Hadoop环境搭建 (伪分布式搭建)
一,Hadoop版本下载
建议下载:Hadoop2.5.0 (虽然是老版本,但是在企业级别中运用非常稳定,新版本虽然添加了些小功能但是版本稳定性有带与考核)
1.下载地址:
hadoop.apache.org官网下载。如果官网找不到就到下面链接中下载。
http://archive.apache.org/dist/hadoop/common/
二,Hadoop 的三种模式
1. 本地模式 : 1台机器,不使用HDFS文件系统
2. 伪分布式模式 :1台机器。一般用户管理员测试使用
3. 分布式模式 :多台机器。真实的生产环境中使用
三,Hadoop 伪分布式模式搭建准备工作 (完全分布式通用)
1. Centos 6.4版本(最好时6系列。7系列变动有点大,个人还为尝试配置) 下载方法:官网下载破解,或者百度上找百度云盘下载。
2. VMwareWorkStation 上部署 Centos6.4虚拟机 。 设置基础环境三要素: [1]IP(静态地质,NAT网络),[2]主机名,[3]映射>(包括本地)
3. 网络设置: 设置DNS域名解析,Ping通外网
4. 创建一个普通用户: useradd 用户名 命令创建。 passwd 用户名
5. 设置sudo权限 vi sudo
6. 设置远程连接工具: secureCRT,FileZilla,Notepad++
7. 禁用安全系统和防火墙:selinux,iptables,chkconfig iptables
8. 卸载系统自带的Open JDK并配置Oracle JDK: rpm -qa,-e,vi /etc/profile
9 . 创建Hadoop目录 ( /opt目录下创建 )
sudo mkdir software //存放相关软件
sudo mkdir modules //存放相关控键
sudo mkdir datas //存放相关数据
sudo mkdir tools //存放相关工具
10. 上述目录创建完毕之后,ls -l 看一下用户跟组。然后chown -R 普通用户名:普通用户名 * /opt下创建的4个目录的用户及用户组变成普通用户。 例如: sudo chown -R xiaoyueyue:xiaoyueyue *
11. 通过远程工具上传下面hadoop及javaJDK安装包并解压。 (远程工具:FileZilla,Notepad++,rz都可以)
hadoop-2.5.0.tar.gz
jdk-7u67-linux-x64.tar.gz
解压: (tar -zxvf hadoop-2.5.0.tar.gz -C /opt/modules tar -zxvf jdk-7u67-linux-x64.tar.gz -C /opt/modules )
四,Hadoop 伪分布式模式搭建
1. hosts文件配置
sudo vi /etc/profile
添加主机的ip地址及主机名
#Hadoop
192.168.XXX.XXX xiaoyueyue.localhost.com
2. 环境变量的配置(JAVAJDK)
sudo vi /etc/profile 最下方添加下列路径配置环境变量。注意一定要添加自己javaJDK所在的路径
#JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
配置/opt/modules/hadoop-2.5.0/etc/hadoop/hadoop-env.sh 文件指定JAVA_HOME路径
# The java implementation to use.
export JAVA_HOME=/opt/modules/jdk1.8.0_144
配置/opt/modules/hadoop-2.5.0/etc/hadoop/mapred-env.sh 文件指定JAVA_HOME路径
export JAVA_HOME=/opt/modules/jdk1.8.0_144
配置/opt/modules/hadoop-2.5.0/etc/hadoop/yarn-env.sh 文件指定JAVA_HOME路径
#some Java parameters
export JAVA_HOME=/opt/modules/jdk1.7.0_67
3. Hadoop配置文件的配置
(1) 登陆Hadoop官网
hadoop.apache.org --> Documentation -> Release 2.5.2 (按照自己的需求选择版本) --> Single Node Setup (伪分布式配置点击这里) --> 找到Configuration 查看内容
<1> 编辑core-site.xml文件添加下列属性
【默认】
etc/hadoop/core-site.xml:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value> //9000是老的端口现在不用了
</property>
***【自定义】***
<property>
<name>fs.defaultFS</name>
<value>hdfs://xiaoyueyue.localhost.com:8020</value> //value处添加自己的hostname并添加8020端口。指定HDFS文件系统在那台机器。如果是分布式的话,可以指定其中1台机器为HDFS文件系统。其他机器不需要配置这个属性
</property>
<2> 配置临时目录 (默认:Hadoop运行时会生成临时目录默认放在了/tmp下。要是不改变地址那么机器重启后这些数据会丢失。因此最好建议配置另外一个目录)
hadoop.tmp.dir /tmp/hadoop-${user.name}
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value> //我在/opt/modules/hadoop-2.5.0/下mkdir 创建了/data/tmp然后配置临时目录保存在这里
</property>
<3> 编辑hdfs.xml文件添加下列属性
etc/hadoop/hdfs-site.xml:
【默认】
<property>
<name>dfs.replication</name> //配置hdfs副本数。默认为3。但是目前配置的是伪分布式架构,只有一台机器因此这里的value值是1.如果是3台机器可以不配这个属性。但是如果超过3台就需要指定它的副本数。
<value>1</value>
</property>
<4> 编辑slaves配置文件(指定datanode同时也代表nodemanager。这个文件就代表从节点的意思)
xiaoyueyue.localhost.com //因为只有一台机器所以配置文件只添加了自身的hostname。如果是多台机器需要把所有机器的hostname都添加进来。
<5> 格式化namenode (对于元数据进行初始化,否则无法读取元数据)
cd /opt/modules/Hadoop-2.5.0
$ bin/hdfs // 列出所有hdfs命令
$ bin/hdfs namenode -format //bin/hdfs 查看所有命令namenode -format为格式化namenode
<7> 启动namenod及datanode服务
cd /opt/modules/Hadoop-2.5.0
$ sbin/hadoop-daemon.sh start namenode //sbin/脚本名 start or stop 启动停止命令 启动的服务名称
$ sbin/hadoop-daemon.sh start datanode
$ jps //查看java进程状态
$ hostname得到系统名 //打开web网页输入系统名后面跟50070端口号进行交互。 例如:xiaoyueyue.localhost.com:50070
<8> 通过web界面查看一下是否能够登陆
登陆方式: hostname + 端口号 (我自身的为:tonyliu.localhost.com:50070)
图1:点击Utilities --》 Browse the system
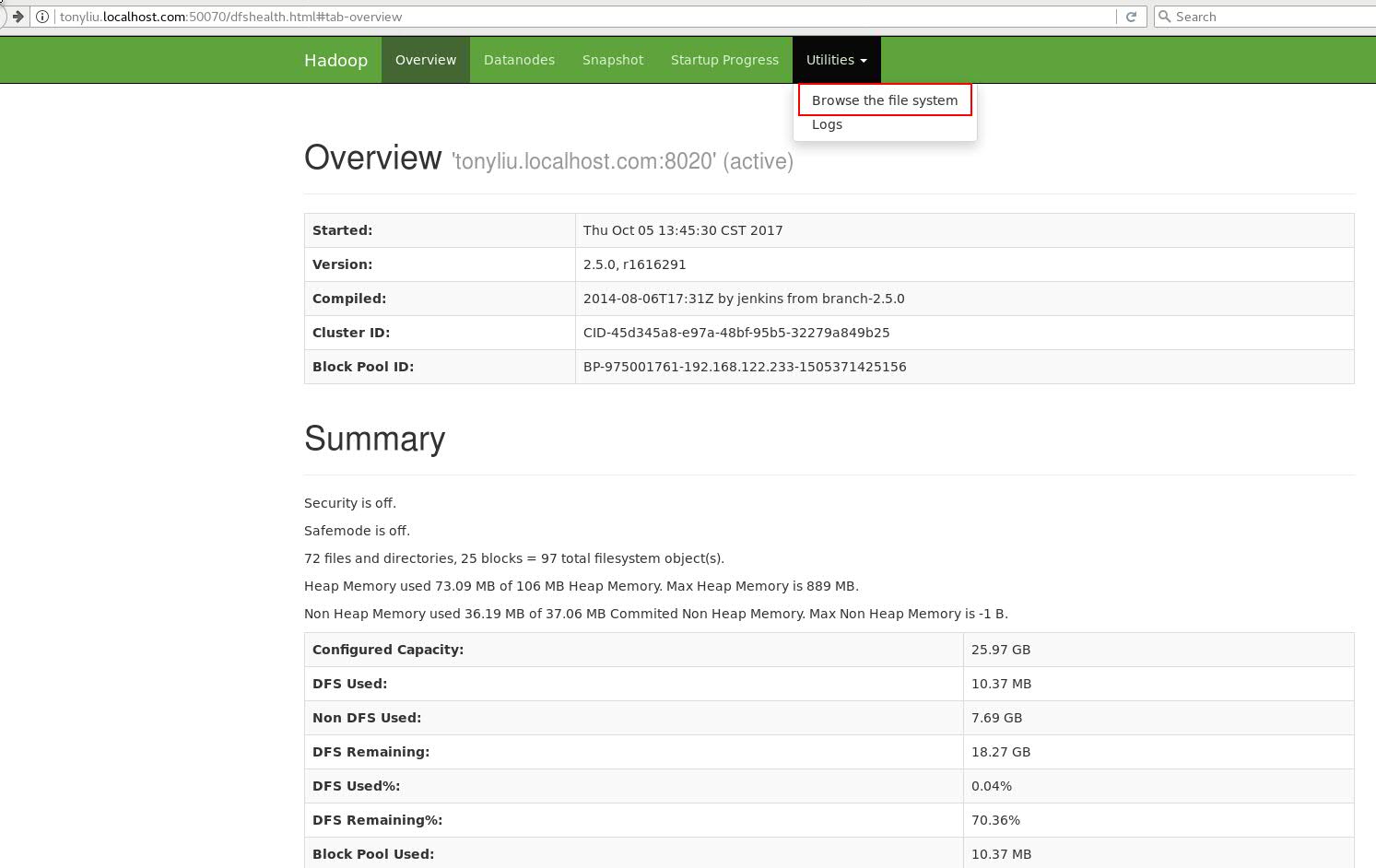
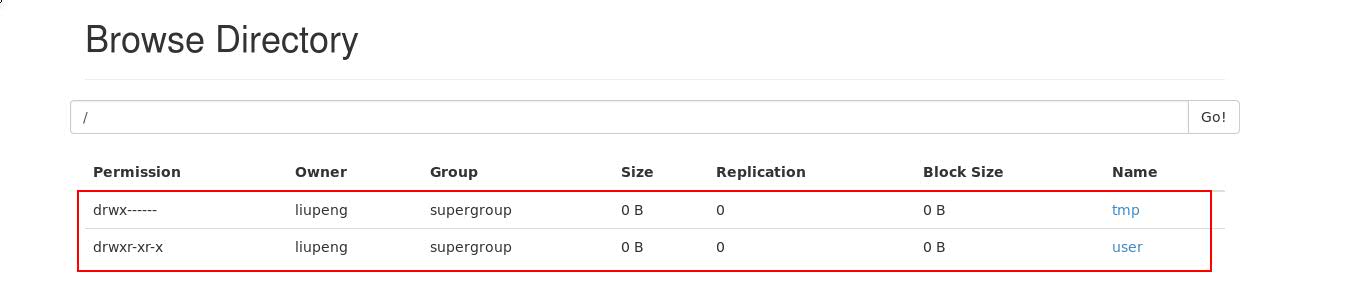
图2:下图为我已经创建好的目录,第一次登陆进来的话只有根目录其他什么都没有。
<9> HDFS 下常用命令
下面为HDFS中dfs 所有命令。我们列举几个平时最常用的命令,其他命令在日常用到或者需要了解的情况下再看。不懂问度娘。
(1) -mkdir 创建文件夹 例子:bin/hdfs dfs -mkdir -p 目录
(2) -put 上传文件 例子:bin/hdfs dfs -put /要上传的文件路径 /要传到HDFS上的哪个具体路径(建议创建input目录,对应生成output目录便于管理 /user/liupeng/wordcount/input)
(3) -get 下载文件 例子:bin/hdfs dfs -get /要下载的HDFS上的文件路径 /下载到的目标地址
(4)-text 查看文件内容 例子:bin/hdfs dfs -text /要查看的文件地址及文件名
(5) 其他:基本根Linux下的命令行用法相同。命令前面别忘加 - 再接命令。
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
hdfs 命令
<10> Yarn上运行wordcount程序
刚才我们将本地的wordcount文件上传到了HDFS文件系统上了,但是在Hadoop中应用都是跑在Yarn上。而Yarn上是通过web来获取文件的。而文件要想跑在Yarn上都需要提前打jar包。
我们的wordcount程序在安装Hadoop时本地就有一个默认的jar包(share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar),我们可以直接引用来用。如果其他的应用例如编码后的jar包需要先打成jar包之后再进行应用的执行。
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/liupeng/wordcount/input /user/liupeng/wordcount/output
注意:wordcount运行完后如果还想再运行一遍的话,必须更改output名称。例如 output1不允许重名,不然会报错。
另外output目录不能提前创建。是自动生成的。如果提前创建output目录,那么程序运行时会失败。
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/liupeng/wordcount/input /user/liupeng/wordcount/output1
(2) Yarn的配置(伪分布式)
<1> 编辑mapred-site.xml配置文件 (添加下列属性)
etc/hadoop/mapred-site.xml:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name> //配置历史服务器
<value>xiaoyueyue.localhost.com:10020</value> //指定历史服务器的hostname以及端口(10020)
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name> //配置历史服务器web页面属性
<value>xiaoyueyue.localhost.com:19888</value> //指定历史服务器的hostname以及web访问的端口(19888)
</property>
<2> 编辑yarn配置文件
etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> //Yarn上可以跑很多不同类型的框架。这里是代表指定mapreduce框架
</property> <property>
<name>yarn.resourcemanager.hostname</name> //指定那一台机器为resourceManager主节点
<value>tonyliu.localhost.com</value>
</property>
<3> Yarn服务的启动
sbin/yarn-daemon.sh start resourcemanager //resourceManager服务的启动
sbin/yarn-daemon.sh start nodemanager //nodeManager服务的启动
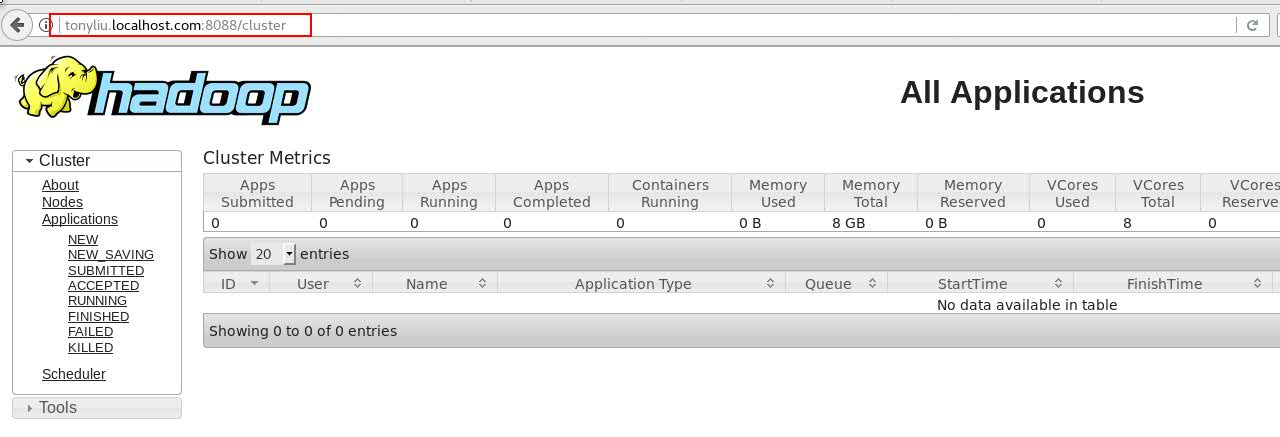
<4> 通过web界面访问Yarn
登陆方式: hostname + 8088端口
<5>重新运行wordcount程序(运行在yarn上)
使MapReduce程序运行在Yarn上处理的是HDFS文件系统上的数据而不是本地的数据
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/liupeng/wordcount/input /user/liupeng/wordcount/output2
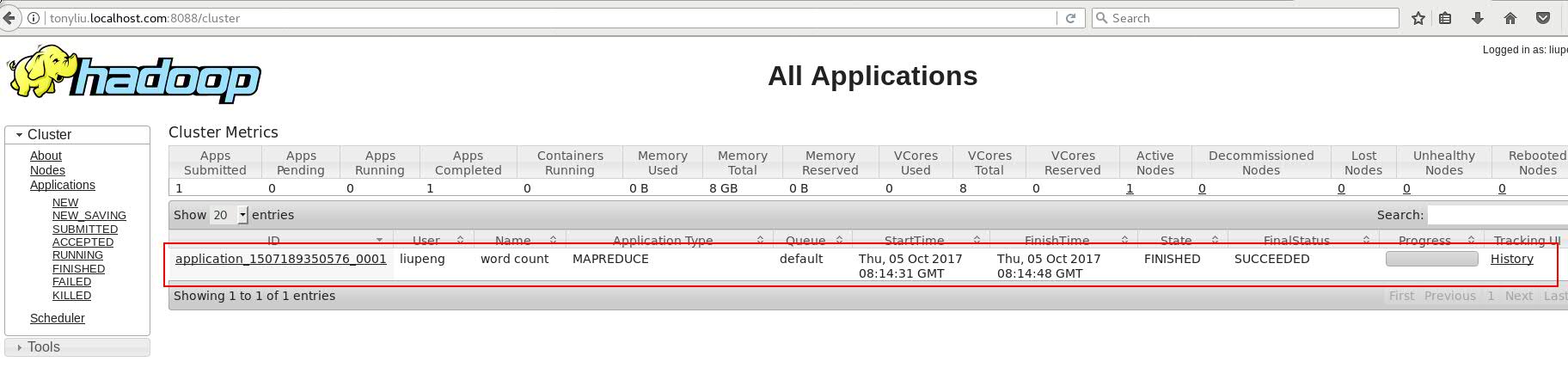
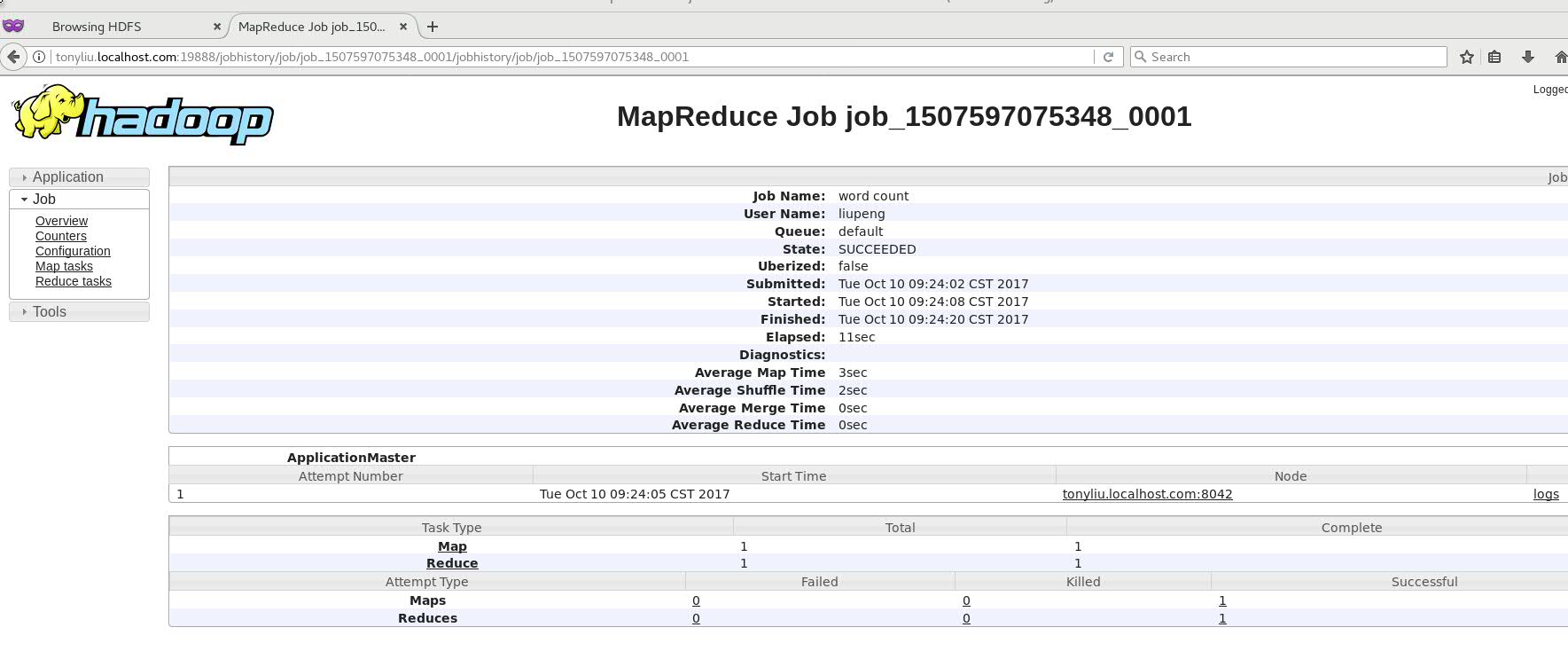
到Yarn 的 web页面上查看MapReduce任务。如果出现下图。状态并且为SUCCEEDED 说明任务运行成功。
<6> 配置历史服务器
上图中我们可以看到有一个History 选项,当我们点击进去的时候会发现报错。那是因为我们没有配置History服务器属性。下面是历史服务器的配置信息
(1) 历史服务器服务的启动
当我们 ls sbin目录查看时会发现有一个 mr-jobhistory-daemon.sh 的脚本。这个脚本就是用来启动historyserver服务的。
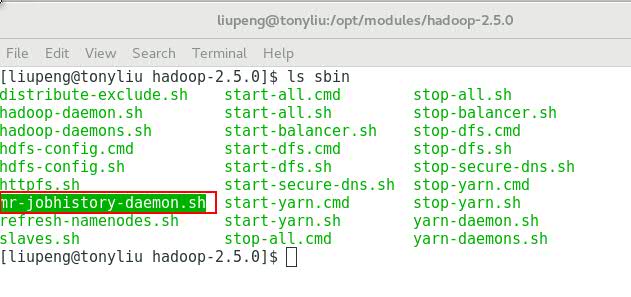
(2) 启动我们的历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
(3) 查看历史服务器进程是否启动
如果出现下面标注的JobHistoryServer这个服务进程就说明我们的历史服务器进程启动成功了。
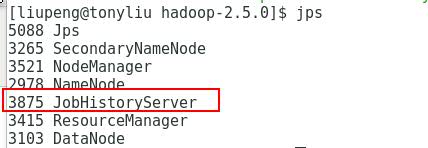
(4) 检查web页面历史服务器的启动状态
刷新页面会发现历史记录出现代表服务启动正常。
<7> Yarn的日志聚集功能配置
(1)查看Map,Reduces任务
通过历史服务器的配置,我们可以清楚的看到跑在Yarn上的mapReduce任务。如下图中案例显示1个map任务及1个reduces任务。
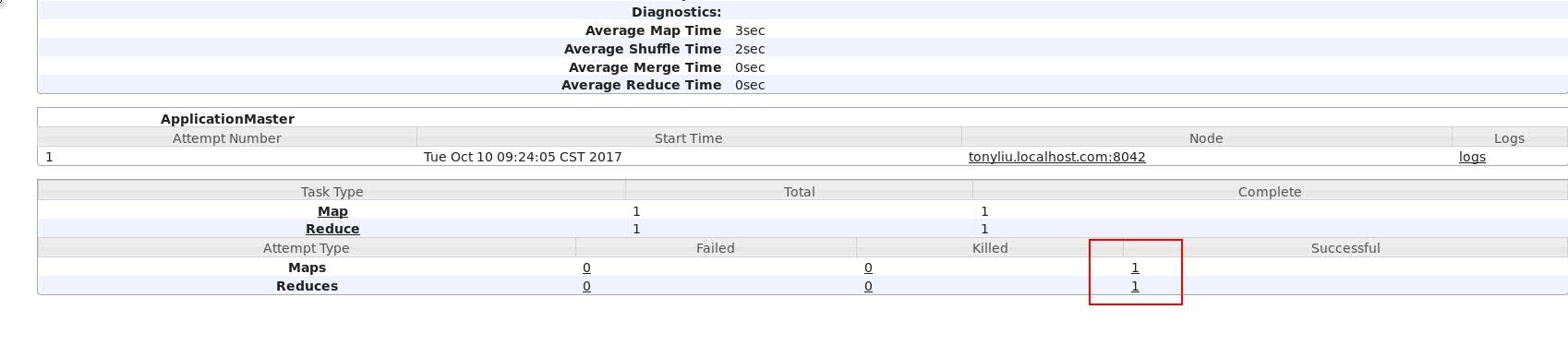 (2) 具体查看Map,Reduces任务信息
(2) 具体查看Map,Reduces任务信息
我们还可以通过鼠标具体点入Maps,Reduces个数中具体查看每个Maps及Reduces的状态信息。其实下图中的Attempt就相当于我们的容器,来分配管理了我们的Map任务。当中还有一个logs选项。
 (3)查看logs日志信息
(3)查看logs日志信息
当我们点入logs选项后,会发现出现报错信息。Aggregation 代表聚集的意思。说Aggregation is not enabled说明我们的聚集功能没有配置所产生的报错。那么下面来一起配置一下聚集功能。
(所谓的聚集就是代表把生成的日志信息,上传到我们的HDFS系统上。这就叫做聚集)
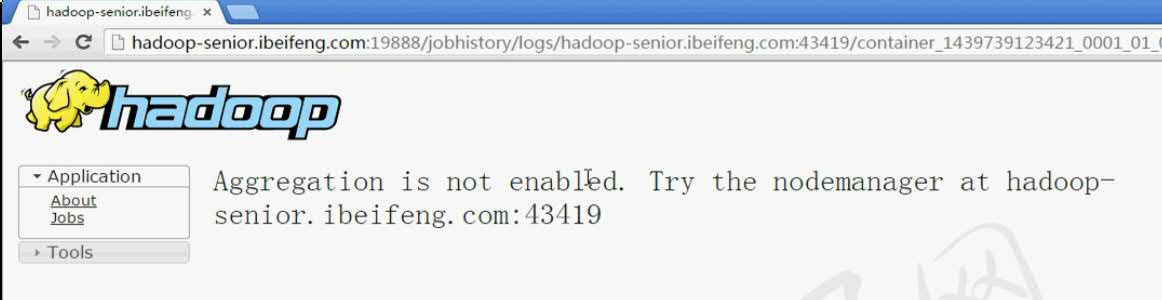
(4) Aggregation聚集功能的配置
在/opt/modules/hadoop-2.5.0/etc/hadoop目录下找到我们的 yarn-site.xml 配置信息。然后添加下面属性
<property>
<name>yarn.log-aggregation-enable</name> //配置aggregation聚集功能的启用
<value>true</value> //默认为-1代表没有启用,我们把value变成true代表启用该功能
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name> //这条配置代表日志信息在我们的Yarn上所保存的时间
<value>259200</value> //是按照秒为单位计算的。我们把需要保存的天数换算成秒然后计入即可
</property>
(5)Aggregation聚集功能生效
要想配置完聚集功能生效必须重启一下我们的服务。
$sbin/yarn-daemon.sh stop resourcemanager $sbin/yarn-daemon.sh stop nodemanager $sbin/mr-jobhistory-daemon.sh stop historyserver jps查看如果停掉代表成功再重新启动服务 $sbin/yarn-daemon.sh start resourcemanager $sbin/yarn-daemon.sh start nodemanager $sbin/mr-jobhistory-daemon.sh start historyserver
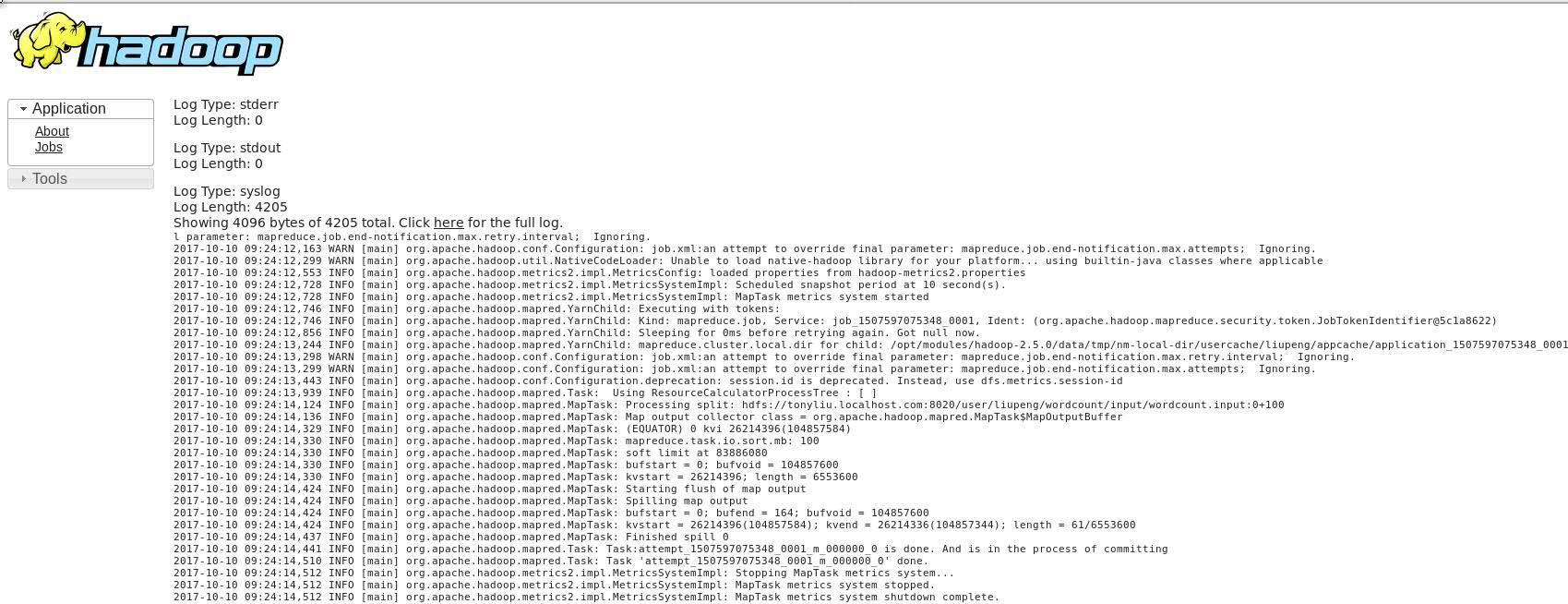
(6) Web页面查看history logs信息
点击logs选项出现下列信息后代表我们的聚集功能完全配置成功了。
Hadoop环境搭建 (伪分布式搭建)的更多相关文章
- Hadoop简介与伪分布式搭建—DAY01
一. Hadoop的一些相关概念及思想 1.hadoop的核心组成: (1)hdfs分布式文件系统 (2)mapreduce 分布式批处理运算框架 (3)yarn 分布式资源调度系统 2.hadoo ...
- Hadoop学习2—伪分布式环境搭建
一.准备虚拟环境 1. 虚拟环境网络设置 A.安装VMware软件并安装linux环境,本人安装的是CentOS B.安装好虚拟机后,打开网络和共享中心 -> 更改适配器设置 -> 右键V ...
- Hadoop的伪分布式搭建
我们在搭建伪分布式Hadoop环境,需要将一系列的配置文件配置好. 一.配置文件 1. 配置文件hadoop-env.sh export JAVA_HOME=/opt/modules/jdk1.7.0 ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- Hadoop单机模式和伪分布式搭建教程CentOS
1. 安装JAVA环境 2. Hadoop下载地址: http://archive.apache.org/dist/hadoop/core/ tar -zxvf hadoop-2.6.0.tar.gz ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
随机推荐
- base标签
我们扒取到网站源码很多时候发现路径是采用相对路径,这时候我们就需要采用base标签了,用法非常简单, <base href="我们扒取网站的域名"/> 这时相对路径就相 ...
- 《java提高数据导入效率优化思路》
写在前边的实现需求: 1.总共10万个电话号码: 2.电话号码中有重复和错误: 3.查找出正确的号码(不重复): 一.优化前的实现方式: 1.先用正则过滤一遍10万条数据,找出错误的: 2.用List ...
- 【起航计划 013】2015 起航计划 Android APIDemo的魔鬼步伐 12 App->Activity->SetWallpaper 设置壁纸 WallpaperManager getDrawingCache使用
SetWallpaper介绍如何在Android获取当前Wallpaper,对Wallpaper做些修改,然后用修改后的图像重新设置Wallpaper.(即设置>显示>壁纸>壁纸的功 ...
- 《孵化Twitter》:Twitter创始人勾心斗角史,细节披露程度令人吃惊
本书详细讲述twitter的发展史.感觉基本上是一部创始人从朋友变敌人,勾心斗角的历史.Twitter本身的产品发展反而相对比较简单. 书中披露了许多email.谈话.会议的细节,作者说这些是数百个小 ...
- 使用Atom编写Makedown
Atom 是 Github 专门为程序员推出的一个跨平台文本编辑器. Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式. 作为一个Gi ...
- hdu-2844&&POJ-1742 Coins---多重背包
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=2844 题目大意: Tony想要买一个东西,他只有n中硬币每种硬币的面值为a[i]每种硬币的数量为c[ ...
- Android(java)学习笔记62:android.intent.action.MAIN 与 android.intent.category.LAUNCHER 理解
1. 先看看网路上的说法: android.intent.action.MAIN 决定应用程序最先启动的 Activity android.intent.category.LAUNCHER 决定应用程 ...
- http协议,tcp协议,ip协议,dns服务之前的关系和区别
长期以来都有一个问题,大家都在说http协议,tcp协议,ip协议,他们之间到底什么区别,有什么用,没人告诉我,最近看了这本<图解http>明白了一些,以下图片摘自这本书 一.理解一个传输 ...
- setTimeout详解
一.setTimeout基础 setTimeout(func|code,delay); 第一个参数表示将要推迟的函数名或者一段代码,第二个参数表示推迟执行的毫秒数 eg: console.log( ...
- css术语和概念
.vocabulary{ height:99px; color:transparent; } 属性 上面示意css代码中的height和color就是属性. 值 上面的99px就是值 整数值: ...