Spark SQL 读到的记录数与 hive 读到的不一致
问题:我用 sqoop 把 Mysql 中的数据导入到 hive,使用了--delete-target-dir --hive-import --hive-overwrite 等参数,执行了两次。 mysql 中只有 20 条记录。在 hive shell 中,查询导入到的表的记录,得到结果 20 条,是对的。

然而在 spark-shell 中,使用 spark sql 得到的结果却是 40 条。
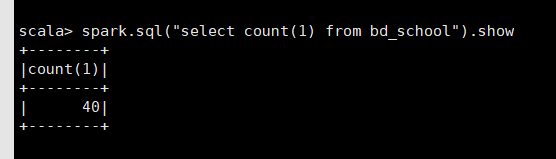
又执行了一次 sqoop 的导入,hive 中仍然查询到 20 条,而 spark shell 中却得到了 60 条!!
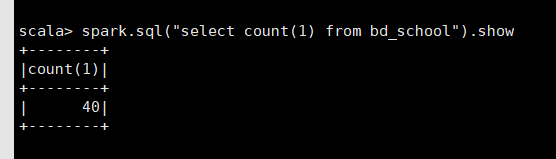
查了一下 HDFS 上,结果发现有 3 个文件
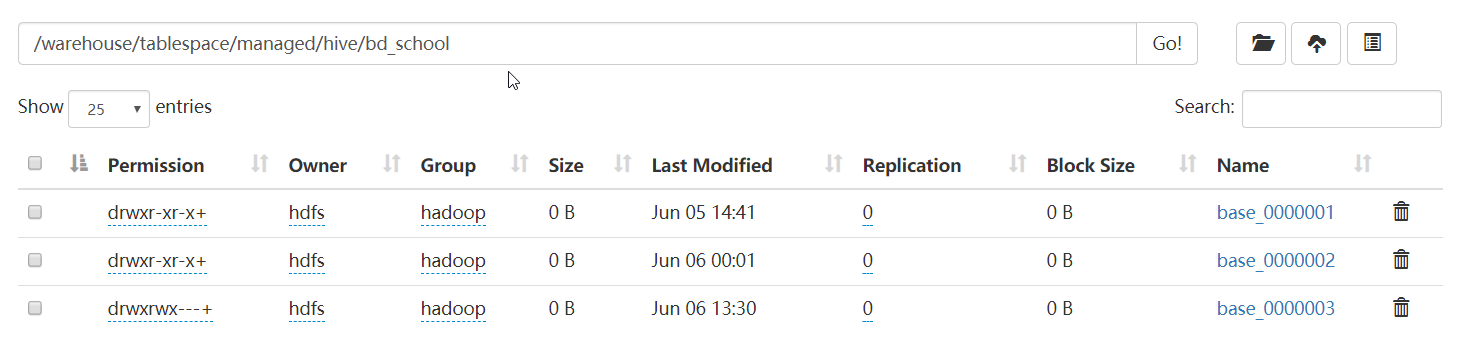
后来在网上看到有说 Hortonworks 中,用 Ambari 部署的 hive(V3.0),默认是开启 ACID 的,Spark 不支持 hive 的 ACID。更改 hive 的如下参数,关闭 ACID 功能。
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false
删除 hive 中的表,重新导入。
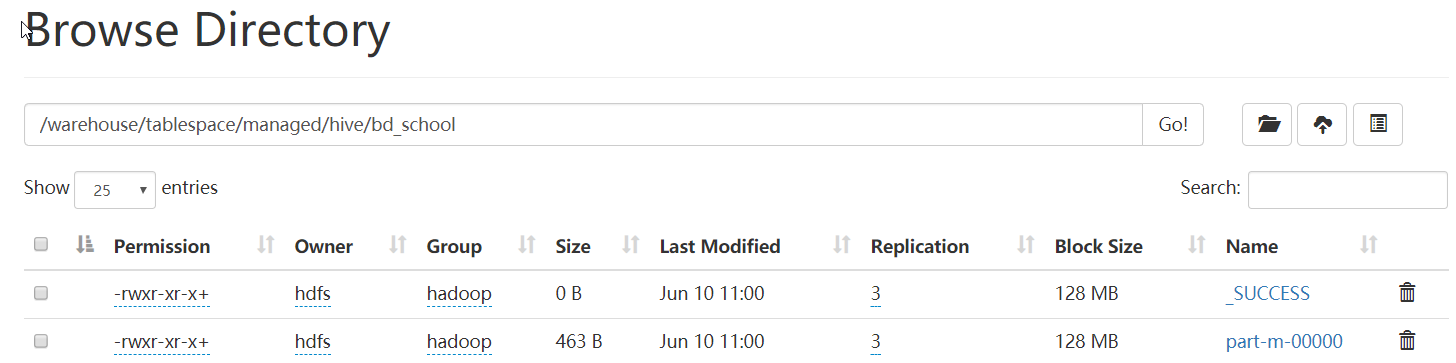
可以看到,表目录下的文件名变了,不是原来的 base_ 开头的了。
用 overwrite 的方式导入多次,也还是只有这两个文件,spark sql 读取的数据也没有出现翻倍的现象。
至此,问题算是解决了。但是不明白为什么 hive 开启 ACID 时,尽管表目录下有多个文件,但是 hive shell 能知道到底哪个是正确的,而 spark 则不知道。估计只有研究源码才能解决问题了。
Spark SQL 读到的记录数与 hive 读到的不一致的更多相关文章
- SQL Server 查询表的记录数(3种方法,推荐第一种)
http://blog.csdn.net/smahorse/article/details/8156483 --SQL Server 查询表的记录数 --one: 使用系统表. SELECT obje ...
- 【转】SQL Server 查询表的记录数(3种方法,推荐第一种)
--SQL Server 查询表的记录数 --one: 使用系统表. SELECT object_name (i.id) TableName, rows as RowCnt FROM sysindex ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
- 查找 SQL SERVER 所有表记录数
-- 所有表的记录数 SELECT a.name, b.rowsFROM sysobjects AS a INNER JOIN sysindexes AS b ON a.id = b.idWHERE ...
- sqlserver sql语句查看分区记录数、查看记录所在分区
select count(1) ,$PARTITION.WorkDatePFN(workdate) from imgfile group by $PARTITION.WorkDatePFN(workd ...
- sql 查看表的记录数
select a.name as 表名,max(b.rows) as 记录条数 from sysobjects a ,sysindexes b where a.id=b.id and a.xtype= ...
- SQL 获取各表记录数的最快方法
select distinct o.name,i.rows from sysobjects o,sysindexes i where o.id=i.id and o.Xtype= 'U' and i ...
- 统计SQL Server所有表记录数
SELECT SCHEMA_NAME(t.schema_id) AS [schema] ,t.name AS tableName ,i.rows AS [rowCount] FROM sys.tabl ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- AMD模块定义规范
AMD 即Asynchronous Module Definition,中文名是“异步模块定义”的意思.它是一个在浏览器端模块化开发的规范,服务器端的规范是CommonJS. 模块将被异步加载,模 ...
- xxx was built without full bitcode" 编译错误解决
xxx was built without full bitcode" 编译错误解决 iOS 打包上线 All object files and libraries for bitcode ...
- OpenCV-Python 霍夫直线检测-HoughLinesP函数参数
cv2.HoughLines()函数是在二值图像中查找直线,cv2.HoughLinesP()函数可以查找直线段. cv2.HoughLinesP()函数原型: HoughLinesP(image, ...
- ACM学习历程—HDU 5072 Coprime(容斥原理)
Description There are n people standing in a line. Each of them has a unique id number. Now the Ragn ...
- 【VS】VS开发中遇到的问题的总结
1. VS中经常会出现无法解析的外部符号,还有LINK ERROR 2019等 这类问题如果检查代码没有错误,很大概率就是lib文件错误.调试程序找出问题函数,再找出问题函数使用到的lib文件,在项 ...
- vue 常见的新增、编辑、查看公用同一个页面
用vue开发经常会碰到,一个功能的新增.编辑.查看公用同一个页面,如果是页面暂且不提. 但是弹框,很多人会发现,如果是点击编辑,取消,再点新增,弹框上面是会有残留数据的,为什么会这样呢,因为在点编辑的 ...
- JavaScript运行机制与setTimeout
前段时间,老板交给了我一个任务:通过setTimeout来延后网站某些复杂资源的请求.正好借此机会,将JavaScript运行机制和setTimeout重新认真思考一遍,并将我对它们的理解整理如下. ...
- SSH不允许Root登陆的方法
不允许Root登陆的方法如下: vim /etc/ssh/sshd_config 把PermitRootLogin yes 改成: PermitRootLogin no 然后重启sshd服务: Ser ...
- Guice 学习
Guice: 是一个轻量级的DI框架. 不需要繁琐的配置,只需要定义一个Module来表述接口和实现类,以及父类和子类之间的关联关系的绑定,如下是一个例子. http://blog.csdn.net/ ...
- mariadb的读写分离
实验环境:CentOS7 设备:一台主数据库服务器,两台从数据库服务器,一台调度器 主从的数据库配置请查阅:http://www.cnblogs.com/wzhuo/p/7171757.html : ...