Spark内核概述
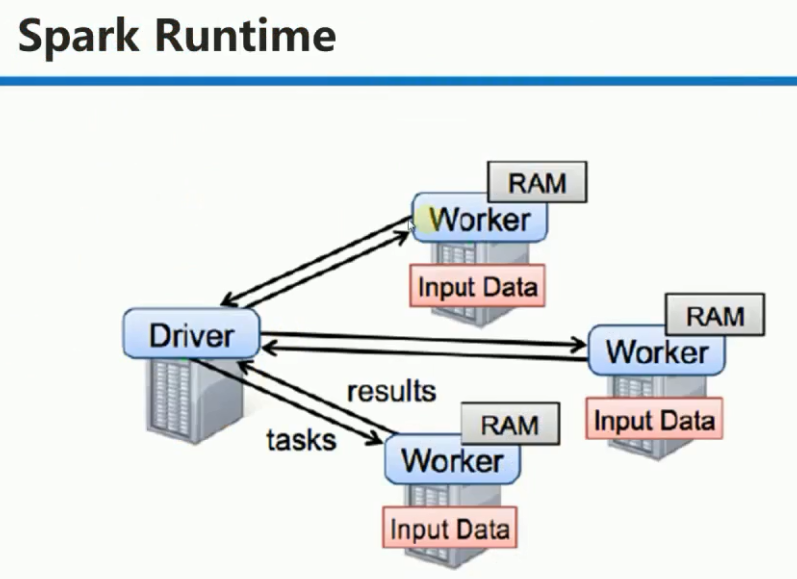

提交Spark程序的机器一般一定和Spark集群在同样的网络环境中(Driver频繁和Executors通信),且其配置和普通的Worker一致
1. Driver: 具有main方法的,初始化 SparkContext 的程序。Driver运行在提交Spark任务的机器上。
Driver 部分的代码: SparkConf + SparkContext
SparkContext: 创建DAGScheduler, TaskScheduler, SchedulerBackend, 在实例化的过程中Register当前程序给Master。 Master接
受注册,如果没有问题,Master会为当前程序分配AppId并分配计算资源
Cluster Manager:获取集群资源的外部服务。Spark应用程序的运行不依赖于Cluster Manager。
Master: 接受用户提交的程序并发送指令给Worker,让其为当前程序分配计算资源,每个Worker所在节点默认为当前程序分配一个
Executor,在Executor中通过线程池并发执行。
可以通过以下三种途径得到要为当前程序分配多少计算资源:
(1). spark-env.sh 和 spark-default.sh 中的配置信息
(2) submit 提供的参数
(3) 程序中,conf里定义的
Worker:不运行程序的代码,它管理当前节点的内存、CPU等计算资源,并接收Master的指令来分配具体的计算资源Executor(在新的进程中分配)
Worker只有在启动时才会向Master发送状态报告。
以下情况会触发Job: 1. Action 2. checkpoint 3. 排序
Spark 提交任务概述:

注意: Master 给 Worker 发送指令,要求其为Application 分配资源时,并不关心具体的资源是否已经分配。也就是说Master发指令后就记录了资源的分配,
以后其它客户端提交程序的时候就不会再分配该资源了。其弊端: 是其它要提交的程序可能分配不到本来可以分配的资源。
优势:在 Spark 分布式系统弱耦合的基础上最快的执行程序(否则如果Master要等到Worker最终分配成功后才通知 Driver的话,就会造成Driver阻塞,不
能够最大化并行计算资源的使用率)。默认情况下,Spark中的任务是排队的,也就是说同时只有一个任务在执行,所以其弊端并不明显。
Spark内核概述的更多相关文章
- 【大数据】Spark内核解析
1. Spark 内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spa ...
- 【Spark 内核】 Spark 内核解析-上
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更 ...
- Spark内核解析
Spark内核概述 Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制.Spark任务调度机制.Spark内存管理机制.Spark核心功能的运行原理等,熟练掌握Spark内核 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
随机推荐
- django1.8.3搭建博客——1
系统:elementary os python 2.7.6 django 1.8.3 1.安装django 先安装pip sudo apt-get install python3-pip 安装dj ...
- hdu 2044 一只小蜜蜂...(简单dp)
一只小蜜蜂... Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- JSP分页1
分页 1.什么分页? 第N页/共M页 首页 上一页 1 2 3 4 5 6 7 8 9 10 下一页 尾页 口 go 分页的优点:只查询一页,不用查询所有页! 2.分页数据 页面的数据都是由Servl ...
- linux命令学习笔记(18):locate 命令
locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案.其方法是先建立一个包括系统内所有档案名称及 路径的数据库,之后当寻找时就只需查询这个数据库,而不必实际深入档案系统之中了.在一般的 d ...
- visual studio 高级选项及配置
visual studio 是一款强大的 IDE,所谓 IDE 即是将通过命令行(一系列复杂的参数选项)编译.链接等操作内置到 IDE 的界面按钮处. 为什么新建的工程,可以直接 #include & ...
- GridView有用的小方法--2017年2月13日
原文:http://blog.csdn.net/21aspnet/article/category/285354更多:http://blog.csdn.net/21aspnet/article/cat ...
- innerdb disable error
innodb=OFF ignore-builtin-innodb skip-innodbdefault-storage-engine=myisam default-tmp-storage-engine ...
- OI省选算法汇总( 转发黄学长博客 )
[原文链接] http://hzwer.com/1234.html 注 : 蓝色为已学习算法 , 绿色为不熟练算法 , 灰色为未学习算法 1.1 基本数据结构 1. 数组 2. 链表,双向链表 3. ...
- 逐步改用 IronPython 开发你的 ASP.NET 应用程序
IronPython for ASP.NET 的 CTP 已经发布有一段时间了,我们在看了官方提供的范例之后,相信对一个 ASP.NET 应用程序中完全使用 IronPython 开发还是有一些担心的 ...
- NSDictionary和NSArray
// 字典里套数组 NSArray *array1 = @[@"huahau" , @"hehe"]; NSArray *array2 = @[@"x ...