction = pca.transform(X) # inverse_transform(低维数据):将低维数据升为高维数据
X_restore = pca.inverse_transform(X_reduction) plt.scatter(X_restore[:,0], X_restore[:,1])
plt.show()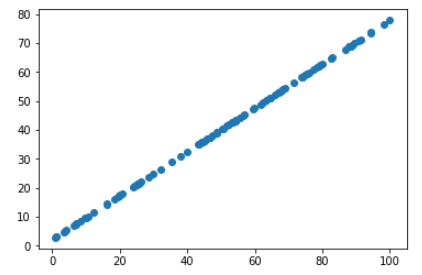
2)例二(手写识别数字数据集)
加载数据集(人为加载噪音:noisy_digits)
from sklearn import datasets digits = datasets.load_digits()
X = digits.data
y = digits.target # 在数据集 X 的基础上创建一个带噪音的数据集
noisy_digits = X + np.random.normal(0, 4, size=X.shape)从带有噪音的数据集 noisy_digits 中提出示例数据集 example_digits
example_digits = noisy_digits[y==0,:][:10]
for num in range(1, 10):
X_num = noisy_digits[y==num,:][:10]
# np.vstack([array1, array2]):将两个矩阵在水平方向相加,增加列数;
# np.hstack([array1, array2]):将两矩阵垂直相加,增加行数;
example_digits = np.vstack([example_digits, X_num]) example_digits.shape
# 输出:(100, 64)绘制示例数据集 example_digits(带噪音)
def plot_digits(data):
fig, axes = plt.subplots(10, 10, figsize=(10,10),
subplot_kw = {'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(data[i].reshape(8, 8),
cmap='binary', interpoltion='nearest',
clim=(0, 16)) plt.show() plot_digits(example_digits)
降噪数据集 example_digits
# 如果噪音比较多,保留较少信息(此例中只保留 50% 的信息)
pca = PCA(0.5)
pca.fit(noisy_digits) # 查看最终的样本维度
pca.n_components_
# 输出:12 # 1)降维:将数据集 example_digits 降维,得到数据集 components
components = pca.transform(example_digits) # 2)升维:将数据集升到原来维度(100, 64)
filtered_digits = pca.inverse_transform(components) # 绘制去燥后的数据集 filtered_digits
plot_digits(filtered_digits)
机器学习:PCA(降噪)的更多相关文章
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- 机器学习--PCA降维和Lasso算法
1.PCA降维 降维有什么作用呢?数据在低维下更容易处理.更容易使用:相关特征,特别是重要特征更能在数据中明确的显示出来:如果只有两维或者三维的话,更便于可视化展示:去除数据噪声降低算法开销 常见的降 ...
- 机器学习--PCA算法代码实现(基于Sklearn的PCA代码实现)
一.基于Sklearn的PCA代码实现 import numpy as np import matplotlib.pyplot as plt from sklearn import datasets ...
- [机器学习 ]PCA降维--两种实现 : SVD或EVD. 强力总结. 在鸢尾花数据集(iris)实做
PCA降维--两种实现 : SVD或EVD. 强力总结. 在鸢尾花数据集(iris)实做 今天自己实现PCA,从网上看文章的时候,发现有的文章没有搞清楚把SVD(奇异值分解)实现和EVD(特征值分解) ...
- 机器学习(4)——PCA与梯度上升法
主成分分析(Principal Component Analysis) 一个非监督的机器学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化.去噪 通过映射,我们可以 ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- 131.008 Unsupervised Learning - Principle component Analysis |PCA | 非监督学习 - 主成分分析
@(131 - Machine Learning | 机器学习) PCA是一种特征选择方法,可将一组相关变量转变成一组基础正交变量 25 PCA的回顾和定义 Demo: when to use PCA ...
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
- 【笔记】使用PCA对数据进行降噪(理解)
使用PCA对数据进行降噪(使用手写数字实例) (在notebook中) 加载库并制作虚拟的数据并进行绘制 import numpy as np import matplotlib.pyplot as ...
- < AlexNet - 论文研读个人笔记 >
Alexnet - 论文研读个人笔记 一.论文架构 摘要: 简要说明了获得成绩.网络架构.技巧特点 1.introduction 领域方向概述 前人模型成绩 本文具体贡献 2.The Dataset ...
随机推荐
- HBase-存储-概览
概览 HBase主要处理两种文件:一种是预写日志(Write-Ahead Log,WAL),另一种是实际的数据文件.这两种文件主要由HRegionServer管理.在某些情况下,HMaster也可以进 ...
- 什么是 RegExp?
RegExp 是正则表达式的缩写. regular expression 当您检索某个文本时,可以使用一种模式来描述要检索的内容.RegExp 就是这种模式. 简单的模式可以是一个单独的字符. 更复杂 ...
- Oracle中的BLOB和CLOB【转载】
原文地址:http://jelly.iteye.com/blog/65796 一.区别和定义 LONG: 可变长的字符串数据,最长2G,LONG具有VARCHAR2列的特性,可以存储长文本一个表中最多 ...
- 判断一个浏览器是否支持opacity
支持opacity的浏览器,总会将opacity值规范成小于1.0且以0开头的值.例如,如果将opacity指定为:.5,原始支持opacity的浏览器就会将该值规范为0.5,而不支持opacity的 ...
- iOS系统声音服务(System Sound Services)
系统声音服务(System Sound Services)提供了一个接口,用于播放不超过30秒的声音.它支持的文件格式有限,具体地说只有CAF.AIF和使用PCM或IMA/ADPCM数据的WAV文件. ...
- jedis提纲
A01 - jedis库介绍 A01 - 在多线程下使用Jedis A01 - Jedis的八种调用方式 A02 - API使用文档 A02 - Jedis代码编程使用(简单的使用) A03 ...
- window上脚本到linux上不能用
window上的脚本一定要用dos2unix 文件名处理一下
- Engineer manager
your tasks and responsibilities Position: Major Tasks Lead site project management to ensure all p ...
- MySQL引擎各个引擎对比介绍
1.什么是存储引擎? 存储引擎类似于录制的视频文件,可以转换成不同的格式,如MP4,avi等格式,而存储在我们的磁盘上也会存在于不同类型的文件系统中如:Windows里常见的NTFS,fat32等.存 ...
- JFreeChart - 简记
一.步骤:(发现另一位博主写的更详细:https://www.cnblogs.com/dmir/p/4976550.html) 创建数据集(准备数据) 根据数据集生成JFreeChart对象,并对其做 ...