无偏方差为什么除以n-1
设样本均值为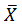
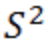 ,总体均值为
,总体均值为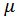
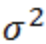 ,那么样本方差
,那么样本方差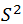
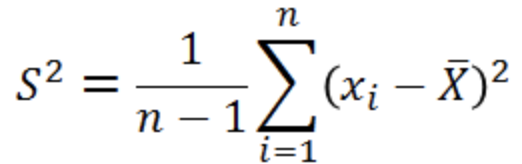
很多人可能都会有疑问,为什么要除以n-1,而不是n,但是翻阅资料,发现很多都是交代到,如果除以n,对样本方差的估计不是无偏估计,比总体方差要小,要想是无偏估计就要调小分母,所以除以n-1,那么问题来了,为什么不是除以n-2、n-3等等。所以在这里彻底总结一下,首先交代一下无偏估计。
无偏估计
以例子来说明,假如你想知道一所大学里学生的平均身高是多少,一个大学好几万人,全部统计有点不现实,但是你可以先随机挑选100个人,统计他们的身高,然后计算出他们的平均值,记为 。如果你只是把作为整体的身高平均值,误差肯定很大,因为你再随机挑选出100个人,身高平均值很可能就跟刚才计算的不同,为了使得统计结果更加精确,你需要多抽取几次,然后分别计算出他们的平均值,分别记为:
。如果你只是把作为整体的身高平均值,误差肯定很大,因为你再随机挑选出100个人,身高平均值很可能就跟刚才计算的不同,为了使得统计结果更加精确,你需要多抽取几次,然后分别计算出他们的平均值,分别记为: 然后在把这些平均值,再做平均,记为:
然后在把这些平均值,再做平均,记为: ,这样的结果肯定比只计算一次更加精确,随着重复抽取的次数增多,这个期望值会越来越接近总体均值
,这样的结果肯定比只计算一次更加精确,随着重复抽取的次数增多,这个期望值会越来越接近总体均值 ,这就是一个无偏估计,其中统计的样本均值也是一个随机变量,
,这就是一个无偏估计,其中统计的样本均值也是一个随机变量,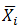
介绍无偏估计的意义就是,我们计算的样本方差,希望它是总体方差的一个无偏估计,那么假如我们的样本方差是如下形式:

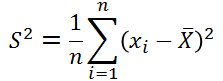
那么,我们根据无偏估计的定义可得:


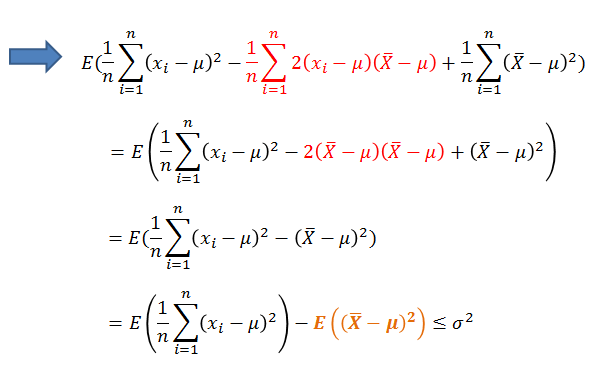
由上式可以看出如果除以n,那么样本方差比总体方差的值偏小,那么该怎么修正,使得样本方差式总体方差的无偏估计呢?我们接着上式继续化简:

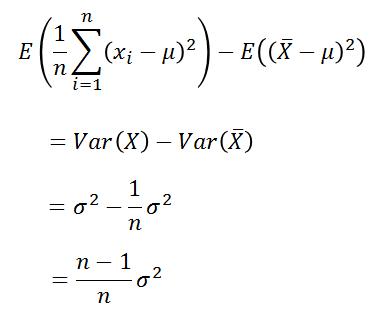
到这里得到如下式子,看到了什么?该怎修正似乎有点眉目。

如果让我们假设的样本方差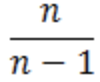
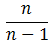
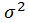

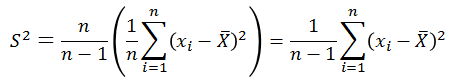
则:
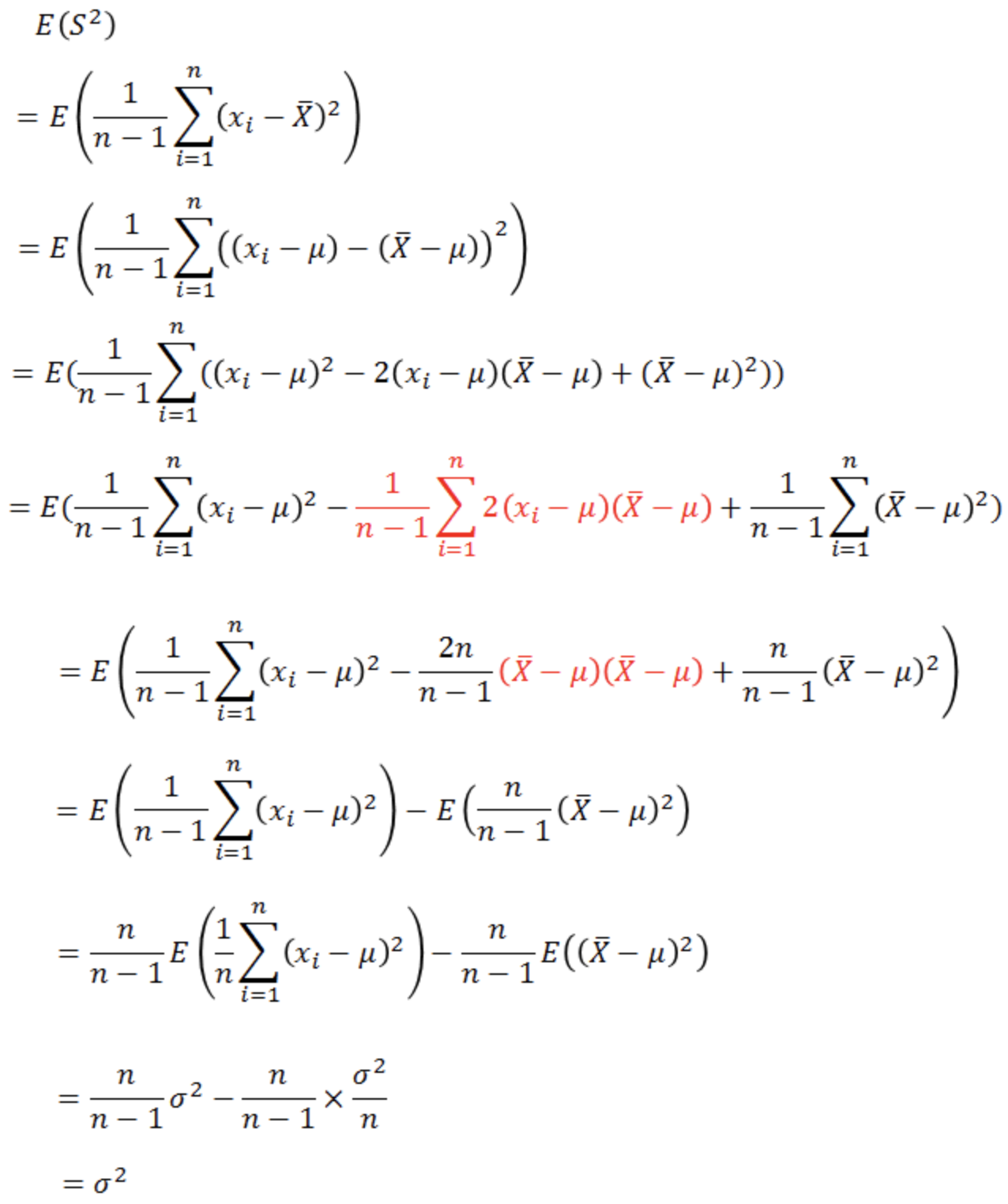
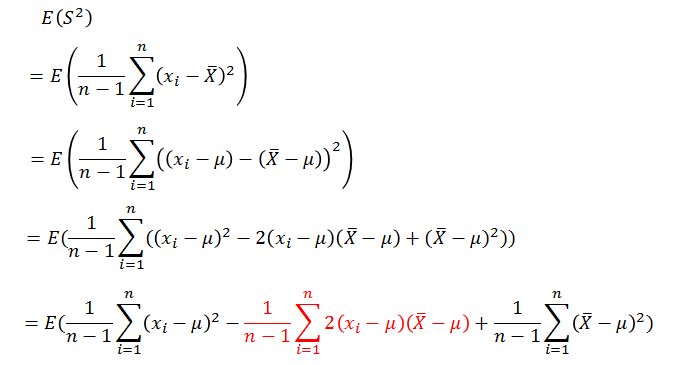
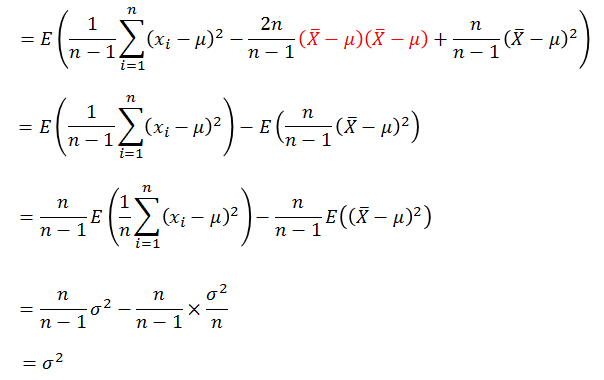
因此修正之后的样本方差的期望是总体方差
https://blog.csdn.net/hearthougan/article/details/77859173
无偏方差为什么除以n-1的更多相关文章
- 方差(variance)、标准差(Standard Deviation)、均方差、均方根值(RMS)、均方误差(MSE)、均方根误差(RMSE)
方差(variance).标准差(Standard Deviation).均方差.均方根值(RMS).均方误差(MSE).均方根误差(RMSE) 2017年10月08日 11:18:54 cqfdcw ...
- 【原创】开源Math.NET基础数学类库使用(10)C#进行基本数据统计
本博客所有文章分类的总目录:[总目录]本博客博文总目录-实时更新 开源Math.NET基础数学类库使用总目录:[目录]开源Math.NET基础数学类库使用总目录 前言 ...
- RapidJSON 代码剖析(四):优化 Grisu
我曾经在知乎的一个答案里谈及到 V8 引擎里实现了 Grisu 算法,我先引用该文的内容简单介绍 Grisu.然后,再谈及 RapidJSON 对它做了的几个底层优化. (配图中的<Grisù& ...
- 开源Math.NET基础数学类库使用(10)C#进行基本数据统计
原文:[原创]开源Math.NET基础数学类库使用(10)C#进行基本数据统计 本博客所有文章分类的总目录:http://www.cnblogs.com/asxinyu/p ...
- 【XSY2843】「地底蔷薇」 NTT什么的 扩展拉格朗日反演
题目大意 给定集合\(S\),请你求出\(n\)个点的"所有极大点双连通分量的大小都在\(S\)内"的不同简单无向连通图的个数对\(998244353\)取模的结果. \(n\le ...
- Pandas系列(七)-计算工具介绍
内容目录 1. 统计函数 2. 窗口函数 3. 加深加强 数据准备 # 导入相关库 import numpy as np import pandas as pd #Pandas 中包含了非常丰富的计算 ...
- 深度学习框架PyTorch一书的学习-第四章-神经网络工具箱nn
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 本章介绍的nn模块是构建与autogr ...
- Spark SQL 函数全集
org.apache.spark.sql.functions是一个Object,提供了约两百多个函数. 大部分函数与Hive的差不多. 除UDF函数,均可在spark-sql中直接使用. 经过impo ...
- GoogLeNetv2 论文研读笔记
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 原文链接 摘要 ...
随机推荐
- Oracle 查找带有CLOB字段的所有表
查找带有CLOB字段的以HEHE开头的所有表 select t.column_name ,DATA_TYPE,TABLE_NAMEfrom user_tab_columns twhere t.TABL ...
- bzoj 2111: [ZJOI2010]Perm 排列计数 (dp+卢卡斯定理)
bzoj 2111: [ZJOI2010]Perm 排列计数 1 ≤ N ≤ 10^6, P≤ 10^9 题意:求1~N的排列有多少种小根堆 1: #include<cstdio> 2: ...
- ctrl + alt + o 快速删除掉没有使用的 import
ctrl + alt + o 优化导入,可以快速删除掉没有使用的 import
- 【剑指offer】字符串的组合
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/mmc_maodun/article/details/26405471 转载请注明出处:http:// ...
- luogu P2617 Dynamic Rankings(分块,n <= 1e4)
嘟嘟嘟 带修改区间第k大. 然而某谷把数据扩大到了1e5,所以用分块现在只能得50分. 分块怎么做呢?很暴力的. 基本思想还是块内有序,块外暴力统计. 对于修改,直接重排修改的数所在块,时间复杂度O( ...
- [USACO07DEC]Sightseeing Cows
嘟嘟嘟 这题好像属于01分数规划问题,叫什么最优比率生成环. 题目概括一下,就是求一个环,满足∑v[i] / ∑c[i]最大. 我们可以堆上面的式子变个型:令 x = ∑v[i] / ∑c[i],则x ...
- textarea使换行变顿号
window.onload = function(){ document.getElementById('area').addEventListener('keydown',function(e){ ...
- 【转】关于HTTP中文翻译的讨论
http://www.ituring.com.cn/article/1817 讨论参与者共16位: 图灵谢工 杨博 陈睿杰 贾洪峰 李锟 丁雪丰 郭义 梁涛 吴玺喆 邓聪 胡金埔 臧秀涛 张伸 图钉派 ...
- 三十、详述使用 IntelliJ IDEA 解决 jar 包冲突的问题
在实际的 Maven 项目开发中,由于项目引入的依赖过多,遇到 jar 冲突算是一个很常见的问题了.在本文中,我们就一起来看看,如何使用 IntelliJ IDEA 解决 jar 包冲突的问题!简单粗 ...
- 关于$NOIP2017$的题目讲解
关于\(NOIP2017\)的题目讲解 1.小凯的疑惑 题目描述: 小凯手中有两种面值的金币,两种面值均为正整数且彼此互素.每种金币小凯都有 无数个.在不找零的情况下,仅凭这两种金币,有些物品他是无法 ...