Python菜鸟之路:Python操作MySQL-即pymysql/SQLAlchemy用法
上节介绍了Python对于RabbitMQ的一些操作,本节介绍Python对于MySQL的一些操作用法
模块1:pymysql(等同于MySQLdb)
说明:pymysql与MySQLdb模块的使用基本相同,学会pymysql,使用MySQLdb也就不是问题
安装API模块
pip install pymysql
执行
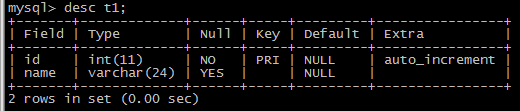 -->数据库test中表t1的结构
-->数据库test中表t1的结构
import pymysql
# 创建连接
conn = pymysql.connect(host='172.25.50.13', port=3306, user='root', passwd='123456', db='test')
# 开启自动提交SQL,如果这里不设置,以后的命令需要执行conn.commit()来提交执行,否则都在内存中
conn.autocommit(True) # 创建游标
cur = conn.cursor() # 执行普通SQL,并返回受影响行数
effect_row = cur.execute("insert into t1 values (1, 'Boss')")
print(effect_row) # out:1
#
# 执行带占位符的SQL,并返回受影响行数
effect_row = cur.execute("insert into t1 values (2,'%s')" % "xiaodi")
print(effect_row) # out:1
#
# 执行多行数据的SQL,并返回受影响行数
effect_row = cur.executemany("insert into t1(id,name) values (%s, %s)" , [(3,'zhubajie'),(4,'sunwukong')])
print(effect_row) # out: 2 # 获取最新自增ID,注意:如果该表的列是非自增类型的,则获取到的数值为0
id = cur.lastrowid
print(id) # out :4
cur.execute('select * from t1') # 获取第一行数据
row_1 = cur.fetchone()
print(row_1) # out: (1, 'Boss')
# 获取前n行数据
row_2 = cur.fetchmany(3)
print(row_2) # out: ((2, 'xiaodi'), (3, 'zhubajie'), (4, 'sunwukong'))
# 获取所有数据
row_3 = cur.fetchall()
print(row_3) # out: ((1, 'Boss'), (2, 'xiaodi'), (3, 'zhubajie'), (4, 'sunwukong'))
# 提交
conn.commit() # 关闭游标
cur.close()
# 关闭连接
conn.close()
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
cur.scroll(1,mode='relative') # 相对当前位置移动,数字1 也可以为负数,只是移动方向不同而已
cur.scroll(2,mode='absolute') # 相对绝对位置移动
扩展:通过pymysql获取Dict数据类型
从上边的案例可以看出,pymysql获取的结果,是以元组的形式输出,对于不了解表结构的人来说,无疑不知道每个元素对应的列。
因此,如果想要或者字典类型的数据,需要创建游标的时候,设置返回的数据集类型,即:
# 游标设置为字典类型
cur = conn.cursor(cursor=pymysql.cursors.DictCursor)
模块2:Python MySQL ORM框架--> SQLAlchemy
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。

说明:
SQLAchemy 本身无法操作数据库,其本质上是依赖pymysql.MySQLdb,mssql等第三方插件。
Dialect用于和数据库API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作。
配置SQLAlchemy,使用不同API
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
普通使用
使用 Engine/ConnectionPooling/Dialect 进行数据库操作:Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
from sqlalchemy import create_engine # 等效于创建游标
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) # 执行SQL
cur = engine.execute(
"INSERT INTO hosts (host, color_id) VALUES ('1.1.1.22', 3)"
) # 其余操作同游标操作一样,就不一一列举。
ORM功能使用
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
创建表和删除表
# sqlalchemy 创建表和删除表、 from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine # 创建连接
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test", max_overflow=5) # 创建基类。这个是固定写法,创建表必须这么写
Base = declarative_base() # 创建单表
class Users(Base):
# 创建表
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(32))
extra = Column(String(16))
# 创建联合索引
__table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'),
Index('ix_id_name', 'name', 'extra'),
) # 一对多
class Favor(Base):
__tablename__ = 'favor'
nid = Column(Integer, primary_key=True)
caption = Column(String(50), default='red', unique=True) class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
favor_id = Column(Integer, ForeignKey("favor.nid")) # 多对多
class ServerToGroup(Base):
__tablename__ = 'servertogroup'
nid = Column(Integer, primary_key=True, autoincrement=True)
server_id = Column(Integer, ForeignKey('server.id'))
group_id = Column(Integer, ForeignKey('group.id')) class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False) class Server(Base):
__tablename__ = 'server' id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False)
port = Column(Integer, default=22) def init_db():
Base.metadata.create_all(engine) def drop_db():
Base.metadata.drop_all(engine)
操作表
要想操作表,需要经过如下2个步骤
步骤1:创建session
Session = sessionmaker(bind=engine)
session = Session()
步骤2:执行SQL。这里需要注意,如果是新增的话,需要新建对象,如下
# 新增单条数据
obj = Users(name="guanyu", extra='hanjiang')
session.add(obj)
# 新增多条数据
session.add_all([
Users(name="liubei", extra='leader'),
Users(name="zhangfei", extra='xiaodi'),
])
session.commit()
其他的SQL,仅需要执行session.query方法,进行相关操作即可
1)删除表数据
# 删除user表中id大于2的条目
session.query(Users).filter(Users.id > 2).delete()
session.commit()
2)修改表数据
# 更新user表中id大于2的name列为099
session.query(Users).filter(Users.id > 2).update({"name" : "099"})
# 更新user表中id大于2的name列,在原字符串后边增加099
session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + "099"}, synchronize_session=False)
# 更新user表中id大于2的num列,使最终值在原来数值基础上加1
session.query(Users).filter(Users.id > 2).update({"num": Users.num + 1}, synchronize_session="evaluate") # 数字相加,必须设置synchronize_session="evaluate"
session.commit()
3)查询数据
ret = session.query(Users).all() # 查询所有
sql = session.query(Users) # 查询生成的sql
print(sql)
ret = session.query(Users.name, Users.extra).all() #查询User表的name和extra列的所有数据
ret = session.query(Users).filter_by(name='alex').all() # 取全部name列为alex的数据
ret = session.query(Users).filter_by(name='alex').first() # 第一个匹配name列为alex的数据 Ps: ret是一个对象列表。这个对象可以通过 “对象[索引].字段”来获取对应的值
4)其他
# 条件
ret = session.query(Users).filter_by(name='alex').all() #
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all() # 且的关系
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() # ~表示非。就是not in的意思
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all() # 联表查询
from sqlalchemy import and_, or_ # 且和or的关系
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all() # 条件以and方式排列
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all() # 条件以or方式排列
ret = session.query(Users).filter(
or_( #这部分表示括号中的条件都以or的形式匹配
Users.id < 2, # 或者 or User.id < 2
and_(Users.name == 'eric', Users.id > 3),# 表示括号中这部分进行and匹配
Users.extra != ""
)).all() # 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all() # 表示not like # 限制 limit用法
ret = session.query(Users)[1:2] # 等于limit ,具体功能需要自己测试 # 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 按照name从大到小排列,如果name相同,按照id从小到大排列 # 分组
from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all() ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() # having对聚合的内容再次进行过滤 # 连表 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() ret = session.query(Person).join(Favor).all()
# 默认是inner join
ret = session.query(Person).join(Favor, isouter=True).all() # isouter表示是left join # 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all() #union默认会去重 q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all() # union_all不去重
至此,SQLAlechemy模块的基本使用介绍完毕
Python菜鸟之路:Python操作MySQL-即pymysql/SQLAlchemy用法的更多相关文章
- Python操作MySQL -即pymysql/SQLAlchemy用法
本节介绍Python对于MySQL的一些操作用法 模块1:pymysql(等同于MySQLdb) 说明:pymysql与MySQLdb模块的使用基本相同,学会pymysql,使用MySQLdb也就不是 ...
- python操作mysql(pymysql + sqlalchemy)
pymysql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同. 下载安装 pip3 install pymysql 使用操作 1.执行sql #!/usr/bi ...
- Python中操作mysql的pymysql模块详解
Python中操作mysql的pymysql模块详解 前言 pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持 ...
- Python菜鸟之路:Django 路由补充1:FBV和CBV - 补充2:url默认参数
一.FBV和CBV 在Python菜鸟之路:Django 路由.模板.Model(ORM)一节中,已经介绍了几种路由的写法及对应关系,那种写法可以称之为FBV: function base view ...
- Python3操作MySQL基于PyMySQL封装的类
Python3操作MySQL基于PyMySQL封装的类 在未使用操作数据库的框架开发项目的时候,我们需要自己处理数据库连接问题,今天在做一个Python的演示项目,写一个操作MySQL数据库的类, ...
- python成长之路【第十三篇】:Python操作MySQL之pymysql
对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎 ...
- python操作mysql之pymysql
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同.但目前pymysql支持python3.x而后者不支持3.x版本. 本文测试python版本:2.7.11.mys ...
- Python自动化运维之18、Python操作 MySQL、pymysql、SQLAchemy
一.MySQL 1.概述 什么是数据库 ? 答:数据的仓库,和Excel表中的行和列是差不多的,只是有各种约束和不同数据类型的表格 什么是 MySQL.Oracle.SQLite.Access.MS ...
- (转)Python中操作mysql的pymysql模块详解
原文:https://www.cnblogs.com/wt11/p/6141225.html https://shockerli.net/post/python3-pymysql/----Python ...
随机推荐
- 9. 使用JdbcTemplate【从零开始学Spring Boot】
转载:http://blog.csdn.net/linxingliang/article/details/51636998 整体步骤: (1) 在pom.xml加入jdbcTemplate的依赖: ...
- 使用C++11的function/bind组件封装Thread以及回调函数的使用
之前在http://www.cnblogs.com/inevermore/p/4008572.html中采用面向对象的方式,封装了Posix的线程,那里采用的是虚函数+继承的方式,用户通过重写Thre ...
- 斯坦福《机器学习》Lesson4感想--1、Logistic回归中的牛顿方法
在上一篇中提到的Logistic回归是利用最大似然概率的思想和梯度上升算法确定θ,从而确定f(θ).本篇将介绍还有一种求解最大似然概率ℓ(θ)的方法,即牛顿迭代法. 在牛顿迭代法中.如果一个函数是,求 ...
- 【Excle数据透视表】如何新建数据透视表样式
如果觉得Excle给出的数据透视表样式不符合自己的心意,可以自己定义一个数据透视表样式 步骤1 单击数据透视表区域任意单元格→数据透视表工具→设计→样式组中的下拉按钮,打开数据透视表样式库→新建数据透 ...
- 【Excle数据透视表】如何重复显示行字段的项目标签
前提:该数据透视表以表格形式显示 解决办法: 通过报表布局设置"重复所有项目标签" 修改前样式 步骤 单击数据透视表中任意单元格→设计→报表布局→重复所有项目标签 修改后样式
- 【VBA】切换引用样式
在Excle中有两种引用方式,例如:第一行第一列的单元格可以是:A1 也可以是R1C1 切换引用样式的代码如下: Sub 切换引用样式() Application.ReferenceStyle = ...
- Nginx 限制单个IP的并发连接数及对每个连接速度(限速)
使用Nginx限制单个IP的并发连接数能够减少一些采集程序或者DDOS的攻击. 再lnmp的nginx配置中已经添加了部分代码,但是是注释掉的,可以编辑/usr/local/nginx/conf/ng ...
- C#中后台线程和UI线程的交互
在C#中,从Main()方法开始一个默认的线程,一般称之为主线程,如果在这个进行一些非常耗CPU的计算,那么UI界面就会被挂起而处于假死状态,也就是说无法和用户进行交互了,特别是要用类似进度条来实时显 ...
- 【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
[转].NET(C#):浅谈程序集清单资源和RESX资源 目录 程序集清单资源 RESX资源文件 使用ResourceReader和ResourceSet解析二进制资源文件 使用ResourceM ...
- unity开发android游戏(一)搭建Unity安卓开发环境
unity开发android游戏(一)搭建Unity安卓开发环境 分类: Unity2014-03-23 16:14 5626人阅读 评论(2) 收藏 举报 unity开发androidunity安卓 ...