Ceph源码解析:Scrub故障检测
转载请注明出处 陈小跑 http://www.cnblogs.com/chenxianpao/p/5878159.html
本文只梳理了大致流程,细节部分还没搞的太懂,有时间再看,再补充,有错误请指正,谢谢。
Ceph 的主要一大特点是强一致性,这里主要指端到端的一致性。众所周知,传统存储路径上从应用层到内核的文件系统、通用块层、SCSI层到最后的HBA和磁盘控制器,每层都有发生错误的可能性,因此传统的端到端解决方案会以数据块校验为主来解决。而在 Ceph 方面,更是加入了 Ceph 自己的客户端和网络、存储逻辑、数据迁移,势必导致更高的错误概率。
因为 Ceph 作为一个应用层的路径,它利用了 POSIX 接口进行存储并支持 Parity Read/Write,这时候如果封装固定数据块并且加入校验数据会导致较严重的性能问题,因此 Ceph 在这方面只是引入 Scrub 机制(Read Verify)来保证数据的正确性。
简单来说,Ceph 的 OSD 会定时启动 Scrub 线程来扫描部分对象,通过与其他副本进行对比来发现是否一致,如果存在不一致的情况,Ceph 会抛出这个异常交给用户去解决。
一、Scrub 核心流程
/*
* Chunky scrub scrubs objects one chunk at a time with writes blocked for that
* chunk.
* The object store is partitioned into chunks which end on hash boundaries. For
* each chunk, the following logic is performed:
* (1) Block writes on the chunk //阻塞写
* (2) Request maps from replicas//从副本获取maps
* (3) Wait for pushes to be applied (after recovery)//等待pushes生效
* (4) Wait for writes to flush on the chunk//等待写刷入chunk
* (5) Wait for maps from replicas//等待获取maps
* (6) Compare / repair all scrub maps//比较修复
* The primary determines the last update from the subset by walking the log. If
* it sees a log entry pertaining to a file in the chunk, it tells the replicas
* to wait until that update is applied before building a scrub map. Both the
* primary and replicas will wait for any active pushes to be applied.
* In contrast to classic_scrub, chunky_scrub is entirely handled by scrub_wq.
*/

二、Scrub 函数流程:从PG::chunky_scrub开始进行scrub的状态机
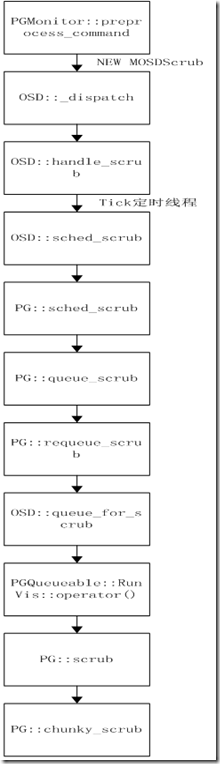
NEW_CHUNK状态_request_scrub_map函数发送new MOSDRepScrub消息给replicas,replicas处理流程:
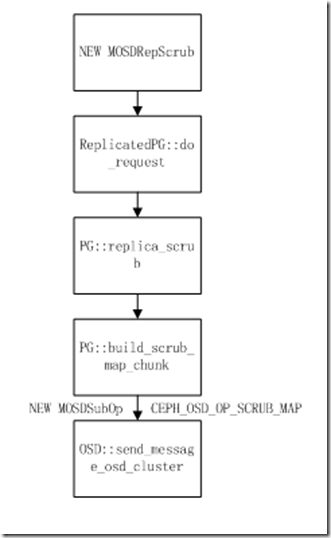
Primary接收到MOSDSubOp消息后的处理流程:

将收到的replicas的scrubmap写入到scrubber.received_maps中;
对于所有replicas都返回scrubmap,则调用PG::requeue_scrub()函数重新进入scrub操作
三、Scrub 状态机
① INACTIVE
开始进行scrub;更新osd的状态;设置scrubber的状态信息,比如start、state、epoch_start等,将state设置成NEW_CHUNK
② NEW_CHUNK
初始化scrubber.primary_scrubmap、received_maps;根据osd_scrub_chunk_min和osd_scrub_chunk_max获取指定数量个object(具体如何获取,从何获取?);向所有的actingbackfill副本发送new MOSDRepScrub()消息,获取scrub_map信息,将状态设置成WAIT_PUSHES
③ WAIT_PUSHES
等待PUSH(push什么?)完成,如果active_pushes为0则把状态设置成WAIT_LAST_UPDATE
④ WAIT_LAST_UPDATE
等待update(update什么?)完成,如果last_update_applied大于scrubber.subset_last_update把状态设置成BUILD_MAP
⑤ BUILD_MAP
建立一个scrub_map,读取对象的大小和属性信息,如果是deep模式,根据EC和replicate两种pool计算不同的CRC32校验码,repicate类型以omap_header计算CRC值,EC类型的CRC值为object的hash值;scrubmap包括 object size, attr 和omap attr, 历史版本信息;把状态设置成WAIT_REPLICAS
⑥ WAIT_REPLICAS
等待收到replicas返回的信息,把状态设置成COMPARE_MAPS
⑦ COMPARE_MAPS
根据scrubber.primary_scrubmap创建权威authmap;建立包含所有object的master set;遍历master set,选择一个没发生异常的权威的osd作为比较对象,比较文件大小、属性信息以及digest信息(digest and omap_digest);记录错误对象和丢失对象,后续recovery恢复;将状态设置成WAIT_DIGEST_UPDATES。
⑧ WAIT_DIGEST_UPDATES
ReplicatedPG::_scrub()函数完成(做了什么);如果还有obj未校验完,则继续回到NEW_CHUNK流程,重复以上动作;如果全部校验完则进去FINISH状态
⑨ FINISH
Scrub结束
注:
1. OSD 会以 PG 为粒度触发 Scrub 流程,触发的频率可以通过选项指定,而一个 PG 的 Scrub 启动都是由该 PG 的 Master 角色所在 OSD 启动
2. 一个 PG 在普通的环境下会包含几千个到数十万个不等的对象,因为 Scrub 流程需要提取对象的校验信息然后跟其他副本的校验信息对比,这期间被校验对象的数据是不能被修改的。因此一个 PG 的 Scrub 流程每次会启动小部分的对象校验,Ceph 会以每个对象名的哈希值的部分作为提取因子,每次启动对象校验会找到符合本次哈希值的对象,然后进行比较。这也是 Ceph 称其为 Chunky Scrub 的原因。
3. 在找到待校验对象集后,发起者需要发出请求来锁定其他副本的这部分对象集。因为每个对象的 master 和 replicate 节点在实际写入到底层存储引擎的时间会出现一定的差异。这时候,待校验对象集的发起者会附带一个版本发送给其他副本,直到这些副本节点与主节点同步到相同版本。
4. 在确定待校验对象集在不同节点都处于相同版本后,发起者会要求所有节点都开始计算这个对象集的校验信息并反馈给发起者。
5. 该校验信息包括每个对象的元信息如大小、扩展属性的所有键和历史版本信息等等,在 Ceph 中被称为 ScrubMap。
6. 发起者会比较多个 ScrubMap并发现不一致的对象,不一致对象会被收集最后发送给 Monitor,最后用户可以通过 Monitor 了解 Scrub 的结果信息
用户在发现出现不一致的对象后,可以通过 “ceph pg repair [pg_id]” 的方式来启动修复进程,目前的修复仅仅会将主节点的对象全量复制到副本节点,因此目前要求用户手工确认主节点的对象是”正确副本”。另外,Ceph 允许 Deep Scrub 模式来全量比较对象信息来期望发现 Ceph 本身或者文件系统问题,这通常会带来较大的 IO 负担,因此在实际生产环境中很难达到预期效果。
四、Scrub 测试
实验1:验证 scrubbing 和 repair 机制
Scrubbing 是 Ceph 保持数据完整性的一个机制,类似于文件系统中的 fsck,它会发现存在的数据不一致。scrubbing 会影响集群性能。它分为两类:
· 一类是默认每天进行的,称为 light scrubbing,其周期由配置项 osd scrub min interval (默认24小时)和 osd scrub max interval (默认7天)决定。它通过检查对象的大小和属性来发现数据轻度不一致性问题。
· 另一种是默认每周进行的,称为 deep scrubbing,其周期由配置项 osd deep scrub interval (默认一周)决定。它通过读取数据并做 checksum 检查数据来发现数据深度不一致性问题。
下面是默认的 osd scrub 的配置项:
root@ceph2:~# ceph --admin-daemon /var/run/ceph/ceph-osd.5.asok config show | grep scrub"osd_scrub_thread_timeout": "60","osd_scrub_thread_suicide_timeout": "60","osd_scrub_finalize_thread_timeout": "600","osd_scrub_finalize_thread_suicide_timeout": "6000","osd_scrub_invalid_stats": "true","osd_max_scrubs": "1","osd_scrub_load_threshold": "0.5","osd_scrub_min_interval": "86400","osd_scrub_max_interval": "604800","osd_scrub_chunk_min": "5","osd_scrub_chunk_max": "25","osd_scrub_sleep": "0","osd_deep_scrub_interval": "604800","osd_deep_scrub_stride": "524288",
实验过程:
0:找到对象的 PG acting set
osdmap e334 pool 'pool1' (9) object 'Evernote_5.8.6.7519.exe' -> pg 9.6094a41e (9.1e) -> up ([5,3,0], p5) acting ([5,3,0], p5)
1:删除对象的文件
根据 pg id,osd id 以及 object name,找到 osd.5 上文件路径为 /var/lib/ceph/osd/ceph-5/current/9.1e_head/Evernote\u5.8.6.7519.exe__head_6094A41E__9,将它删除
2:设置 light scrub 周期
为了不等一天,将osd_scrub_min_interval 和 osd_scrub_max_interval 都设为4分钟:
root@ceph2:/var/run/ceph# ceph --admin-daemon ceph-osd.5.asok config set osd_scrub_max_interval 240
{ "success": "osd_scrub_max_interval = '240' "}root@ceph2:/var/run/ceph# ceph --admin-daemon ceph-osd.5.asok config get osd_scrub_max_interval
{ "osd_scrub_max_interval": "240"}
root@ceph2:/var/run/ceph# ceph --admin-daemon ceph-osd.5.asok config set osd_scrub_min_interval 240
{ "success": "osd_scrub_min_interval = '240' "}
root@ceph2:/var/run/ceph# ceph --admin-daemon ceph-osd.5.asok config get osd_scrub_min_interval
{ "osd_scrub_min_interval": "240"}
3:尝试 light scrub,发现问题
能看到 light scrub 按计划进行了,而且发现了 pg 9.1e 的问题,即有文件丢失了:
2016-06-06 18:15:49.798236 osd.5 [INF] 9.1d scrub ok
2016-06-06 18:15:50.799835 osd.5 [ERR] 9.1e shard 5 missing 6094a41e/Evernote_5.8.6.7519.exe/head//92016-06-06 18:15:50.799863 osd.5 [ERR] 9.1e scrub 1 missing, 0 inconsistent objects2016-06-06 18:15:50.799866 osd.5 [ERR] 9.1e scrub 1 errors2016-06-06 18:15:52.804444 osd.5 [INF] 9.20 scrub ok
pgmap 呈现 inconsistent 状态:
2016-06-06 18:15:58.439927 mon.0 [INF] pgmap v5752: 64 pgs: 63 active+clean, 1 active+clean+inconsistent; 97071 kB data, 2268 MB used, 18167 MB / 20435 MB avail
此时集群状态是 ERROR 状态:
health HEALTH_ERR 1 pgs inconsistent; 1 scrub errors;
除了定时的清理外,管理员也可以通过命令启动清理过程:
root@ceph1:~# ceph pg scrub 9.1einstructing pg 9.1e on osd.5 to scrub
从输出能看出来,scrubbing 是由 PG 的主 OSD 发起的。
4:尝试 deep scrub,结果相同。
手工运行命令 ceph pg deep-scrub 9.1e,它会启动深度清理,结果相同。
5:尝试 pg repair,成功
运行 ceph pg repair 9.1e,启动 PG 修复过程,结果修复成功(1 errors, 1 fixed),被删除的文件回来了,集群重新回到 OK 状态。
结论:
· PG scrubbing 能发现文件丢失的问题
· PG scrubbing 对集群性能有负面影响,可以适当降低其优先级以及所需要的资源。
注意:PG repair 目前还有不少问题,根据这篇文章,它会将 primary osd 上的数据复制到其它osd上,这可能会导致正确的数据被错误的数据覆盖,因此使用需要谨慎。下面的实验将验证这个问题。
实验2:验证scrubbing 能不能发现内容不一致问题,以及 pg repair 的行为
0:创建一个对象,其内容是一个含有字符串 1111 的文本文件,其PG分布在 [2,0,3] 上。
1:修改 osd.2 上文件内容为 1122
2:启动 light scrub,9.2e scrub ok,无法发现问题。这不是蛮奇怪的么??light scrub 应该会检查文件属性和大小,属性应该包括修改时间吧,应该能检查出来啊。。
3. 启动 deep scrub,9.2e deep-scrub ok,无法发现问题。这不是蛮奇怪的么??deep scrub 应该会检查对象数据的啊,数据变了,应该能检查出来啊。。。
4. 启动 pg repair,内容不变。对不在 inconsistent 状态的 PG 看来做repair 不会做什么。
5. 继续修改 osd.2 上的文件,增加内容,致其 size 改变。
6. 启动 light scrub,终于发现 shard 2: soid b2e6cb6e/text/head//9 size 931 != known size 5, 1 inconsistent objects,集群状态也变为 HEALTH_ERR。
7. 启动 deep scrub,它也同样地终于发现了问题。
8. 运行 rados get 命令,能正确获取原始文件。这说明即使集群处于HEALTH_ERR 状态,处于 active+clean+inconsistent 状态的 PG 的 IO 能正常进行。
9. 启动 pg repari,osd.2 上的文件被覆盖,回到原始内容。这说明 pg repair 也不是从主osd 向别的 osd 拷贝嘛。。
结论:
· 两种 scrubbing 只是根据不同的方法来发现数据一致性上的不同类型的问题,修复的事情它不管;不是所有的问题它们都能发现;经过验证,size 的变化会被发现,但是在size不变内容改变的时候不能被发现。
· pg repair 也不是像 Re: [ceph-users] Scrub Error / How does ceph pg repair work? 所说的简单地将 primary osd 上的数据拷贝到其它 osd 上,这种做法很明显这可能会导致正确的数据被损坏。文章是写于 2015 年,我的ceph 版本是 0.8.11,也许两者有不一致。
五、Scrub 问题
正如流程所述,目前的 Scrub 有以下问题:
1. 在发现不一致对象后,缺少策略来自动矫正错误,比如如果多数副本达成一致,那么少数副本对象会被同化
2. Scrub 机制并不能及时解决存储系统端到端正确的问题,很有可能上层应用早已经读到错误数据
对于第一个问题,目前 Ceph 已经有 Blueprint 来加强 Scrub 的修复能力,用户启动 Repair 时会启动多数副本一致的策略来替代目前的主副本同步策略。
对于第二个问题,传统端到端解决方案会更多采用固定数据块附加校验数据的“端到端校验”方案,但是 Ceph 因为并不是存储设备空间实际的管理和分配者,它依赖于文件系统来实现存储空间的管理,如果采用对象校验的方式会严重损耗性能。因此在从文件系统到设备的校验需要依赖于文件系统,而 Ceph 包括客户端和服务器端的对象正确性校验只能更多的依赖于 Read Verify 机制,在涉及数据迁移时需要同步的比较不同副本对象的信息来保证正确性。目前的异步方式会允许期间发生错误数据返回的可能性。
参考文档:
本文的测试参考于刘世民(Sammy Liu) http://www.cnblogs.com/sammyliu/p/5568989.html ,后续有空再结合代码做个测试
概念性的描述参考于 https://www.ustack.com/blog/ceph-internal-scrub/
Ceph源码解析:Scrub故障检测的更多相关文章
- Ceph源码解析:读写流程
转载注明出处,整理也是需要功夫的,http://www.cnblogs.com/chenxianpao/p/5572859.html 一.OSD模块简介 1.1 消息封装:在OSD上发送和接收信息. ...
- Ceph源码解析:PG peering
集群中的设备异常(异常OSD的添加删除操作),会导致PG的各个副本间出现数据的不一致现象,这时就需要进行数据的恢复,让所有的副本都达到一致的状态. 一.OSD的故障和处理办法: 1. OSD的故障种类 ...
- Ceph源码解析:CRUSH算法
1.简介 随着大规模分布式存储系统(PB级的数据和成百上千台存储设备)的出现.这些系统必须平衡的分布数据和负载(提高资源利用率),最大化系统的性能,并要处理系统的扩展和硬件失效.ceph设计了CRUS ...
- Ceph源码解析:概念
Peering:一个PG内的所有副本通过PG日志来达成数据一致的过程.(某PG如果处于Peering将不能对外提供读写服务) Recovery:根据Peering的过程中产生的.依据PG日志推算出的不 ...
- 【原】Android热更新开源项目Tinker源码解析系列之三:so热更新
本系列将从以下三个方面对Tinker进行源码解析: Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Android热更新开源项目Tinker源码解析系列之二:资源文件热更新 A ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
- 【原】Android热更新开源项目Tinker源码解析系列之二:资源文件热更新
上一篇文章介绍了Dex文件的热更新流程,本文将会分析Tinker中对资源文件的热更新流程. 同Dex,资源文件的热更新同样包括三个部分:资源补丁生成,资源补丁合成及资源补丁加载. 本系列将从以下三个方 ...
- 多线程爬坑之路-Thread和Runable源码解析之基本方法的运用实例
前面的文章:多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类) 多线程爬坑之路-Thread和Runable源码解析 前面 ...
- jQuery2.x源码解析(缓存篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 缓存是jQuery中的又一核心设计,jQuery ...
随机推荐
- spring使用aop需要的jar包,和常见异常
3.0以后spring不再一起发布aop依赖包,需要自己导入: 必须包: 这几个jar包分别为 1.org.springframework.aop-3.1.1.RELEASE 这个是spring的 ...
- Container With Most Water——双指针
Given n non-negative integers a1, a2, ..., an, where each represents a point at coordinate (i, ai). ...
- opencv c++实用操作
像素遍历 对单通道图像的遍历处理 For( int i =0 ; i < grayim.rows; i++) For(int j = 0; j<grayim.cols; j++) Gray ...
- BootStrap 实现导航栏nav透明,nav子元素文字不透明
在给nav 的属性赋值 opacity:0.0透明度时会导致nav内子元素会继承opacity属性.此时再对子元素赋值opacity:1.0 时会导致 子元素实际opacity值为0.0*1.0=0. ...
- [水煮 ASP.NET Web API2 方法论](1-6)Model Validation
问题 想要 ASP.NET Web API 执行模型验证,同时可以和 ASP.NET MVC 共享一些验证逻辑. 解决方案 ASP.NET Web API 与 ASP.NET MVC 支持一样的验证机 ...
- 动态创建timer
Private timer:Ttimer;procedure MyTimerDo(Sender:Tobject);procedure create ; timer:=TtIMER.Create; ...
- redis三种连接方式
安装 tar zxvf redis-2.8.9.tar.gz cd redis-2.8.9 #直接make 编译 make #可使用root用户执行`make install`,将可执行文件拷贝到/u ...
- Python 实现腾讯新闻抓取
原文地址:http://www.cnblogs.com/rails3/archive/2012/08/14/2636780.htm 思路: 1.抓取腾讯新闻列表页面: http://news.qq.c ...
- gvim 编辑器配置
"关才兼容模式 set nocompatible "模仿快捷键,如:ctrt+A 全选.Ctrl+C复制. Ctrl+V 粘贴等 source $VIMRUNTIME/vimrc_ ...
- markdown与html之间转换引发的问题
https://www.hackersb.cn/hacker/235.html 看了这位师傅的文章有感而发 前言 对于支持markdown语法的网站,一般都是在后端将markdown语法渲染为html ...