phantomjs 抓取房产信息
抓取https://sf.taobao.com/item_list.htm信息
driver=webdriver.PhantomJS(service_args=['--ssl-protocol=any'])
or
driver = webdriver.PhantomJS( service_args=['--ignore-ssl-errors=true'])
cur_driver=webdriver.PhantomJS(service_args=['--ssl-protocol=any', '--load-images=false'])
service_args=['--load-images=false']
抓取代码
# coding=utf-8
import os
import re
from selenium import webdriver
# from selenium.common.exceptions import TimeoutException
import selenium.webdriver.support.ui as ui
import time
from datetime import datetime
from selenium.webdriver.common.action_chains import ActionChains
import IniFile
# from threading import Thread
from pyquery import PyQuery as pq
import LogFile
import mongoDB
import urllib class taobao(object):
def __init__(self):
self.driver = webdriver.PhantomJS(service_args=['--ssl-protocol=any'])
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
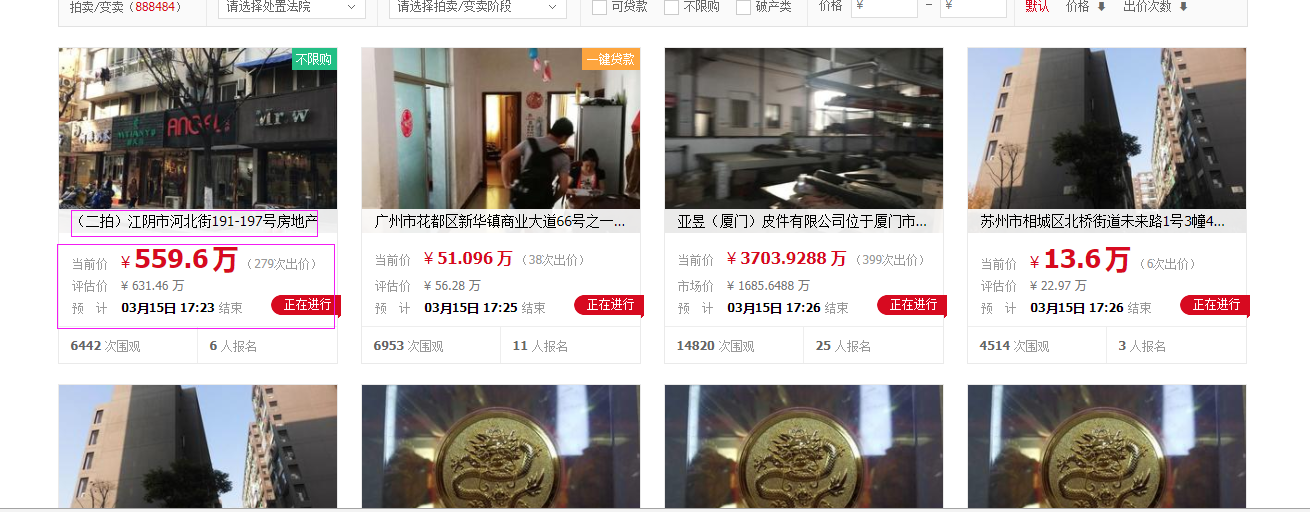
self.url ='https://sf.taobao.com/item_list.htm' def scrapy_date(self):
try:
self.driver.get(self.url) selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
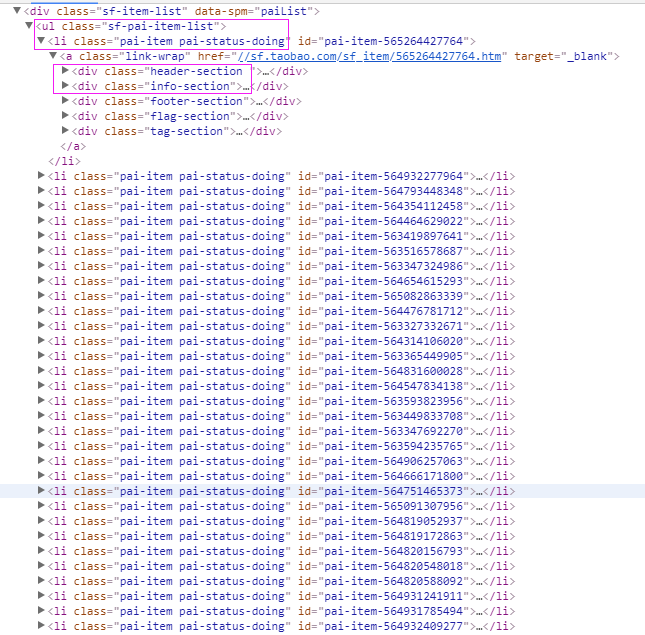
Elements = doc('ul[class="sf-pai-item-list"]').find('li[class="pai-item pai-status-doing"]')
for element in Elements.items():
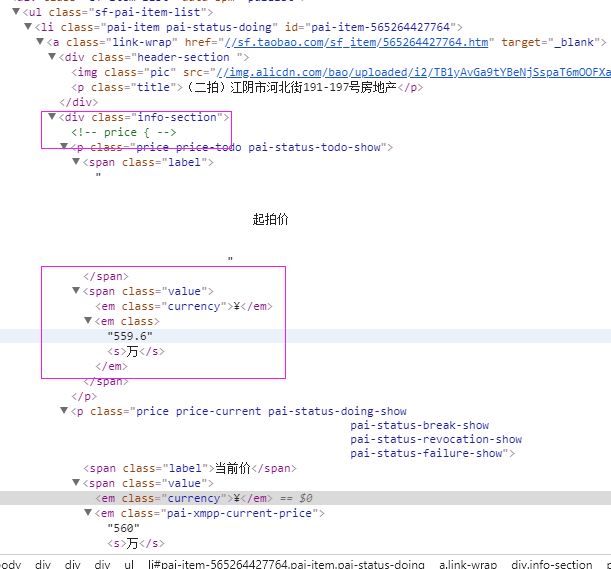
priceinfo = element('div[class="info-section"]').find('p').text().encode('utf8').strip()
title = element('div[class="header-section "]').find('p').text().encode('utf8').strip()
print title
print priceinfo
print '--------------------------------------------------------------------------------' except Exception, e:
print e.message
finally:
pass obj = taobao()
obj.scrapy_date()
抓取结果

phantomjs 抓取房产信息的更多相关文章
- NodeJS + PhantomJS 抓取页面信息以及截图
利用PhantomJS做网页截图经济适用,但其API较少,做其他功能就比较吃力了.例如,其自带的Web Server Mongoose最高只能同时支持10个请求,指望他能独立成为一个服务是不怎么实际的 ...
- [Python爬虫] 之十一:Selenium +phantomjs抓取活动行中会议活动信息
一.介绍 本例子用Selenium +phantomjs爬取活动行(http://www.huodongxing.com/search?qs=数字&city=全国&pi=1)的资讯信息 ...
- C#使用Selenium+PhantomJS抓取数据
本文主要介绍了C#使用Selenium+PhantomJS抓取数据的方法步骤,具有很好的参考价值,下面跟着小编一起来看下吧 手头项目需要抓取一个用js渲染出来的网站中的数据.使用常用的httpclie ...
- [Python爬虫] 之十:Selenium +phantomjs抓取活动行中会议活动
一.介绍 本例子用Selenium +phantomjs爬取活动树(http://www.huodongshu.com/html/find_search.html?search_keyword=数字) ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码. 一.分析需求和网站结构 allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页. ...
- PHP快速抓取快递信息
<?php header("Content-type:text/html;charset=utf-8"); /** * Express.class.php 快递查询类 * @ ...
- CasperJS基于PhantomJS抓取页面
CasperJS基于PhantomJS抓取页面 Casperjs是基于Phantomjs的,而Phantom JS是一个服务器端的 JavaScript API 的 WebKit. CasperJS是 ...
- .net抓取网页信息 - Jumony框架使用1
往往在实际开发中,经常会用到一些如抓取网站信息之类的的操作,往往大家采用的是用一些正则的方式获取,但是有时候正则是很死板的,我们常常试想能不能使用jquery的选择器,获取符合自己要求的元素,然后进行 ...
随机推荐
- python在windows下连接mysql数据库
一,安装MySQL-python python 连接mysql数据库需要 Python interface to Mysql包,包名为 MySQL-python ,PyPI上现在到了1.2.5版本.M ...
- Linux下使用ssh远程登录服务器
如果自己的服务器是在内网,想在外网通过ssh在自己的VPS服务器上远程登录自己的内网服务器,可以按照如下操作: 一.在自己的服务器上使用如下命令: #ssh -CfnNT -R 端口A:localho ...
- head first (三):装饰者模式
看到别人写的,都看不进去,算了还是自己手写一遍吧,算是帮助自己理解了.写的比较简单,例子也比较好懂,什么时候使用自己看着办. 1.定义 装饰者模式:动态地将职责附加到对象上.若要扩展功能,装饰者提供比 ...
- git更新远程仓库代码到本地
1 使用命令查看连接的远程的仓库 git remote -v 2 远程获取代码 git fetch origin master 如果出现 Already up-to-date 说明代码更新好了 出现 ...
- LeetCode 461 汉明距离/LintCode 365 统计二进制中1的个数
LeetCode 461. 汉明距离 or LintCode 365. 二进制中有多少个1 题目一:LeetCode 461. 汉明距离 LeetCode 461.明距离(Hamming Distan ...
- Python urllib2 设置超时时间并处理超时异常
可以使用 except: 捕获任何异常,包括 SystemExit 和 KeyboardInterupt,不过这样不便于程序的调试和使用 最简单的情况是捕获 urllib2.URLError try: ...
- 针对MySql封装的JDBC通用框架类(包含增删改查、JavaBean反射原理)
package com.DBUtils; import java.lang.reflect.Field; import java.sql.Connection; import java.sql.Dri ...
- vue组件scoped CSS及/deep/深度选择器
参考链接:https://vue-loader.vuejs.org/zh/guide/scoped-css.html#%E5%AD%90%E7%BB%84%E4%BB%B6%E7%9A%84%E6%A ...
- 【Leetcode】264. Ugly Number II ,丑数
原题 Write a program to find the n-th ugly number. Ugly numbers are positive numbers whose prime facto ...
- 【HDU 3622】Bomb Game
http://acm.hdu.edu.cn/showproblem.php?pid=3622 二分答案转化成2-sat问题. 上午测试时总想二分后把它转化成最大点独立集但是不会写最大点独立集暴力又秘制 ...