Python学习笔记 - day12 - Python操作NoSQL
NoSQL(非关系型数据库)
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。redis、memcached是典型的并且使用比较多的NoSQL之一。
NoSQL之Redis
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。 Redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Python,Ruby,Erlang,PHP客户端,使用很方便,并且Redis还支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。
redis模块
redis提供了对Python的支持,Python利用redis模块对Redis数据库进行操作。
安装redis模块
pip命令是Python提供的非常好用的包管理工具,在2.7+以上的版本默认安装,这里使用pip命令安装模块
pip install redis
安装完毕后可以在解释器中输入 import redis 进行测试,如果没有报错,则表示安装成功
连接redis
redis模块提供两个类:Redis和StrictRedis,用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis模块,但Redis的部分语法参数顺序和实际使用redis-cli操作时是不同的,官方建议使用StricRedis来连接数据库,其用法和Redis实例化的对象大部分时相同的,这里使用Redis类来完成相关举例操作,生产上可以使用StrictRedis来实例化redis对象。
import redis redis_obj = redis.Redis(host='10.0.0.3',port='6379',db=0)
redis_obj.set('name','daxin')
print(redis_obj.get('name')) # 利用redis.Redis实例化一个redis数据库,host表示地址,port表示端口,db表示数据库
# set 表示设置一个key,name表示key的名称,daxin表示对应的值
# get 表示获取一个key的值
链接池
Redis对象使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
import redis pool = redis.ConnectionPool(host='10.0.0.3',port='6379',db=0)
r = redis.Redis(connection_pool=pool)
r.set('age','18')
print(r.get('age')) # 使用ConnectionPool 创建一个链接池
# 实例化redis对象的时候,把链接池传入即可
管道(pipline)
Redis是一个cs模式的tcp server,使用和http类似的请求响应协议。一个client可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常会阻塞并等待redis服务处理,redis处理完后请求命令后会将结果通过响应报文返回给client。基本的通信过程如下:
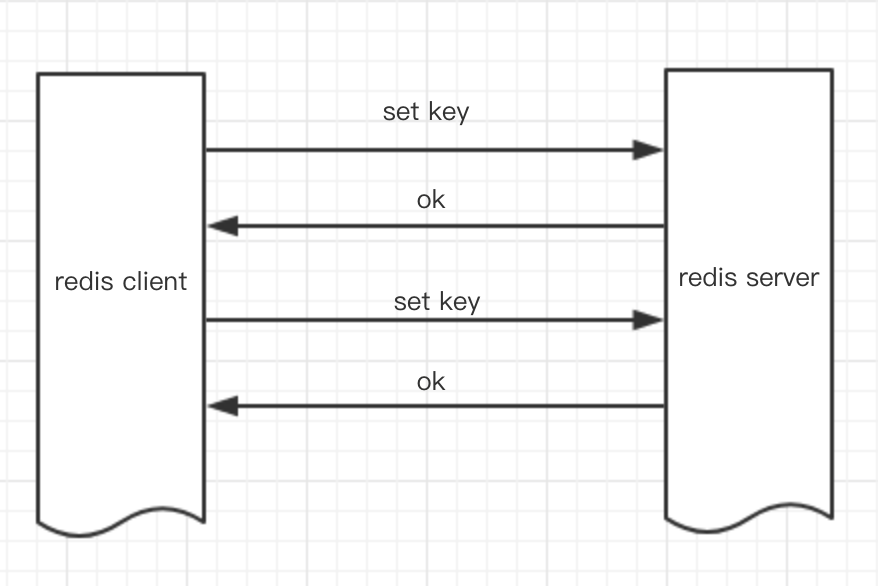
基本上两个命令需要4个tcp报文才能完成。由于通信会有网络延迟,假如从client和server之间的包传输时间需要0.25秒。那么上面的两个命令4个报文至少会需要1秒才能完成。这样即使redis每秒能处理100个命令,而我们的client也只能一秒钟发出两个命令。这显示没有充分利用 redis的处理能力。除了可以利用mget,mset 之类的单条命令处理多个key的命令外我们还可以利用pipeline的方式从client打包多条命令一起发出,不需要等待单条命令的响应返回,而redis服务端会处理完多条命令后会将多条命令的处理结果打包到一起返回给客户端。
import redis pool = redis.ConnectionPool(host='10.0.0.3',port='6379',db=0)
r = redis.Redis(connection_pool=pool) pipline = r.pipeline(transaction=True) pipline.set('hobby','girl')
pipline.set('hobby','girl')
pipline.set('hobby','girl')
pipline.set('hobby','girl')
pipline.set('hobby','girl') pipline.execute() # 利用redis对象的pipline创建pipline对象
# 利用pipeline对象执行set命令
# 利用pipline对象的execute函数批量执行
理解:pipline对象就是一个容器,我们把要执行的语句放入其中,调用其excute函数去批量执行。
注意:在get请求的时候,执行pipe.exceute(),会批量返回,但是是有序的,我们可以定义多个变量去接受
import redis pool = redis.ConnectionPool(host='10.0.0.3',port='',db=0)
r = redis.Redis(connection_pool=pool) pipline = r.pipeline(transaction=True) pipline.get('name')
pipline.get('age')
pipline.get('job')
pipline.get('hobby') name,age,job,hobby = pipline.execute() # 定义4个变量接受 print(name,age,job,hobby)
pipline批量get请求
redis数据类型及操作
redis执行的数据类型众多,但常用的比如string,list,set等,这里我们将列举不同类型的相关操作
String
1、set 设置值,不存在创建,存在则更新。
import redis pool = redis.ConnectionPool(host='10.0.0.3',port='6379',db=0)
r = redis.Redis(connection_pool=pool)
r.set(name, value, ex=None, px=None, nx=False, xx=False) # name 表示key的名称
# value 表示对应的值
# ex 过期时间(秒)
# px 过期时间(毫秒)
# nx 如果设置为True,则只有name不存在时,当前set操作才执行,同setnx(name, value)
# xx 如果设置为True,则只有name存在时,当前set操作才执行
PS:针对过期时间还可以用另外两个函数进行单独调整
setex(name, value, time) #设置过期时间(秒)
psetex(name, time_ms, value) #设置过期时间(豪秒)
2、mset 批量设置值,是set的升级款
r.mset(name='daxin', age='18')
r.mset({"name":'daxin', "age":'18'}) # mset接受 *args和 **kwargs。
# 所以只能传递dict 或者 命名关键词参数,否则会报RedisError异常
3、get/mget 获取/批量获取key值
r.get(name)
r.mget(name1,name2) # get函数只有一个参数:key名称
# mget可以列举多个key名称,或者传递一个list li = ['name','age']
print(r.mget(li))
4、getset 设置新值,打印原值
r.getset(name,value)
print(r.getset('name','dachenzi'))
# 打印name的值,并设置其的值为dachenzi
5、getrange 字符串的截取(类似字符串的切片)
r.getrange(name,start,end) # key 起始位置 结束位置
r.set('name','dachenzi')
print(r.getrange('name',2,5))
# 则会打印 chen
6、setrange(name, offset, value) 字符串的分片替换
# r.setrange(name,offset,value) # key,偏移位置(起始位置), 要替换的字符串
#修改字符串内容,从指定字符串索引开始向后替换,如果新值太长时,则向后添加 r.set('name','dachenzi')
r.setrange('name',5,'a')
print(r.get('name')) # 打印dacheazi
7、strlen 统计字符串的字节长度
# r.strlen(name)
r.set('name','dachenzi')
print(r.strlen('name')) # 打印8
# 注意:一个汉字占用3个字节
8、incr/decr 自增/自减对应的值(整型)
# r.incr(name,amount) amount默认值为1
# 自增mount对应的值,当mount不存在时,则创建mount=amount,否则,则自增,amount为自增数(整数,也可以理解为步长) print(r.incr("mount",amount=2)) #输出:2
print(r.incr("mount")) #输出:3
print(r.incr("mount",amount=3)) #输出:6
print(r.incr("mount",amount=6)) #输出:12
print(r.get("mount")) #输出:12 # r.decr(name,amount) amount默认值为1
# 自减name对应的值,当name不存在时,则创建name=amount,否则,则自减,amount为自增数(整数)
9、append 在对应的key后面进行追加
# r.append(name,value) 在 name的对应的值后面追加value
# name存在会追加,不存在会创建 r.set('name','daxin')
r.append('name',' hello world')
print(r.get('name)) # 打印: 'daxin hello world'
List
1、lpush(name,values) 向list中添加元素,FIFO模式(先进先出)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
r.lpush("daxin_list",2)
r.lpush("daxin_list",3,4,5) print(r.lrange('daxin_list',0,-1)) 保存在列表中的顺序为5,4,3,2
2、rpush(name,values) 向list中添加元素,栈模式(先进后出)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最右边
r.rpush("daxin_list2",2)
r.rpush("daxin_list2",3,4,5) print(r.lrange('daxin_list2',0,-1)) # 2,3,4,5
3、lpushx(name,value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
4、rpushx(name,value) 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最右边
5、llen(name) 获取name对应的list元素的个数
print(r.llen("daxin_list"))
6、linsert(name, where, refvalue, value)) 插入元素
# 在name对应的列表的某一个值前或后插入一个新值
r.linsert("daxin_list","BEFORE","2","SS")#在列表内找到第一个元素2,在它前面插入SS # 参数:
# name: redis的name
# where: BEFORE(前)或AFTER(后)
# refvalue: 列表内的值
# value: 要插入的数据
7、lset(name, index, value) 对list中的某一个索引位置重新赋值
r.lset("daxin_list",0,"bbb")
8、lrem(name, value, count) 删除name对应的list中的指定值
r.lrem(name,value,count) # 参数:
# name: redis的name
# value: 要删除的值
# count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT 。
# count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT 的绝对值。
# count = 0 : 移除表中所有与 VALUE 相等的值。
9、lpop(name) 移除列表的左侧第一个元素,返回值则是第一个元素
print(r.lpop("daxin_list"))
10、lindex(name, index) 根据索引获取列表内元素
print(r.lindex("daxin_list",1))
11、lrange(name, start, end) 分片获取元素
print(r.lrange("daxin_list",0,-1))
# 0 表示 其实位置,-1表示末尾
# 所以 0,-1 就表示列表的所有
12、ltrim(name, start, end) 移除列表内没有在该索引之内的值
r.lrange('daxin_list') # 2,3,4,5
r.ltrim("daxin_list",0,2) # 会删除 5
13、rpoplpush(src, dst) 从src取出最右边的元素,同时将其添加至dst的最左边
r.lpush('dachenzi_list',1,2,3,4,5)
r.lpush('dachenzi_list2',5,4,3,2,1)
r.rpoplpush('dachenzi_list','dachenzi_list2')
# dachenzi_list: 2,3,4,5
# dachenzi_list2: 1,1,2,3,4,5
14、brpoplpush(src, dst, timeout=0)
#同rpoplpush,多了个timeout, timeout:取数据的列表没元素后的阻塞时间,0为一直阻塞
r.brpoplpush("dachenzi_list","dachezi_list2",timeout=0)
15、blpop(keys, timeout)
#将多个列表排列,按照从左到右去移除各个列表内的元素
r.lpush("dachenzi_list",3,4,5)
r.lpush("dachenzi_list2",3,4,5) while True:
print(r.blpop(["dachenzi_list","dachenzi_list2"],timeout=0))
print(r.lrange("dachenzi_list",0,-1),r.lrange("dachenzi_list2",0,-1))
# 先挨个删除dachenzi_list,然后再挨个删除dachenzi_list2。 # r.blpop(keys,timout)
# 参数:
# keys: redis的name的集合
# timeout: 超时时间,获取完所有列表的元素之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞'''
16、brpop(keys, timeout) 同blpop,将多个列表排列,按照从右像左去移除各个列表内的元素
set之无序集合
Set集合就是不允许重复的列表,在redis中,集合分为无序和有序,set表示无序集合,sortes set表示有序集合。
1、sadd(name,values) 给name对应的集合中添加元素
r.sadd('daxin_set1',1,2,3,4,5)
r.sadd('daxin_set1',1,2,3,4,5,6,7)
print(r.smembers('daxin_set1'))
2、smembers(name) 获取name对应的集合的所有成员
3、scard(name) 获取name对应的集合中的元素个数
r.sadd('daxin_set',1,2,3,4,5)
r.sadd('daxin_set',1,2,3,4,5,6,7)
print(r.scard('daxin_set')) # 打印7个
4、sdiff(keys, *args) 在第一个name对应的集合中且不在其他name对应的集合的元素集合(第一个set和其他set的差集)
r.sadd('daxin_set',1,2,3)
r.sadd('daxin_set2',2)
r.sadd('daxin_set3',3)
print(r.sdiff('daxin_set','daxin_set2','daxin_set3')) # 打印1
5、sdiffstore(dest, keys, *args) 相当于把sdiff获取的值加入到dest对应的集合中
r.sadd('daxin_set',1,2,3)
r.sadd('daxin_set2',2)
r.sadd('daxin_set3',3)
r.sdiffstore('daxin_set4','daxin_set','daxin_set2','daxin_set3')
print(r.smembers('daxin_set4')) # 打印1
6、sinter(keys, *args) 获取同时存在指定集合中的元素
r.sadd('daxin_set',1,2,3)
r.sadd('daxin_set2',2,1)
r.sadd('daxin_set3',3,1)
print(r.sinter('daxin_set','daxin_set2','daxin_set3')) # 打印1
7、sinterstore(dest, keys, *args) 获取多个name对应集合的并集,再讲其加入到dest对应的集合中
8、sismember(name, value) 检查value是否是name对应的集合内的元素
r.sadd('daxin_set','a','b','c')
print(r.sismember('daxin_set','c')) # true
print(r.sismember('daxin_set','d')) # false
9、smove(src, dst, value) 将某个元素从一个集合中移动到另外一个集合
r.sadd('daxin_set','a','b','c')
r.sadd('daxin_set2',1,2)
r.smove('daxin_set','daxin_set2','c')
print(r.smembers('daxin_set2')) # 打印1,2,c
10、spop(name) 从集合的右侧移除一个元素,并将其返回
11、srandmember(name, numbers) 从name对应的集合中随机获取numbers个元素
r.sadd('daxin_set','a','b','c','d','e','f','g')
print(r.srandmember('daxin_set',2)) # 随机取两个,每次都不同
12、srem(name, values) 删除name对应的集合中的某些值
r.sadd('daxin_set','a','b','c','d','e','f','g')
print(r.srem('daxin_set','a','b','z')) # 返回实际删除的members个数,这里返回2
print(r.smembers('daxin_set'))
13、sunion(keys, *args) 获取多个name对应的集合的并集
r.sadd('daxin_set','a','b')
r.sadd('daxin_set1','c','d')
r.sadd('daxin_set2','e','f','g')
print(r.sunion('daxin_set','daxin_set2','daxin_set1'))
# 打印 {b'c', b'a', b'f', b'e', b'g', b'd', b'b'}
14、sunionstore(dest,keys, *args) 获取多个name对应的集合的并集,并将结果保存到dest对应的集合中
set之有序集合
在集合的基础上,为每元素排序,元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数(可以理解为index,索引),分数专门用来做排序。
1、zadd(name, *args, **kwargs) 在name对应的有序集合中添加元素
# r.zadd(name,value,score...)
r.zadd('daxin_set','name',1,'age',2,'job',3)
print(r.zrange('daxin_set',0,-1)) # 打印 [b'name', b'age', b'job']
2、zcard(name) 获取有序集合内元素的数量
3、zcount(name, min, max) 获取有序集合中分数在[min,max]之间的个数
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zcount('daxin_set',1,2)) # 打印1
print(r.zcount('daxin_set',1,3)) # 打印2
4、zincrby(name, value, amount) 自增有序集合内value对应的分数
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zrange('daxin_set',0,-1)) # 顺序是 [b'name', b'job', b'age']
r.zincrby('daxin_set','name',amount=7) # 改变了name的score,影响排序
print(r.zrange('daxin_set',0,-1)) # 顺序是 [b'job', b'age', b'name']
5、zrange( name, start, end, desc=False, withscores=False, score_cast_func=float) 按照索引范围获取name对应的有序集合的元素
r.zrange("name",start,end,desc=False,withscores=True,score_cast_func=int)
# 参数:
# name redis的name
# start 有序集合索引起始位置
# end 有序集合索引结束位置
# desc 排序规则,默认按照分数从小到大排序
# withscores 是否获取元素的分数,默认只获取元素的值
# score_cast_func 对分数进行数据转换的函数
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zrange('daxin_set',0,1,withscores=True))
6、zrevrange(name, start, end, withscores=False, score_cast_func=float) 同zrange,集合是从大到小排序的
7、zrank(name, value)、zrevrank(name, value) 获取value值在name对应的有序集合中的排行位置(从0开始)
# zrank(name,value) # 正序(从左边开始)
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zrank('daxin_set','job')) # 打印2 # zrevrank(name,value) # 倒序(从右边开始)
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zrevrank('daxin_set','age')) # 打印0
8、zscore(name, value) 获取name对应有序集合中 value 对应的分数
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zscore('daxin_set','age')) # 打印 6.0
9、zrem(name, values) 删除name对应的有序集合中值是values的成员
r.zadd('daxin_set','name',1,'age',6,'job',3)
r.zrem('daxin_set','name','age')
print(r.zrange('daxin_set',0,-1)) # 打印 'job'
10、zremrangebyrank(name, min, max) 根据排行范围删除
r.zadd('daxin_set','name',1,'age',6,'job',3)
print(r.zrange('daxin_set',0,-1,withscores=True))
r.zremrangebyrank('daxin_set',0,1) # 按照排序后的索引进行删除,0对应第一个元素,就是name,1对应第二个元素就是job
print(r.zrange('daxin_set',0,-1)) # 打印 age
11、zremrangebyscore(name, min, max) 根据分数范围删除
hash
redis中的Hash 在内存中类似于一个name对应一个dic来存储
1、hset(name, key, value) name对应的hash中设置一个键值对(不存在,则创建,否则,修改)
r.hset('dachenzi_hash','name','daxin')
print(r.hget('dachenzi_hash','name'))
2、hget(name,key) 在name对应的hash中根据key获取value
r.hset('dachenzi_hash','name','daxin')
print(r.hget('dachenzi_hash','name'))
3、hgetall(name) 获取name对应hash的所有键值
r.hset('dachenzi_hash','name','daxin')
r.hset('dachenzi_hash','nage',18)
print(r.hgetall('dachenzi_hash'))
3、hmset(name, mapping) 在name对应的hash中批量设置键值对,mapping:字典
dic = {'name':'daxin','age':18}
r.hmset('dachenzi_hash',dic)
print(r.hgetall('dachenzi_hash'))
4、hmget(name, keys, *args) 在name对应的hash中获取多个key的值
dic = {'name':'daxin','age':18}
r.hmset('dachenzi_hash',dic)
print(r.hmget('dachenzi_hash','name','age'))
# 支持传递list类型
li = ['name','age']
print(r.hmget('dachenzi_hash',li))
5、hlen(name) 获取hash中键值对的个数,hkeys(name) 获取hash中所有的key的值,hvals(name) 获取hash中所有的value的值
dic = {'name':'daxin','age':18,'job':'Linux','Like':'python'}
r.hmset('dachenzi_hash',dic)
print(r.hlen('dachenzi_hash')) # 4
print(r.hkeys('dachenzi_hash')) # [b'name', b'age', b'job', b'Like']
print(r.hvals('dachenzi_hash')) # [b'daxin', b'18', b'Linux', b'python']
6、hexists(name, key) 检查name对应的hash是否存在当前传入的key
dic = {'name':'daxin','age':18,'job':'Linux','Like':'python'}
r.hmset('dachenzi_hash',dic)
print(r.hexists('dachenzi_hash','name')) # True
7、hdel(name,*keys) 删除指定name对应的key所在的键值对
dic = {'name':'daxin','age':18,'job':'Linux','Like':'python'}
r.hmset('dachenzi_hash',dic)
r.hdel('dachenzi_hash','name')
print(r.hgetall('dachenzi_hash'))
8、hincrby(name, key, amount=1) 自增hash中key对应的值,不存在则创建key=amount(amount为整数)
dic = {'name':'daxin','age':18,'job':'Linux','Like':'python'}
r.hmset('dachenzi_hash',dic)
r.hincrby('dachenzi_hash','age',amount=100)
print(r.hgetall('dachenzi_hash'))
9、hincrbyfloat(name, key, amount=1.0) 自增hash中key对应的值,不存在则创建key=amount(amount为浮点数)
其他常用操作
1、delete(*names) 根据name删除redis中的任意数据类型
r.set('name_str','daxin') # str
r.sadd('name_set','daxin') # set
r.lpush('name_list','daxin') # list
r.zadd('name_sorted','daxin',1) # sorted set
print(r.keys())
r.delete('name_str','name_set','name_list','name_sorted')
print(r.keys())
2、exists(name) 检测redis的name是否存在
3、keys(pattern='*') 根据* ?等通配符匹配获取redis的name
r.set('name_str','daxin') # str
r.sadd('name_set','daxin') # set
r.lpush('name_list','daxin') # list
r.zadd('name_sorted','daxin',1) # sorted set
print(r.keys('name_sor*')) # 仅仅支持通配符
4、expire(name ,time) 为某个name设置超时时间
5、rename(src, dst) 重命名
6、move(name, db)) 将redis的某个值移动到指定的db下
7、randomkey() 随机获取一个redis的name(不删除)
8、type(name) 获取name对应值的类型
r.set('name_str','daxin') # str
r.sadd('name_set','daxin') # set
r.lpush('name_list','daxin') # list
r.zadd('name_sorted','daxin',1) # sorted set
print(r.type('name_str'))
print(r.type('name_set'))
print(r.type('name_list'))
print(r.type('name_sorted'))
NoSQL之Memcached
Memcached是一个高性能的分布式内存对象缓存系统,用于动态WEB应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态,数据库网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon)是用C写的,但是客户端可以用任何语言来编程,并通过memcached协议与守护进程通信。
安装Memcached
在Linux下主要有两种安装方式,即:yum安装,源码编译安装。这里仅使用yum进行memcached的安装
使用root用户,执行如下命令即可安装完毕
yum install memcached
启动Memcached
memcached非常轻量级,在安装完毕后,连启动脚本都没有,使用命令直接进行启动即可
memcached -d -m 10 -u root -l 0.0.0.0 -p 12000 -c 256 -P /tmp/memcached.pid # 参数说明:
# -d 是启动一个守护进程(使用守护进程模式)
# -m 是分配给Memcache使用的内存数量,单位是MB(默认手64M)
# -u 是运行Memcache的用户
# -l 是监听的服务器IP地址
# -p 是设置Memcache监听的端口,最好是1024以上的端口(一般是11211)
# -c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定
# -P 是设置保存Memcache的pid文件
PS:指定不同的端口启动,即可完成多实例的部署。
Python操作memcached
Python想要操作Memcached,首先需要安装工具模块
# python 2
pip install python-memcached # python3
pip3 install python3-memcached
基本操作:
import memcache
mc = memcache.Client(['10.0.0.3:11211'],debug=True) # 实例化一个memcache.Client类,列表为memcached服务器的地址及端口
mc.set('name','daxin') #设置key
name = mc.get('name') # 获取key
print(name)
集群模式
python3-memcached模块原生支持集群操作,其原理是在内存中维护一个主机列表,且集群中主机的权重值和主机在列表中重复出现的次数成正比。
| IP | 权重值 | |
| 节点1 | 10.0.0.3 | 1 |
| 节点2 | 10.0.0.5 | 2 |
| 节点3 | 10.0.0.6 | 1 |
那么内存中主机列表为:host_list = ["10.0.0.3", "10.0.0.5","10.0.0.5","10.0.0.6"]
用户如果要在内存中创建一个键值对(如:k1 = "value1"),那么要执行以下步骤:
- 根据算法将k1转换成一个数字
- 将数字和主机列表长度求余数,得到一个值N(0 <= N < 长度)
- 在主机列表中根据第二步得到的值为索引获取主机,例如: host_list[N]
- 连接将第三步中获取的主机,将k1 = "value1" 放置在该服务器的内存中
代码如下:
这里使用多实例模拟多台独立的主机
import memcache
mc = memcache.Client([('10.0.0.3:11211',1),('10.0.0.3:11212',2),('10.0.0.3:11213',1)],debug=True) # 配置多个节点的memcached集群
mc.set('name','daxin') # 和单节点添加数据相同
name = mc.get('name')
print(name)
mc1 = memcache.Client(['10.0.0.3:11212'],debug=True) # 数据存放到了节点1上
name1 = mc1.get('name') # 这里连接节点2,会获取不到数据
print(name1)
memcached操作
1、add 添加一条键值对,如果已经存在的key,重复执行add操作会出现异常。
import memcache
mc = memcache.Client(['10.0.0.3:11211'],debug=True)
mc.add('name','daxin')
mc.add('name','dachenzi') # 重复添加name,那么会警告提示
PS:MemCached: while expecting 'b'STORED'', got unexpected response 'b'NOT_STORED''
2、replace 修改某个key的值,如果key不存在,则get时会返回None
mc = memcache.Client(['10.0.0.3:11211'],debug=True)
mc.add('name','daxin')
print(mc.get('name'))
mc.replace('name','dachenzi') # 修改name的值
print(mc.get('name'))
mc.replace('name123','daxin') # 修改一个不存在的name123的值
print(mc.get('name123')) # 获取会返回None
3、set 和 set_multi
set : 设置一个键值对,如果Key不存在,则创建,如果key存在,则修改。
set_multi : 设置多个键值对,如果key不存在,则创建,如果key存在,则修改。
import memcache
mc = memcache.Client(['10.0.0.3:11211'],debug=True) print(mc.get('name'))
mc.set('name','daxin') #存在就替换,不存在就新增
print(mc.get('name')) dic = {'name':'dachenzi','age':18,'job':'Linux'}
mc.set_multi(dic) # 单次设置多个key,存在即更新 print(mc.get('name'))
print(mc.get('age'))
print(mc.get('job'))
4、delete 和 delete_multi
delete : 在Memcached中删除指定的一个键值对,不存在也不会报错。
delete_multi : 在Memcached中删除指定多个键值对。
import memcache
mc = memcache.Client(['10.0.0.3:11211'],debug=True) mc.delete('name234234') #随便写的key,不会异常
mc.delete('name2342131') # mc.delete_multi(['key1', 'key2']) 后面指定多个key列表即可
5、get 和 get_multi
get : 获取一个键值对。
get_multi : 获取多个键值对。
import memcache mc = memcache.Client(['10.0.0.3:11211'],debug=True)
mc.set('name','daxin')
mc.set('age',18)
mc.set_multi({'job':'Linux','Like':'Python'}) print(mc.get('name'))
print(mc.get_multi(['age','job','Like']))
6、append 和 prepend
append : 修改指定key的值,在该值后面追加内容。
prepend : 修改指定key的值,在该值前面插入内容。
import memcache
mc = memcache.Client(['10.0.0.3:11211'],debug=True)
print(mc.get('name')) # 'daxin'
mc.append('name','nihao')
print(mc.get('name')) # 'daxinnihao'
mc.prepend('name','wojiao')
print(mc.get('name')) # wojiaodaxinnihao
7、decr 和 incr
decr : 自减,将Memcached中的一个值增加N(N默认为1)
incr : 自增,将Memcached中的一个值减少N(N默认为1)
import memcache mc = memcache.Client(['10.0.0.3:11211'],debug=True)
mc.set('age',1) mc.incr('age',2) # 自增2
print(mc.get('age')) # 打印3 mc.decr('age') # 自减1
print(mc.get('age')) # 打印2
8、gets 和 cas
使用缓存系统共享数据资源就必然绕不开数据争夺和脏数据(数据混乱)的问题,比如两个业务同时操作一个key。获取的时候value相同,同时修改的话必然会出现数据混乱。如果想要避免这种情况的发生,则可以使用 gets 和 cas。
本质上每次执行gets时,会从memcache中获取一个自增的数字,通过cas去修改gets的值时,会携带之前获取的自增和memcache中的自增值进行比较,如果相等,则可以提交,如果不相等,那么表示在gets和cas执行之间,又有其他人执行了gets,则不允许修改。
备注:实验没有成功,不知道为啥,后续补充例子。
Python学习笔记 - day12 - Python操作NoSQL的更多相关文章
- python 学习笔记 9 -- Python强大的自省简析
1. 什么是自省? 自省就是自我评价.自我反省.自我批评.自我调控和自我教育,是孔子提出的一种自我道德修养的方法.他说:“见贤思齐焉,见不贤而内自省也.”(<论语·里仁>)当然,我们今天不 ...
- python学习笔记(python简史)
一.python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum) 目前python主要应用领域: ·云计算 ·WEB开发 ·科学运算.人工智能 ·系统运维 ·金融:量化交 ...
- python学习笔记:python字符串
二.python字符串操作符 1. 对象标准类型操作符 Python对象的标准类型操作符一共就三种:对象值的比较.对象身份的比较.布尔类型.其中对象值的比较主要是大于.小于.不等于等的数学比较符:对象 ...
- python 学习笔记一——Python安装和IDLE使用
好吧,一直准备学点啥,前些日子也下好了一些python电子书,但之后又没影了.年龄大了,就是不爱学习了.那就现在开始吧. 安装python 3 Mac OS X会预装python 2,Linux的大多 ...
- python学习笔记(一):python简介和入门
最近重新开始学习python,之前也自学过一段时间python,对python还算有点了解,本次重新认识python,也算当写一个小小的教程.一.什么是python?python是一种面向对象.解释型 ...
- Python 学习笔记:Python 连接 SQL Server 报错(20009, b'DB-Lib error message 20009, severity 9)
问题及场景: 最近需要使用 Python 将数据写到 SQL Server 数据库,但是在进行数据库连接操作时却报以下错误:(20009, b'DB-Lib error message 20009, ...
- 吴裕雄--天生自然python学习笔记:python 用pygame模块处理音频文件
除了对图片. Word 等普通格式的文件进行处理外, Python 还有强大的多媒体文件操作能力,如对音频.视频 文件的操作 . 如果要播放音乐,我们可以用 pygame 包中的 mixer 对 象. ...
- python学习笔记(1)--python特点
python诞生于复杂的信息系统时代,是计算机时代演进的一种选择. python的特点,通用语言,脚本语言,跨平台语言.这门语言可以用于普适的计算,不局限于某一类应用,通用性是它的最大特点.pytho ...
- python学习笔记之——python模块
1.python模块 Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. 模块让你能够有逻辑地组织你的 Python ...
随机推荐
- AndroidStudio3.0 注解报错Annotation processors must be explicitly declared now. The following dependencies on the compile classpath are found to contain annotation processor.
把Androidstudio2.2的项目放到3.0里面去了,然后开始报错了. 体验最新版AndroidStudio3.0 Canary 8的时候,发现之前项目的butter knife报错,用到注解的 ...
- [剑指Offer] 44.翻转单词顺序列
题目描述 牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上.同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但却读不懂它的意思.例如,“student ...
- 【bzoj4196】[Noi2015]软件包管理器 树链剖分+线段树
题目描述 Linux用户和OSX用户一定对软件包管理器不会陌生.通过软件包管理器,你可以通过一行命令安装某一个软件包,然后软件包管理器会帮助你从软件源下载软件包,同时自动解决所有的依赖(即下载安装这个 ...
- Luogu1092 NOIP2004虫食算(搜索+高斯消元)
暴力枚举每一位是否进位,然后就可以高斯消元解出方程了.然而复杂度是O(2nn3),相当不靠谱. 考虑优化.注意到某一位进位情况的变化只会影响到方程的常数项,于是可以在最开始做一次高斯消元算出每个未知数 ...
- P2613 【模板】有理数取余
题目描述 给出一个有理数 $c=\frac{a}{b}$ ,求 c mod 19260817 的值. 输入输出格式 输入格式: 一共两行. 第一行,一个整数 aa .第二行,一个整数 bb . 输出格 ...
- POJ2728:Desert King——题解
http://poj.org/problem?id=2728 题目大意:求一棵生成树使得路费用和/路长之和最小(路的费用是两端点的高度差) 最小比率生成树. 我们还是01分数规划的思想将边权变为路费用 ...
- ZOJ3229:Shoot the Bullet——题解
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3229 题目大意:射命丸文要给幻想乡的居民照相,共照n天m个人,每天射命丸文 ...
- bzoj4773: 负环(倍增floyd)
浴谷夏令营例题...讲师讲的很清楚,没看题解代码就自己敲出来了 f[l][i][j]表示i到j走2^l条边的最短距离,显然有f[l][i][j]=min(f[l][i][j],f[l-1][i][k] ...
- 2017-7-18-每日博客-关于Linux下的history的常用命令.doc
History history命令可以用来显示曾执行过的命令.执行过的命令默认存储在HOME目录中的.bash_history文件中,可以通过查看该文件来获取执行命令的历史记录.需要注意的是.bash ...
- Codeforces Round #341 (Div. 2)B
B. Wet Shark and Bishops time limit per test 2 seconds memory limit per test 256 megabytes input sta ...