[hadoop][会装]hadoop ha模式安装
1.简介
2.X版本后namenode支持了HA特性,使得整个文件系统的可用性更加增强。
2.安装前提
zookeeper集群,zookeeper的安装参考[hadoop][会装]zookeeper安装
3.资源规划
| xufeng-1 | xufeng-2 | xufeng-3 |
| zookeeper | zookeeper | zookeeper |
|
JournalNode |
JournalNode |
JournalNode |
|
NameNode DFSZKFailoverController |
NameNode DFSZKFailoverController |
|
| datanode | datanode | datenode |
| resourcemanager | resourcemanager | |
| nodemanager | nodemanager | nodemanager |
注意:
实际部署的时候JournalNode应该和namenode进程分开部署,这里由于资源有限暂未分开
4.开始部署
a.目录规划
hadoop安装目录使用软链接的方式,这样有利于后续升级后也不需要去修改其他环境变量等参数
配置文件也和安装包分离,有利于后续升级后配置不需要重新倒腾。
hadoop@xufeng- hadoop]$ ll
总用量
lrwxrwxrwx. hadoop hadoop 7月 : hadoop -> /opt/hadoop/hadooplib/cdh5.4.2/hadoop-2.6.-cdh5.4.2
drwxrwxr-x. hadoop hadoop 7月 : hadoop-config
b.环境变量设定(xufeng-1上修改后同步到其他机器)
#hadoop
export HADOOP_HOME=/opt/hadoop/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-config
export HADOOP_LOG_DIR=/opt/hadoop/hadoop/logs
c.配置文件修改(xufeng-1上修改后同步到其他机器)
首先将软件包中的etc/hadoop下的所有文件拷贝到hadoop-config目录。
修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>--->这里并没有给出具体的那一台主机,因为是两个namenode所以可以将此名称看做为逻辑组合,这个组合后续配置文件中会给出更加详细的描述和定义
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-data/hadoop/temp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>xufeng-:,xufeng-:,xufeng-:</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>------>这里就是core-site.xml中提到的逻辑概念,hdaoop中称之为服务,注意是复数形式,也就是我们如果愿意可以在一个集群中规划处多个服务来
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>-------->描述这个服务有哪些namenode作为管理节点
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>----->描述其中一个namenode的管理节点在哪里
<value>xufeng-:</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>xufeng-:</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>----->描述另外一个namenode的管理节点在哪里?
<value>xufeng-:</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>xufeng-:</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://xufeng-1:8485;xufeng-2:8485;xufeng-3:8485/ns1</value>----->指出qjournal地址,这个集群就好比NFS,里面存放的是edits.log,主备namenode都可以访问,做到数据共享,藉此是实现HA的关键
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://xufeng-1:8485;xufeng-2:8485;xufeng-3:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/hadoop-data/hadoop/journaldata</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>------------------>两台主备namenode在其本地存放数据(fsimage)的目录
<value>/opt/hadoop/hadoop-data/hadoop/hdfs/namenode</value>
<description>NameNode directory for namespace and transaction logs storage.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop-data/hadoop/hdfs/datanode</value>
<description>DataNode directory</description>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>----->指明是使用zkfc的方式去管理主备切换,既伴随namenode启动也会同时在同样的机器上启动zkfc,它的目的就是管理namenode在zookeeper上节点,藉此来实现主备切换实现。
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>------>所谓隔离机制,既是到备namenode升级为主的时候将会使用这一个机制发送命令去杀死另外一个namenode,通常为kill -9(补枪的重要性,万一假死呢)
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->------>使用上述隔离机制既是想对方发送一条shell指令,那么久必须是免密码登录的。
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>---
<value>~/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value></value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>------>与namenode的服务一样,这里只写出一个逻辑名称,后续配置会进一步说明
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>------>上述cluster-id逻辑名称下具体有几个实际的rm
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>----->每一个rm的主机位置
<value>xufeng-</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>xufeng-</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>xufeng-:,xufeng-:,xufeng-:</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves文件
这个文件是公用的计算节点配置文件,当启动hdfs模块的时候,此时里面写入的主机上会启动datanode进程。
当启动yarn模块时候,此时里面写入的主机会启动nodemanager进程。
xufeng-
xufeng-
xufeng-
5. 启动hadoop方法和顺序(假设zookeeper已经启动完毕)
[首次启动场景]
1.启动journalnode(各个节点上都执行)
hadoop-daemon.sh start journalnode
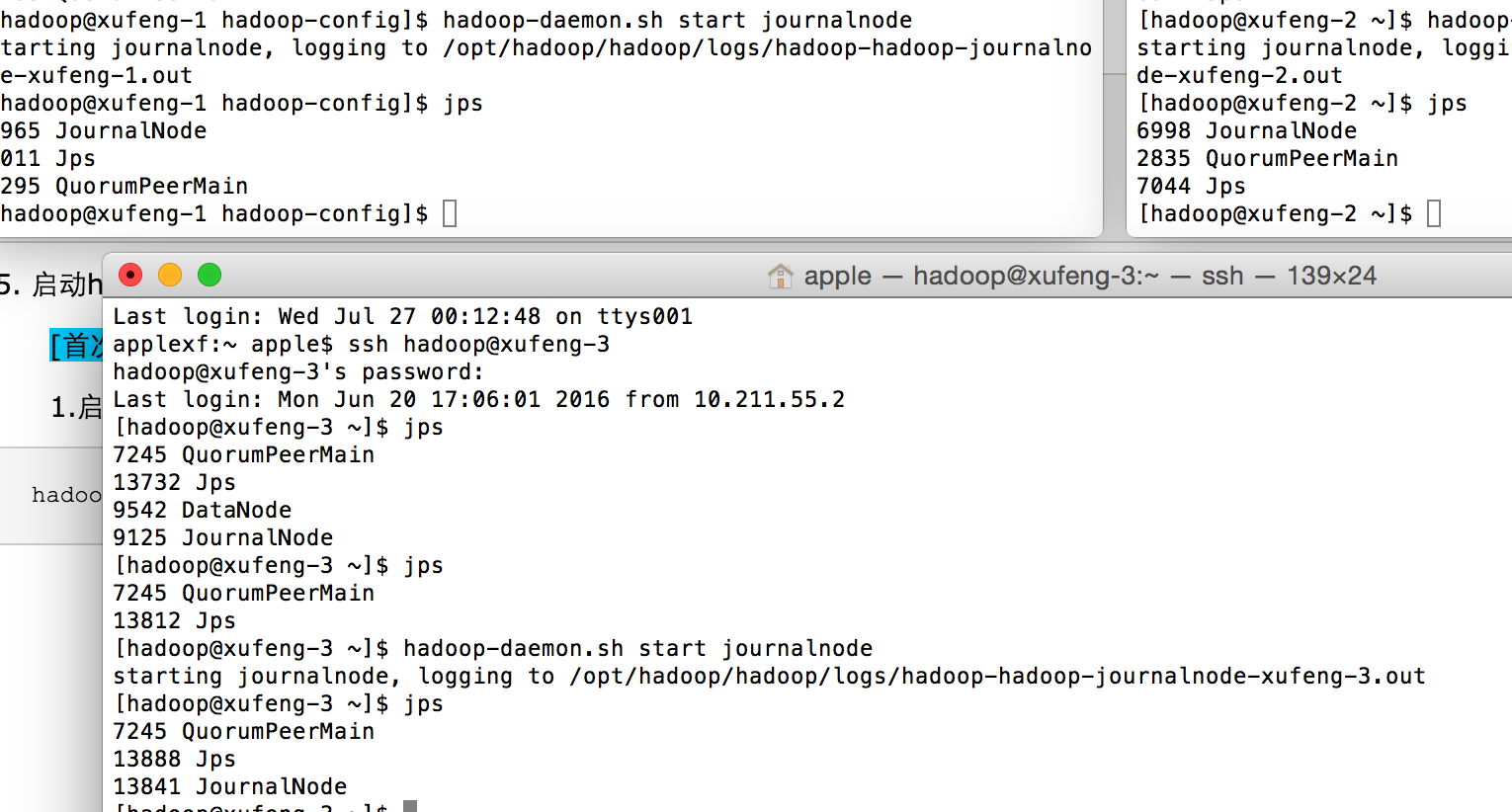
2.启动namenode与zkfc
a.由于有两个namenode,所以在xufeng-1上执行:
hdfs namenode -format
b.再将其工作目录(hdfs-site.xml的dfs.namenode.name.dir指定的路径)拷贝到xufeng-2这台主机的对应目录上,以保证两个namenode初始化数据相同
scp -r /opt/hadoop/hadoop-data/hadoop/hdfs/namenode/* xufeng-2:/opt/hadoop/hadoop-data/hadoop/hdfs/namenode
c.格式化zkfc(xufeng-1上执行即可)
hdfs zkfc -formatZK
d.启动hdfs
start-dfs.sh
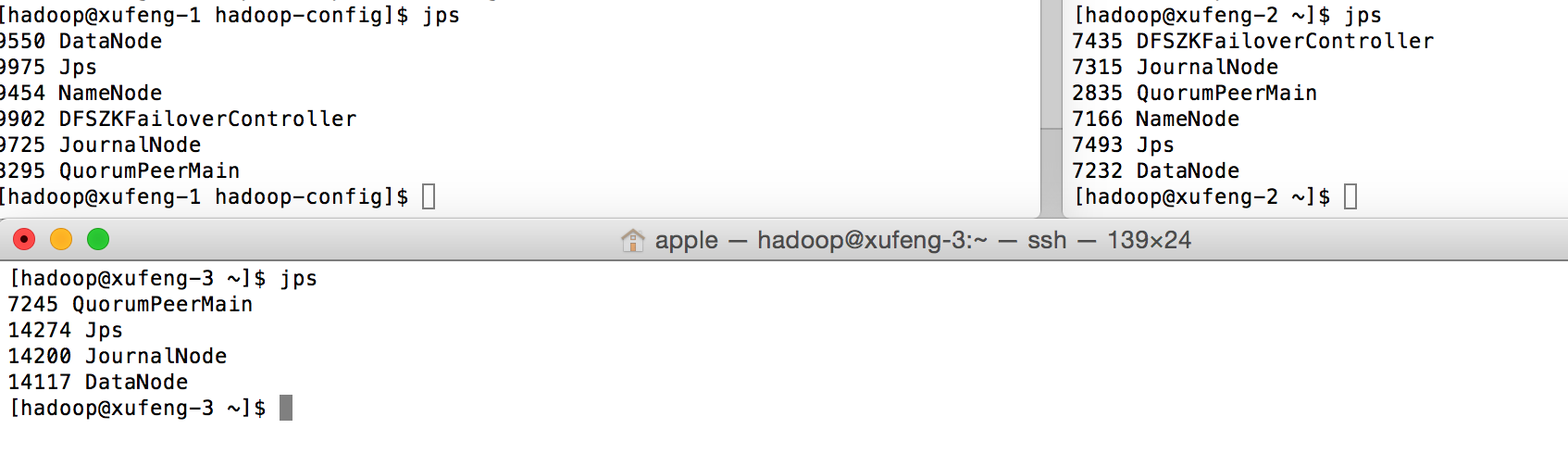
3.启动yarn
start-yarn.sh
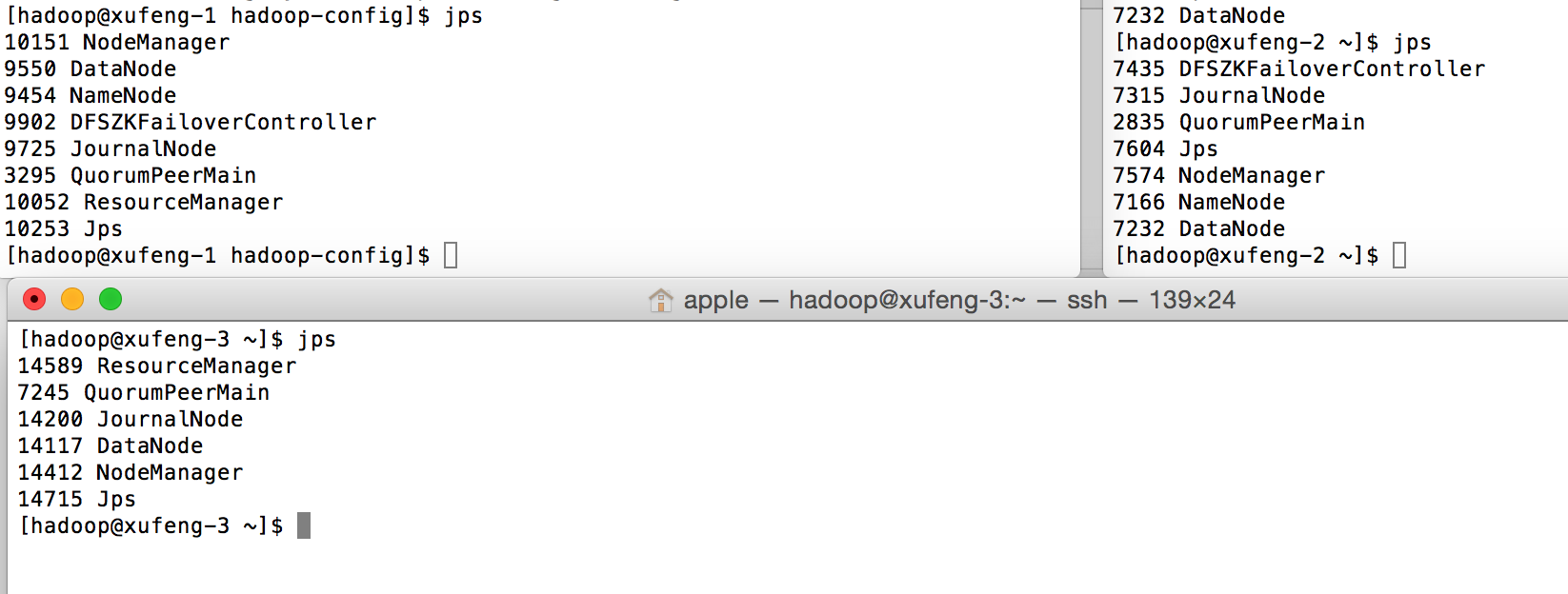
以上将hadoop所有的进程都启动完毕。
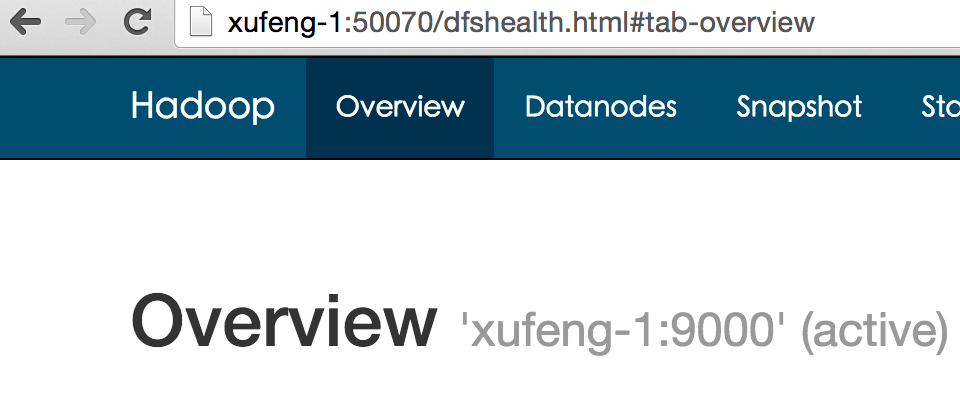
6. 验证安装结果
1.检查hdfs:
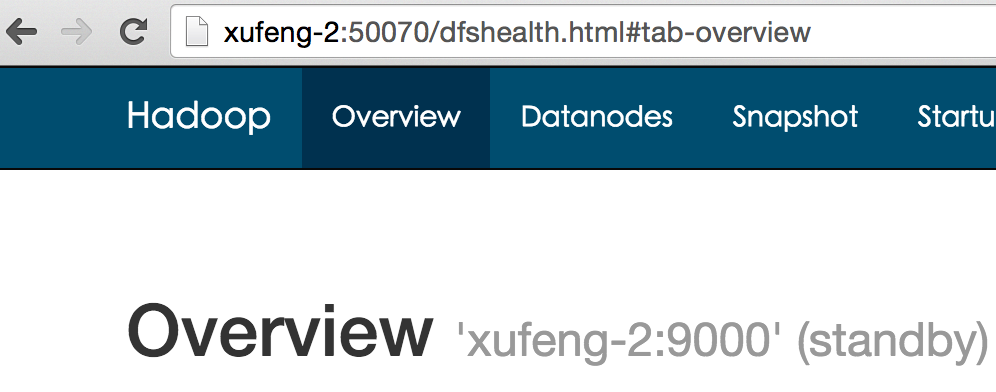
2.检查yarn

至此hadoop ha模式分布式安装完成。
以上。
[hadoop][会装]hadoop ha模式安装的更多相关文章
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- [hadoop][会装]HBase集群安装--基于hadoop ha模式
可以参考部署HBase系统(分布式部署) 和基于无HA模式的hadoop下部署相比,主要是修改hbase-site .xml文件,修改如下参数即可: <property> <name ...
- hadoop单机and集群模式安装
最近在学习hadoop,第一步当然是亲手装一下hadoop了. 下面记录我hadoop安装的过程: 注意: 1,首先明确hadoop的安装是一个非常简单的过程,装hadoop的主要工作都在配置文件上, ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- Hadoop学习之 HIVE 多用户模式安装
一.启动hadoop 集群 1.启动zookeeper 集群 zkServer.sh start 2.在master.hadoop 机器上 ./start-all.sh 由于 start-all命 ...
- 分布式集群HA模式部署
一:HDFS系统架构 (一)利用secondary node备份实现数据可靠性 (二)问题:NameNode的可用性不高,当NameNode节点宕机,则服务终止 二:HA架构---提高NameNode ...
- zookeeper三种模式安装详解(centos 7+zookeeper-3.4.9)
zookeeper有单机.伪集群.集群三种部署方式,可根据自己实际情况选择合适的部署方式.下边对这三种部署方式逐一进行讲解. 一 单机模式 1.下载 进入要下载的版本的目录,选择.tar.gz文件下载 ...
- Hadoop单机模式安装-(3)安装和配置Hadoop
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在Ubuntu安装完 ...
- Hadoop单机模式安装-(2)安装Ubuntu虚拟机
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在虚拟机设置完毕后, ...
随机推荐
- 1923: [Sdoi2010]外星千足虫
1923: [Sdoi2010]外星千足虫 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 1254 Solved: 799[Submit][Statu ...
- [洛谷P2495][SDOI2011]消耗战
题目大意:有一棵$n(n\leqslant2.5\times10^5)$个节点的带边权的树,$m$个询问,每次询问给出$k(\sum\limits_{i=1}^mk_i\leqslant5\times ...
- 【BZOJ4520】K远点对(KD-Tree)
[BZOJ4520]K远点对(KD-Tree) 题面 BZOJ 洛谷 题解 考虑暴力. 维护一个大小为\(K\)的小根堆,然后每次把两个点之间的距离插进去,然后弹出堆顶 这样子可以用\(KD-Tree ...
- 玩(lay) 解题报告
玩(lay) 题目名称 你的昆特牌打的太好啦!不一会你就 \(\tt{AK}\) 了 \(\tt{NOGP}\),只能无聊地堆牌玩! 题目描述 你有一些矩形卡牌,每次你会作如下三个操作: 紧挨着最后一 ...
- 洛谷 P2747 [USACO5.4]周游加拿大Canada Tour 解题报告
P2747 [USACO5.4]周游加拿大Canada Tour 题目描述 你赢得了一场航空公司举办的比赛,奖品是一张加拿大环游机票.旅行在这家航空公司开放的最西边的城市开始,然后一直自西向东旅行,直 ...
- HDU.2640 Queuing (矩阵快速幂)
HDU.2640 Queuing (矩阵快速幂) 题意分析 不妨令f为1,m为0,那么题目的意思为,求长度为n的01序列,求其中不含111或者101这样串的个数对M取模的值. 用F(n)表示串长为n的 ...
- git生成ssh key和多账号支持
git配置ssh 1.首先设置git的全局user name和email $ git config --global user.name "ygtzz"$ git config - ...
- EurekaServer集群配置
一.程序配置 1.pom添加依赖: <dependency> <groupId>org.springframework.cloud</groupId> <ar ...
- nginx 服务器启动、终止、重启
启动 在linux系统下输入命令: nginx地址 -c nginx配置文件 就可启动nginx eg:/usr/local/nginx/sbin/nginx -c /usr/local/nginx/ ...
- linux shell读取配置文件
配置文件CoverageInfo FTP_URL=ftp://svn-fb.sicent.com:21/jenkins/Jifei_Repo/OL-2/IDC_Platform/bar_seats_c ...