disruptor--Introduction
The best way to understand what the Disruptor is, is to compare it to something well understood and quite similar in purpose. In the case of the Disruptor this would be Java's BlockingQueue. Like a queue the purpose of the Disruptor is to move data (e.g. messages or events) between threads within the same process. However there are some key features that the Disruptor provides that distinguish it from a queue. They are:
- Multicast events to consumers, with consumer dependency graph.
- Pre-allocate memory for events.
- Optionally lock-free.
Core Concepts
Before we can understand how the Disruptor works, it is worthwhile defining a number of terms that will be used throughout the documentation and the code. For those with a DDD bent, think of this as the ubiquitous language of the Disruptor domain.
- Ring Buffer: The Ring Buffer is often considered the main aspect of the Disruptor, however from 3.0 onwards the Ring Buffer is only responsible for the storing and updating of the data (Events) that move through the Disruptor. And for some advanced use cases can be completely replaced by the user.
- Sequence: The Disruptor uses Sequences as a means to identify where a particular component is up to. Each consumer (EventProcessor) maintains a Sequence as does the Disruptor itself. The majority of the concurrent code relies on the the movement of these Sequence values, hence the Sequence supports many of the current features of an AtomicLong. In fact the only real difference between the 2 is that the Sequence contains additional functionality to prevent false sharing between Sequences and other values.
- Sequencer: The Sequencer is the real core of the Disruptor. The 2 implementations (single producer, multi producer) of this interface implement all of the concurrent algorithms use for fast, correct passing of data between producers and consumers.
- Sequence Barrier: The Sequence Barrier is produced by the Sequencer and contains references to the main published Sequence from the Sequencer and the Sequences of any dependent consumer. It contains the logic to determine if there are any events available for the consumer to process.
- Wait Strategy: The Wait Strategy determines how a consumer will wait for events to be placed into the Disruptor by a producer. More details are available in the section about being optionally lock-free.
- Event: The unit of data passed from producer to consumer. There is no specific code representation of the Event as it defined entirely by the user.
- EventProcessor: The main event loop for handling events from the Disruptor and has ownership of consumer's Sequence. There is a single representation called BatchEventProcessor that contains an efficient implementation of the event loop and will call back onto a used supplied implementation of the EventHandler interface.
- EventHandler: An interface that is implemented by the user and represents a consumer for the Disruptor.
- Producer: This is the user code that calls the Disruptor to enqueue Events. This concept also has no representation in the code.
To put these elements into context, below is an example of how LMAX uses the Disruptor within its high performance core services, e.g. the exchange.
Figure 1. Disruptor with a set of dependent consumers.
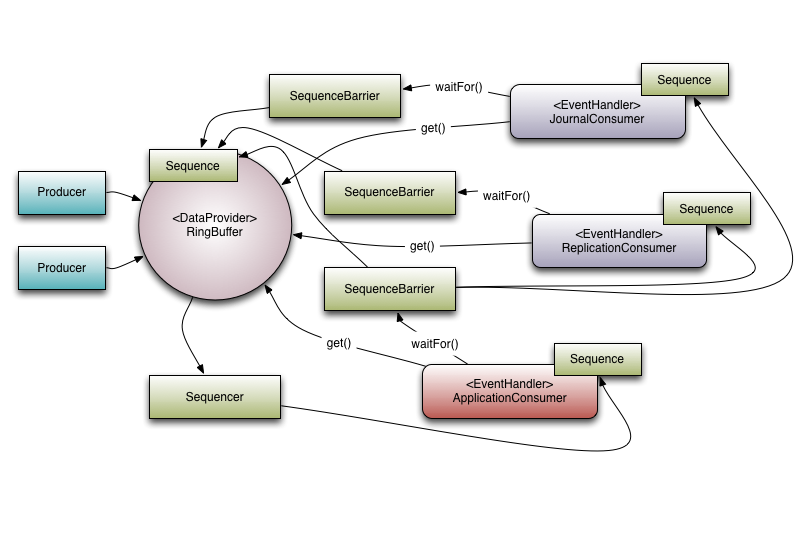
Multicast Events
This is the biggest behavioural difference between queues and the Disruptor. When you have multiple consumers listening on the same Disruptor all events are published to all consumers in contrast to a queue where a single event will only be sent to a single consumer. The behaviour of the Disruptor is intended to be used in cases where you need to independent multiple parallel operations on the same data. The canonical example from LMAX is where we have three operations, journalling (writing the input data to a persistent journal file), replication (sending the input data to another machine to ensure that there is a remote copy of the data), and business logic (the real processing work). The Executor-style event processing, where scale is found by processing different events in parallel at the same is also possible using the WorkerPool. Note that is bolted on top of the existing Disruptor classes and is not treated with the same first class support, hence it may not be the most efficient way to achieve that particular goal.
Looking at Figure 1. is possible to see that there are 3 Event Handlers listening (JournalConsumer, ReplicationConsumer and ApplicationConsumer) to the Disruptor, each of these Event Handlers will receive all of the messages available in the Disruptor (in the same order). This allow for work for each of these consumers to operate in parallel.
Consumer Dependency Graph
To support real world applications of the parallel processing behaviour it was necessary to support co-ordination between the consumers. Referring back to the example described above, it necessary to prevent the business logic consumer from making progress until the journalling and replication consumers have completed their tasks. We call this concept gating, or more correctly the feature that is a super-set of this behaviour is called gating. Gating happens in two places. Firstly we need to ensure that the producers do not overrun consumers. This is handled by adding the relevant consumers to the Disruptor by calling RingBuffer.addGatingConsumers(). Secondly, the case referred to previously is implemented by constructing a SequenceBarrier containing Sequences from the components that must complete their processing first.
Referring to Figure 1. there are 3 consumers listening for Events from the Ring Buffer. There is a dependency graph in this example. The ApplicationConsumer depends on the JournalConsumer and ReplicationConsumer. This means that the JournalConsumer and ReplicationConsumer can run freely in parallel with each other. The dependency relationship can be seen by the connection from the ApplicationConsumer's SequenceBarrier to the Sequences of the JournalConsumer and ReplicationConsumer. It is also worth noting the relationship that the Sequencer has with the downstream consumers. One of its roles is to ensure that publication does not wrap the Ring Buffer. To do this none of the downstream consumer may have a Sequence that is lower than the Ring Buffer's Sequence less the size of the Ring Buffer. However using the graph of dependencies an interesting optimisation can be made. Because the ApplicationConsumers Sequence is guaranteed to be less than or equal to JournalConsumer and ReplicationConsumer (that is what that dependency relationship ensures) the Sequencer need only look at the Sequence of the ApplicationConsumer. In a more general sense the Sequencer only needs to be aware of the Sequences of the consumers that are the leaf nodes in the dependency tree.
Event Preallocation
One of the goals of the Disruptor was to enable use within a low latency environment. Within low-latency systems it is necessary to reduce or remove memory allocations. In Java-based system the purpose is to reduce the number stalls due to garbage collection (in low-latency C/C++ systems, heavy memory allocation is also problematic due to the contention that be placed on the memory allocator).
To support this the user is able to preallocate the storage required for the events within the Disruptor. During construction and EventFactory is supplied by the user and will be called for each entry in the Disruptor's Ring Buffer. When publishing new data to the Disruptor the API will allow the user to get hold of the constructed object so that they can call methods or update fields on that store object. The Disruptor provides guarantees that these operations will be concurrency-safe as long as they are implemented correctly.
Optionally Lock-free
Another key implementation detail pushed by the desire for low-latency is the extensive use of lock-free algorithms to implement the Disruptor. All of the memory visibility and correctness guarantees are implemented using memory barriers and/or compare-and-swap operations. There is only one use-case where a actual lock is required and that is within the BlockingWaitStrategy. This is done solely for the purpose of using a Condition so that a consuming thread can be parked while waiting for new events to arrive. Many low-latency systems will use a busy-wait to avoid the jitter that can be incurred by using a Condition, however in number of system busy-wait operations can lead to significant degradation in performance, especially where the CPU resources are heavily constrained. E.g. web servers in virtualised-environments.
https://github.com/LMAX-Exchange/disruptor/wiki/Introduction
disruptor--Introduction的更多相关文章
- LMAX Disruptor—多生产者多消费者中,消息复制分发的高性能实现
解决的问题 当我们有多个消息的生产者线程,一个消费者线程时,他们之间如何进行高并发.线程安全的协调? 很简单,用一个队列. 当我们有多个消息的生产者线程,多个消费者线程,并且每一条消息需要被所有的消费 ...
- 1.Introduction 介绍
Welcome to Log4j 2! Introduction Almost every large application includes its own logging or tracing ...
- [翻译]高并发框架 LMAX Disruptor 介绍
原文地址:Concurrency with LMAX Disruptor – An Introduction 译者序 前些天在并发编程网,看到了关于 Disruptor 的介绍.感觉此框架惊为天人,值 ...
- 图解Disruptor框架(二):核心概念
图解Disruptor框架(二):核心概念 概述 上一个章节简单的介绍了了下Disruptor,这节就是要好好的理清楚Disruptor中的核心的概念.并且会给出个HelloWorld的小例子. 在正 ...
- Disruptor—核心概念及体验
本文基于最新的3.4.2的版本文档进行翻译,翻译自: https://github.com/LMAX-Exchange/disruptor/wiki/Introduction https://gith ...
- Disruptor系列(一)— disruptor介绍
本文翻译自Disruptor在github上的wiki文章Introduction,原文可以看这里. 一.前言 作为程序猿大多数都有对技术的执着,想在这个方面有所提升.对于优秀的事物保持积极学习的心态 ...
- A chatroom for all! Part 1 - Introduction to Node.js(转发)
项目组用到了 Node.js,发现下面这篇文章不错.转发一下.原文地址:<原文>. ------------------------------------------- A chatro ...
- Introduction to graph theory 图论/脑网络基础
Source: Connected Brain Figure above: Bullmore E, Sporns O. Complex brain networks: graph theoretica ...
- 架构师养成记--15.Disruptor并发框架
一.概述 disruptor对于处理并发任务很擅长,曾有人测过,一个线程里1s内可以处理六百万个订单,性能相当感人. 这个框架的结构大概是:数据生产端 --> 缓存 --> 消费端 缓存中 ...
- INTRODUCTION TO BIOINFORMATICS
INTRODUCTION TO BIOINFORMATICS 这套教程源自Youtube,算得上比较完整的生物信息学领域的视频教程,授课内容完整清晰,专题化的讲座形式,细节讲解比国内的京师大 ...
随机推荐
- 数据库_mysql多表操作
多表操作 实际开发中,一个项目通常需要很多张表才能完成.例如:一个商城项目就需要分类表(category).商品表(products).订单表(orders)等多张表.且这些表的数据之间 ...
- ABP架构
ABP架构 一.什么是ABP架构? ABP是“ASP.NET Boilerplate Project (ASP.NET样板项目)”的简称. ASP.NET Boilerplate 基于DDD的经典分层 ...
- 2015-9-13 NOIP模拟赛解题报告(by hzwer)
小奇挖矿 「题目背景」 小奇要开采一些矿物,它驾驶着一台带有钻头(初始能力值w)的飞船,按既定路线依次飞过喵星系的n个星球. 「问题描述」 星球分为2类:资源型和维修型. 1.资源型:含矿物质量a[i ...
- js计算机样式window.getComputedStyle(ele,null)与
一.getComputedStyle兼容IE8以上,范户籍的计算样式的值都是绝对值,没有相对单位(如:width:10em; 它打印出来是160px) window.getComputedStyle( ...
- ubuntu设置root登录ssh
1. 默认不带ssh,所以需要安装一下ssh sudo apt install openssh-server 2 .设置root密码,ubuntu默认root密码是随机的,需要重置一下 sudo pa ...
- PHP 执行系统外部命令的方法 system() exec()
PHP作为一种服务器端的脚本语言,像编写简单.或者是复杂的动态网页这样的任务,它完全能够胜任.但事情不总是如此,有时为了实现某个功能,必须借助于操作系统的外部程序(或者称之为命令),这样可以做到事半功 ...
- SpringMVC 的初理解
项目中用到了jetty,springboot两种构建服务器的方式,jetty是一种嵌入式的方式,部署启动都很灵活,springboot最大的优点就是很多配置文件都自己集成好了,虽然用了这么多好的框架, ...
- js中一切都是对象
<script> function cat(){} var cat = new cat(); console.log(cat.constructor) console.log(typeof ...
- Ubuntu14.04安装libusb
https://www.cnblogs.com/ettie999/p/8142973.html libuvc是一个跨平台的USB视频设备库,建立在libusb之上. 它能够对导出标准USB视频类(UV ...
- 世界最大BT服务器本周死了三回 海盗湾要凉凉?
想當初,我是受到BT網站海盜灣的啟發,開發了一個DHT下載網站:http://www.ibmid.com,有一段時間通宵編程,理解此個協議. 海盗湾(The Pirate Bay)是世界上最大的 BT ...