flume 配置与使用
1、下载flume,解压到自建文件夹
2、修改flume-env.sh文件
在文件中添加JAVA_HOME
3、修改flume.conf 文件(原名好像不叫这个,我自己把模板名改了)
里面我自己配的(具体配置参见 http://flume.apache.org/FlumeUserGuide.html)
agent1 是我的代理名称
source是netcat (数据源)
channel 是memory(内存)
sink是hdfs(输出)
注意配置中添加
agent1.sinks.k1.hdfs.fileType = DataStream
否则hdfs中接收的文件会出现乱码
如果要配置根据时间来分类写入hdfs的功能,要求传入的文件必须要有时间戳(datastamp)
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License. # The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent' agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1 # For each one of the sources, the type is defined
agent1.sources.r1.type = netcat
agent1.sources.r1.channels = c1
#agent1.sources.r1.ack-every-event = false
agent1.sources.r1.max-line-length = 100
agent1.sources.r1.bind = 192.168.19.107
agent1.sources.r1.port = 44445 # Describe/configure the interceptor #agent1.sources.r1.interceptors = i1
#agent1.sources.r1.interceptors.i1.type = com.nd.bigdata.insight.interceptor.KeyTimestampForKafka$Builder # Each sink's type must be defined
#agent1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#agent1.sinks.k1.topic = insight-test6
#agent1.sinks.k1.brokerList =192.168.181.120:9092,192.168.181.121:9092,192.168.181.66:9092
#agent1.sinks.k1.batchSize=100
#agent1.sinks.k1.requiredAcks = 0 # logger
#agent1.sinks.k1.type = logger
#agent1.sinks.k1.channel = c1 #HDFS
agent1.sinks.k1.type = hdfs
agent1.sinks.k1.channel = c1
agent1.sinks.k1.hdfs.path = test/flume/events/
agent1.sinks.k1.hdfs.filePrefix = events-
agent1.sinks.k1.hdfs.round = true
agent1.sinks.k1.hdfs.roundValue = 10
agent1.sinks.k1.hdfs.roundUnit = minute
agent1.sinks.k1.hdfs.fileType = DataStream # Each channel's type is defined.
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
"flume.conf" 70L, 2291C
4、启动flume:(文件根目录下启动)
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name agent1 -Dflume.root.logger=INFO,console(里面的flume.conf ,agent1 请替换成你自己的名字)
5、用另一台机试着发送文件
telnet 192.168.19.107 44445 (创建连接)
然后发送内容
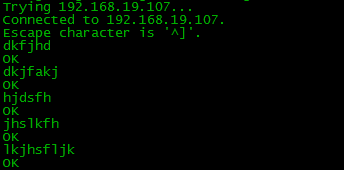
6、生成的hdfs文件

flume 配置与使用的更多相关文章
- 关于flume配置加载(二)
为什么翻flume的代码,一方面是确实遇到了问题,另一方面是想翻一下flume的源码,看看有什么收获,现在收获还谈不上,因为要继续总结.不够已经够解决问题了,而且确实有好的代码,后续会继续慢慢分享,这 ...
- flume 配置
[root@dtpweb data]#tar -zxvf apache-flume-1.7.0-bin.tar.gz[root@dtpweb conf]# cp flume-env.sh.templa ...
- 关于flume配置加载
最近项目在用到flume,因此翻了下flume的代码, 启动脚本: nohup bin/flume-ng agent -n tsdbflume -c conf -f conf/配置文件.conf -D ...
- Flume配置Replicating Channel Selector
1 官网内容 上面的配置是r1获取到的内容会同时复制到c1 c2 c3 三个channel里面 2 详细配置信息 # Name the components on this agent a1.sour ...
- Flume配置Multiplexing Channel Selector
1 官网内容 上面配置的是根据不同的heder当中state值走不同的channels,如果是CZ就走c1 如果是US就走c2 c3 其他默认走c4 2 我的详细配置信息 一个监听http端口 然后 ...
- hadoop生态搭建(3节点)-09.flume配置
# http://archive.apache.org/dist/flume/1.8.0/# ===================================================== ...
- flume配置和说明(转)
Flume是什么 收集.聚合事件流数据的分布式框架 通常用于log数据 采用ad-hoc方案,明显优点如下: 可靠的.可伸缩.可管理.可定制.高性能 声明式配置,可以动态更新配置 提供上下文路由功能 ...
- flume配置参数的意义
1.监控端口数据: flume启动: [bingo@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file jo ...
- Flume配置Failover Sink Processor
1 官网内容 2 看一张图一目了然 3 详细配置 source配置文件 #配置文件: a1.sources= r1 a1.sinks= k1 k2 a1.channels= c1 #负载平衡 a1.s ...
随机推荐
- Netty环境搭建 (源码死磕2)
[正文]netty源码 死磕2: 环境搭建 本小节目录 1. Netty为什么火得屌炸天? 1.1. Netty是什么? 1.2. Netty火到什么程度呢? 1.3. Netty为什么这么火? 2 ...
- 最简单的php验证码
<?php session_start(); // Settings: You can customize the captcha here $image_width = 120; $image ...
- mysql语句, 空的 order by , 空的 where
SQL语句里, 空的 where, where 1 AND status=1 空的 order by, order by null, updatetime desc 这种空值的情况, 是很有用处的: ...
- Python菜鸟之路:Python基础-操作缓存memcache、redis
一.搭建memcached和redis 略,自己去百度吧 二.操作Mmecached 1. 安装API python -m pip install python-memcached 2. 启动memc ...
- VS2015增量编译,加快编译速度
起因:之前工程设置的好好的, 改动一个文件,必定是只编译该文件相关的.然而最近就是无论是否改动文件,都会有部分文件重新编译. 解决流程:查看增量编译的设置1.1 因为工程是在Debug模式下,so清空 ...
- Virtualbox报错------> '/etc/init.d/vboxdrv setup'
Ubuntu下VirtualBox本来可以很好地用的,今天早上一来就报错了,--提示如下内容: ---------------------------------------------------- ...
- Linux使用yum安装rpm包
1.yum其实管理的也是rpm包,只不过依赖什么的都自己做了2.yum在有的linux版本是收费的,但是CentOS是免费的3.yum一般意义上是需要联网的,即:使用网络yum源 a.yum源配置文件 ...
- 移动端 触摸事件 ontouchstart、ontouchmove、ontouchend、ontouchcancel[转]
转:http://www.cnblogs.com/irelands/p/3433628.html 1.Touch事件简介pc上的web页面鼠 标会产生onmousedown.onmouseup.onm ...
- Spring之AOP由浅入深(转发:https://www.cnblogs.com/zhaozihan/p/5953063.html)
1.AOP的作用 在OOP中,正是这种分散在各处且与对象核心功能无关的代码(横切代码)的存在,使得模块复用难度增加.AOP则将封装好的对象剖开,找出其中对多个对象产生影响的公共行为,并将其封装为一个可 ...
- python3 pillow使用测试
# -*- encoding=utf-8 -*- ''''' pil处理图片,验证,处理 大小,格式 过滤 压缩,截图,转换 图片库最好用Pillow 还有一个测试图片img.jpg, 一个log图片 ...