TinkerPop中的遍历:图的遍历步骤(1/3)
图遍历步骤(Graph Traversal Steps)
在最一般的层次上,Traversal<S,E>实现了Iterator,S代表起点,E代表结束。遍历由四个主要组成部分组成:
- Step<S,E>: 一个用来从S产生E的方法。Step在遍历中是链式的。
- TraversalStrategy: 拦截器方法来改变遍历的执行(例如查询重写)。
- TraversalSideEffects: 键/值对,可用于存储有关遍历的全局信息。
- Traverser: the object propagating through the Traversal currently representing an object of type T.
示例数据
示例数据大多出自于Modern数据,如下图:
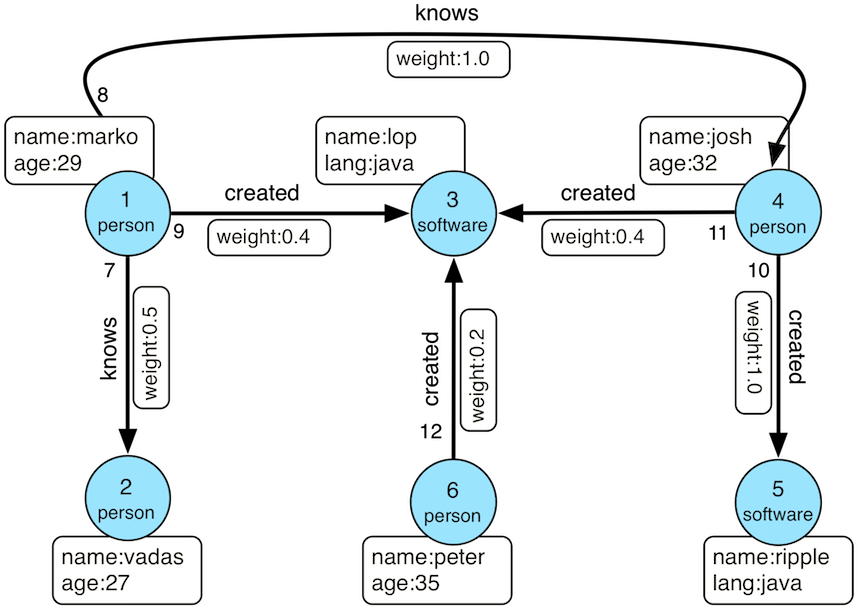
可以通过下图加载Modern图数据,并获取图遍历引用g:
gremlin> graph = TinkerFactory.createModern()
gremlin> g = graph.traversal()
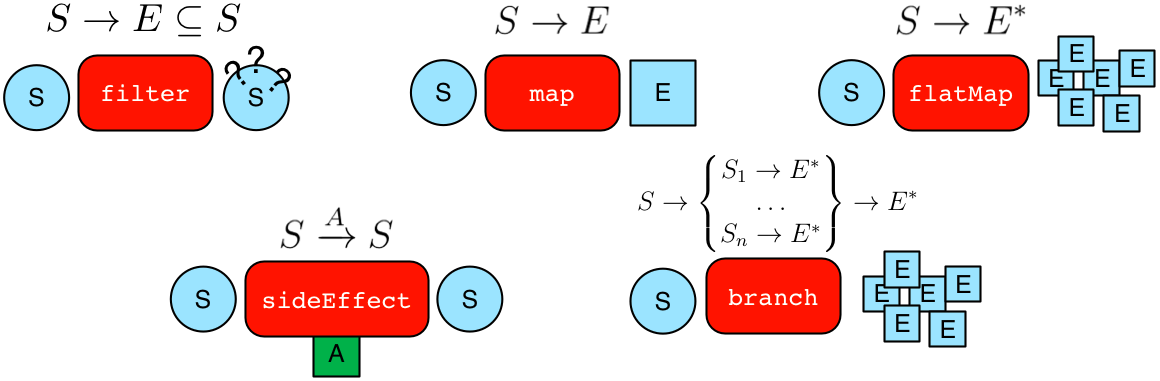
1. General Steps
| Step | Description |
|---|---|
map(Traversal<S, E>) map(Function<Traverser<S>, E>) |
将运行程序映射到类型E的某个对象,以便下一步处理。 |
flatMap(Traversal<S, E>) flatMap(Function<Traverser<S>, Iterator<E>>) |
将遍历器映射到流向下一步的E对象的迭代器。 |
filter(Traversal<?, ?>) filter(Predicate<Traverser<S>>) |
将运行程序映射为true或false,其中false将不会将运行程序传递给下一步。 |
sideEffect(Traversal<S, S>) sideEffect(Consumer<Traverser<S>>) |
在移动器上执行一些操作,并将其传递到下一步。 |
branch(Traversal<S, M>) branch(Function<Traverser<S>,M>) |
将移动器拆分为由M令牌索引的所有遍历。 |
- filter步骤的示例
gremlin> g.V().filter(label().is('person'))
- map步骤的示例
gremlin> g.V(1).out().map(values('name'))
- sideEffect步骤的示例
gremlin> g.V().hasLabel('person').sideEffect(System.out.&println)
- branch步骤的示例
gremlin> g.V().branch(values('name')).
option('marko', values('age')).
option(none, values('name'))
2. Terminal Steps
一些步骤不返回遍历,而是执行遍历并返回结果。这些步骤就是Terminal步骤(终端步骤),并且通过下面的示例来解释它们。
gremlin> g.V().out('created').hasNext()
==>true
gremlin> g.V().out('created').next()
==>v[3]
gremlin> g.V().out('created').next(2)
==>v[3]
==>v[5]
gremlin> g.V().out('nothing').tryNext()
==>Optional.empty
gremlin> g.V().out('created').toList()
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.V().out('created').toSet()
==>v[3]
==>v[5]
gremlin> g.V().out('created').toBulkSet()
==>v[3]
==>v[3]
==>v[3]
==>v[5]
gremlin> results = ['blah',3]
==>blah
==>3
gremlin> g.V().out('created').fill(results)
==>blah
==>3
==>v[3]
==>v[5]
==>v[3]
==>v[3]
注意几点:
- 上述
tryNext()将返回一个Optional的,是一个hasNext()/next()的组合。 toSet()与toBulkSet()都返回一个去重的集合,区别在于后者通过加权处理重复对象。
3. AddEdge Step
推理是明确显示数据中隐含的内容的过程。图中显式的是图形的对象,即顶点和边。图中隐含的是遍历。即,通过遍历揭示了意义,而所谓的意义是有遍历的定义来决定的。
比如定义一个遍历,找出节点的合作开发者(co-developer),并在这种关系(边)上添加属性“year”:
gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')).
addE('co-developer').from('a').property('year',2009)
如此,曾经隐含的含义可以可以通过addE()-step(map/sideEffect)来显式。
Question
这里addE()-step(map/sideEffect)意味着addE()步骤产生了map和sideEffect普通步骤的效果吗?
4. AddVertex Step
addV()步骤用于向图中添加顶点(map/sideEffect)。
增加顶点,示例如下:
gremlin> g.addV('person').property('name','stephen')
gremlin> g.V().outE('knows').addV().property('name','nothing')
Question
gremlin> g.V().outE('knows').addV().property('name','nothing')这种方式并没有增加节点之间的关联(边),那么它的意义在哪里?
5. AddProperty Step
property() 步骤用于向图形元素添加属性(sideEffect)。与addV()和addE()不同,property()是一个完全的sideEffect步骤,它不会返回其创建的属性,而是返回添加属性的元素。那么,可以推测出在addV()或addE()步骤后使用property()步骤可以在创建顶点或边的时候一次性创建多个属性。
- 为一个节点添加一个属性
gremlin> g.V(1).property('country','usa')
- 为一个节点添加多个属性
gremlin> g.V(1).property('city','santa fe').property('state','new mexico').valueMap()
- (对顶点)添加多值属性(Cardinality.list)
gremlin> g.V(1).property(list,'age',35)
- 添加元属性
gremlin> g.V(1).properties('name').property('author','inspur')
6. Aggregate Step
aggregate()步骤(sideEffect)用于将遍历特定点处的所有对象(贪婪评估方式eager evaluation)聚合到集合中。
aggregate step

gremlin> g.V(1).out('created').aggregate('x').in('created').out('created').
where(without('x')).values('name')
==>ripple
7. And Step
and()步骤确保所有提供的遍历产生结果(filter)。请参阅or()。
gremlin> g.V().and(
outE('knows'),
values('age').is(lt(30))).
values('name')
==>marko
使用or()步骤会产生以下结果:
gremlin> g.V().or(
outE('knows'),
values('age').is(lt(30))).
values('name')
==>marko
==>vadas
8. As Step
as()步骤不是一个真正的步骤,而是一个类似于by()和option()的“调节器”。使用as(),可以为步骤提供标签,后续的步骤或数据结果可以通过使用这些标签访问这些步骤。
gremlin> g.V().as('a').out('created').as('b').select('a','b')
==>[a:v[1],b:v[3]]
==>[a:v[4],b:v[5]]
==>[a:v[4],b:v[3]]
==>[a:v[6],b:v[3]]
一步可以有任何数量的与之相关联的标签。这对于在将来的步骤中多次引用相同的步骤很有用:
gremlin> g.V().hasLabel('software').as('a','b','c').
select('a','b','c').
by('name').
by('lang').
by(__.in('created').values('name').fold())
==>[a:lop,b:java,c:[marko,josh,peter]]
==>[a:ripple,b:java,c:[josh]]
Note
以上__.(两个_)通过匿名方式产生了GraphTraversal。并使用了后续介绍的fold()步骤。
9. Barrier Step
barrier() 步骤将延迟遍历管道转换为批量同步管道。可类比线程同步中的栅栏。在以下情况下,此步骤很有用:
- 使用在需要栅栏的场景
- 进行“膨胀优化”(bulking optimization)
膨胀优化对于某些程序执行效率的提高是非常明显的,如下示例:
gremlin> g = graph.traversal().withoutStrategies(LazyBarrierStrategy) //屏蔽默认的遍历策略
gremlin> clockWithResult(1){g.V().both().both().both().count().next()} //未使用barrier
gremlin> clockWithResult(1){g.V().both().barrier().both().barrier().both().barrier().count().next()} //使用barrier
上述优化过程需要去掉LazyBarrierStrategy 遍历策略,即默认情况下遍历器已经使用LazyBarrierStrategy 进行了优化(barrier()步骤会在适当的情况下自动添加)。
- 支持参数
如果barrier()被提供一个整数参数n,那么在将聚合的遍历器入下一个步骤之前,栅栏只会在其屏障中保留n个唯一的遍历器。
10. By Step
如果一个步骤能够接受遍历、函数或比较器等,那么by()是添加它们的手段。
gremlin> g.V().group().by(bothE().count()) //将元素按其边数进行分组,属于接受“遍历”的情况
==>[1:[v[2],v[5],v[6]],3:[v[1],v[3],v[4]]]
gremlin> g.V().group().by(bothE().count()).by('name') //将通过其名称(元素属性投影)处理分组的元素
==>[1:[vadas,ripple,peter],3:[marko,lop,josh]]
gremlin> g.V().group().by(bothE().count()).by(count()) //将计算每个组中的元素数量
==>[1:3,3:3]
- 哪些步骤支持
by()
以下步骤支持by(),注意有些步骤支持一个by(),有些步骤支持多个by(),使用时需要参考文档。
dedup()
cyclicPath()
simplePath()
sample()
where()
groupCount()
group()
order()
path()
project()
select()
tree()
aggregate()
store()
11. Cap Step
cap()用来将一些副作用步骤产生的结果发射(emits)出来。
如下使用label进行分组统计,并使用cap()将分组结果展现出来:
gremlin> g.V().groupCount('a').by(label) //不使用cap()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V().groupCount('a').by(label).cap('a') //使用cap()
==>[software:2,person:4]
另外,cap()支持多个key值,不同的key会组成 Map<String,Object>效果展现出来。
12. Choose Step
choose()将当前遍历器路由到特定的遍历分支选项。可用来实现if-then-else语法结构。
判断条件可以放在choose步骤中,也可以放在option步骤中:
- choose中进行判断
gremlin> g.V().hasLabel('person').
choose(values('age').is(lte(30)),
__.in(),
__.out()).values('name')
==>marko
==>ripple
==>lop
==>lop
- option中进行判断
gremlin> g.V().hasLabel('person').
choose(values('age')).
option(27, __.in()).
option(32, __.out()).values('name')
==>marko
==>ripple
==>lop
13. Coalesce Step
coalesce() - 步骤按顺序评估提供的遍历,并返回发出至少一个元素的第一个遍历。
即coalesce()可以传入多个遍历,并对这些遍历按照顺序进行评估。若某个元素匹配上某个遍历,那么返回该元素在该遍历上产生的结果,然后跳到下一个元素进行相同的操作。
比如,当person含有nickname则返回nickname,当含有name则返回name;不会即返回nickname又返回name;当既没有nickname也没有name,则返回空。
gremlin> g.V().hasLabel('person').coalesce(values('nickname'), values('name'))
==>okram
==>vadas
==>josh
==>peter
14. Coin Step
要随机过滤出一个遍历器,请使用coin() 步骤(filter)。
gremlin> g.V().coin(0.0) //不返回节点
gremlin> g.V().coin(0.5) //随机返回节点,注意它并不是随机返回一半
gremlin> g.V().coin(1.0) //返回全部
15. Constant Step
要为运行程序指定常量值,请使用常量constant() 步骤(map)。对于诸如choose()或`coalesce() 的条件步骤通常很有用。
gremlin> g.V().hasLabel('person').coalesce(values('nickname11'), values('name11'),constant("haha"))
==>haha
==>haha
==>haha
==>haha
16. Count Step
属于map步骤范畴。举例如下:
gremlin> g.V().count()
==>6
gremlin> g.V().hasLabel('person').count()
==>4
该步骤是减少栅栏的步骤(reducing barrier step),意味着所有先前的遍历器被折叠成新的遍历器。
gremlin> g.V().hasLabel('person').outE('created').path()
==>[v[1],e[9][1-created->3]]
==>[v[4],e[10][4-created->5]]
==>[v[4],e[11][4-created->3]]
==>[v[6],e[12][6-created->3]]
gremlin> g.V().hasLabel('person').outE('created').count()
==>4
gremlin> g.V().hasLabel('person').outE('created').count().path()
==>[4]
17. CyclicPath Step
每个遍历器在遍历图形的时候会维护其历史,即其路径。如果重要的是遍历器重复它的过程,那么应该使用cyclic()- 路径(filter)。
该步骤分析到目前为止的运行程序的路径,并且如果有任何重复,则遍历器被过滤掉以免重复遍历。
如果需要非循环行为,请参阅simplePath()。
gremlin> g.V(1).both().both().cyclicPath().path() //查看循环的遍历路径
==>[v[1],v[3],v[1]]
==>[v[1],v[2],v[1]]
==>[v[1],v[4],v[1]]
gremlin> g.V(1).both().both().simplePath().path() //查看非循环的遍历路径
==>[v[1],v[3],v[4]]
==>[v[1],v[3],v[6]]
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
18. Dedup Step
使用dedup()步骤(filter),重复的对象将从遍历流中删除。
gremlin> g.V().values('lang')
==>java
==>java
gremlin> g.V().values('lang').dedup()
==>java
19. Drop Step
drop()步骤(filter/sideEffect)用于从图形中删除元素和属性(即删除)。它是一个过滤器步骤,因为遍历不产生传出对象。
gremlin> g.V().outE().drop() //删除边
gremlin> g.E()
gremlin> g.V().properties('name').drop() 删除属性
gremlin> g.V().valueMap()
==>[age:[29]]
==>[age:[27]]
==>[lang:[java]]
==>[age:[32]]
==>[lang:[java]]
==>[age:[35]]
gremlin> g.V().drop() //删除图
gremlin> g.V()
20. Explain Step
explain() 步骤(terminal)将返回一个TraversalExplanation。遍历说明详细说明了如何根据注册的遍历策略编译遍历(在explain()之前)。
第一列是应用的遍历策略。第二列是遍历策略类别:[D]ecoration,[O]ptimization,[P]rovider optimization,[F]inalization和[V]erification。最后,第三列是遍历后策略应用的状态。最终遍历是最终的执行计划。
21. Fold Step
有些情况下,遍历流需要“栅栏”来聚合所有对象并产生作为聚合函数的计算结果。fold()步骤(map)就是这样的例子。
gremlin> g.V(1).out('knows').values('name')
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name').fold() //简单合并
==>[vadas,josh]
gremlin> g.V(1).out('knows').values('name').fold(0) {a,b -> a + b.length()} //统计name值的字符长度
==>9
gremlin> g.V(1).out('knows').values('name').fold(0) {a,b -> a + b} //合并所有名字为一个长串
==>vadasjosh
22. Graph Step
V() 步骤通常用于启动GraphTraversal,但也可以在遍历中间使用。
gremlin> g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person')
==>e[13][1-uses->3]
==>e[14][1-uses->5]
==>e[15][2-uses->3]
==>e[16][2-uses->5]
==>e[17][4-uses->3]
==>e[18][4-uses->5]
23. From Step
from()不是一个真正的步骤,而是类似by()和as()等的步骤调节器(step-modulator)。如果一个步骤可以接受一个遍历器或者String,那么可以用from()。
- 接受
from()的步骤
simplePath()
cyclicPath()
path()
addE()
TinkerPop中的遍历:图的遍历步骤(1/3)的更多相关文章
- TinkerPop中的遍历:图的遍历步骤(3/3)
48 Project Step project() 步骤(map)将当前对象投射到由提供的标签键入的Map<String,Object>中. gremlin> g.V().out(' ...
- TinkerPop中的遍历:图的遍历步骤(2/3)
24 Group Step 有时,所运行的实际路径或当前运行位置不是计算的最终输出,而是遍历的一些其他表示.group()步骤(map / sideEffect)是根据对象的某些功能组织对象的一个方法 ...
- TinkerPop中的遍历:图的遍历策略
遍历策略 一个TraversalStrategy分析一个遍历,如果遍历符合它的标准,可以相应地改变它.遍历策略在编译时被执行,并构成Gremlin遍历机的编译器的基础.有五类策略分列如下: decor ...
- TinkerPop中的遍历:图的遍历中谓词、栅栏、范围和Lambda的说明
关于谓词的注意事项 P是Function<Object,Boolean>形式的谓词.也就是说,给定一些对象,返回true或false.所提供的谓词在下表中概述,并用于各种步骤,例如has( ...
- Python 非递归遍历图
class Queue: def __init__(self,max_size): self.max_size = int(max_size) self.queue = [] def put(self ...
- 图的遍历BFS广度优先搜索
图的遍历BFS广度优先搜索 1. 简介 BFS(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点"死磕到底"的思维不同,广度优先 ...
- 【PHP数据结构】图的遍历:深度优先与广度优先
在上一篇文章中,我们学习完了图的相关的存储结构,也就是 邻接矩阵 和 邻接表 .它们分别就代表了最典型的 顺序存储 和 链式存储 两种类型.既然数据结构有了,那么我们接下来当然就是学习对这些数据结构的 ...
- 图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次.(连通图与非连通图) 深度优先遍历(DFS): 1.访问指定的起始顶点: 2.若当前访问的顶点的邻接顶点有未被访问的,则 ...
- Java中关于HashMap的元素遍历的顺序问题
Java中关于HashMap的元素遍历的顺序问题 今天在使用如下的方式遍历HashMap里面的元素时 1 for (Entry<String, String> entry : hashMa ...
随机推荐
- HDU - 2294: Pendant(矩阵优化DP&前缀和)
On Saint Valentine's Day, Alex imagined to present a special pendant to his girl friend made by K ki ...
- unity 联机调试(android ios)
http://blog.csdn.net/OnafioO/article/details/44903491 (这种没用,只是在手机看到画面而已) 手机安装unityRemote并运行,unity中设置 ...
- GWT嵌入纯HTML页面
众所周知,gwt页面是java代码所写,不存在html页面直接作用于gwt面板中.不过gwt也倒是提供了一些可用的功能,比如frame,这个是UI中的一个,内部可以设置URL,但是经过我测试后发现,这 ...
- 获取wifi热点
https://stackoverflow.com/questions/31555640/how-to-get-wifi-ssid-in-ios9-after-captivenetwork-is-de ...
- java代码字符字节流
总结: package com.aini; import java.io.IOException; import java.io.InputStreamReader; //流类 import java ...
- java代码异常篇
总结:掌握流.缓冲区类的方法 package com.b; import java.io.BufferedReader; import java.io.File; import java.io.Fil ...
- Java-API:java.lang百科
ylbtech-Java-API:java.lang百科 java.lang是提供利用 Java 编程语言进行程序设计的基础类.最重要的类是Object(它是类层次结构的根)和 Class(它的实例表 ...
- 版本管理 word 文档比较
1.因为公司还在用SVN, 2.而且 还在用word 写文档, 3.而且 commit log 基本不写, 所以导致,想了解word文档 改动, 很浪费时间!!!! 所以想 快速了解word 改动, ...
- MySessionFactory
package com.ORM; import org.hibernate.HibernateException; import org.hibernate.Session; import org.h ...
- Sandbox简介和路径获取
一.简介 iOS的沙盒机制,每个应用只能访问自己应用目录下的文件.iOS应用产生的内容,如文件.缓存内容等都必须存储在自己的沙盒内.默认情况下,每个沙盒含有3个文件夹:Documents, Libra ...