python库-urllib
urllib库提供了一系列操作url的功能,是python处理爬虫的入门级工具,网上的学习资料也很多。我做爬虫是一开始就用了Scrapy框架,并不是一步步从urllib开始的,反而是在后来解决一些小问题的时候用到了urllib库,感觉用起来很简洁也很实用,下面是我最近的一些应用总结。
1、urllib和urllib2
在python2.x的版本中有urllib和urllib2两个库,为什么这样我也没有好好去调研。两者能处理的问题有些相交,更多的是不同,在我的应用场景中,一个最重要的区别就是通过urllib2的方法可以修改header信息,而urllib不支持,后边的例子可以看到。
在python3的版本中,已经没有urllib2了,版本2中的urllib和urllib2合并在了一起,urllib自然也就支持修改头部信息
下面这两段代码是python2和python3的使用情况对比
import urllib2
req=urllib2.Request('https://www.python.org/')
req.add_header('Range','bytes=0-20')
res=urllib2.urlopen(req)
data=res.read().decode('utf-8')
print data
python3:
from urllib import request
req=request.Request("https://www.python.org/")
req.add_header('Range','bytes=0-20')
res=request.urlopen(req) res.read().decode('utf-8')
2、应用urllib爬取页面信息的完整小案例(python2)
我理解的整个爬虫的过程就是首先下载网页,然后对网页进行解析提取需要的数据,最后数据入库或者是文件等等。上面的代码已经将网页下载下来了,只不过由于修改了Range信息,所以只下载了网页的一部分。
下面的例子就是如何解析网页,我之前关于Scrapy的博客用到了Xpath的方式,下面这个例子是用的正则,其实解析网页就没有urllib什么事了...
豆瓣电影中排名前170名电影的得分之和:我用的urllib库,用urllib2也是可以的
import urllib
import re
ll=[]
for i in range(7):
url='http://movie.douban.com/top250?start'+str(i*25)
req=urllib.urlopen(url)
page=req.read()
reg='<span class="rating_num" property="v:average">([0-9]+.[0-9]+)</span>'
regc=re.compile(reg)
res=regc.findall(page)
ll.extend(res)
sum=0
for i in range(170):
sum+=float(ll[i])
print sum
3、应用urllib2发送get和post请求(python2)
get和post最简单的理解就是,get是把请求信息附加到url里,而post则是通过表单
(1)查看请求参数——看url,可以从网址栏看,也可以通过开发者工具看
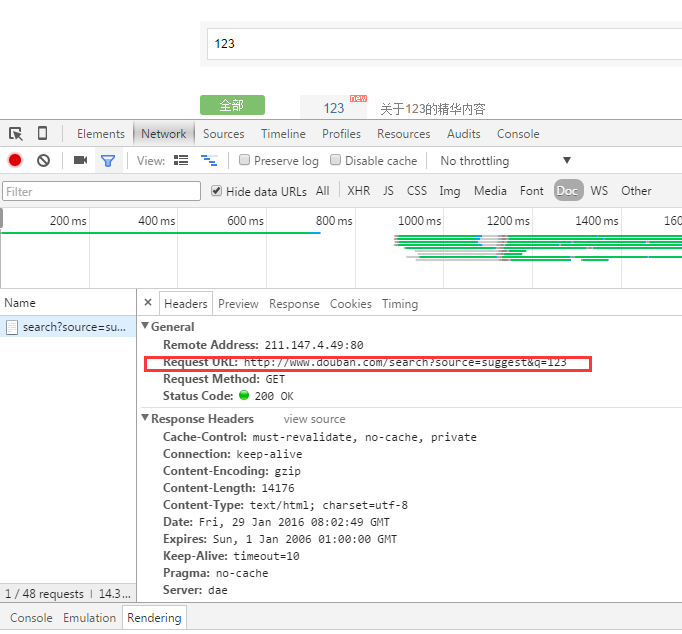
或者从,参数列表看:
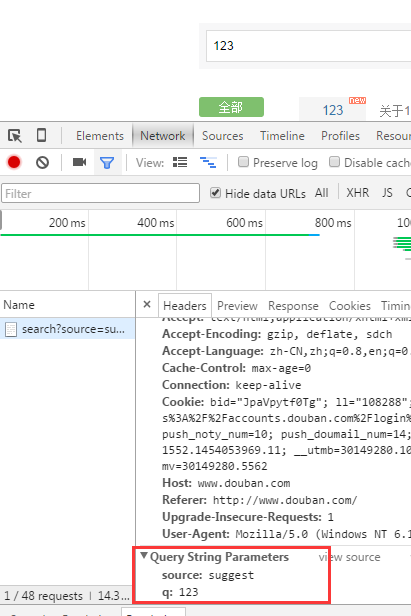
(2)get方式----把参数附加到url即可
import urllib2
url='http://www.douban.com/search?source=suggest&q=123'
req=urllib2.Request(url)
(3)post方式
import urllib
import urllib2
url="http://www.douban.com/search"
data={'source':'suggest','q':''}
data=urllib.urlencode(data) # 编码成url的格式
req=urllib2.Request(url=url,data=data)
4、爬虫真的很好玩~~
最后再说点有意思的,本人也是有喜欢的小明星哒,网上那么多的美图下也下不过来,肿么办呢?写个爬虫吧哈哈~前几天逛贴吧看美图突发奇想写个小爬虫,追星学习两不误呢~
import re
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x = x + 1 html = getHtml("http://tieba.baidu.com/p/..........?pn=1") #改一下参数
getImg(html)
python库-urllib的更多相关文章
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- Python爬虫--Urllib库
Urllib库 Urllib是python内置的HTTP请求库,包括以下模块:urllib.request (请求模块).urllib.error( 异常处理模块).urllib.parse (url ...
- python之urllib库
urllib库 urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urlli ...
- python 之 Urllib库的基本使用
目录 python 之 Urllib库的基本使用 官方文档 什么是Urllib urlopen url参数的使用 data参数的使用 timeout参数的使用 响应 响应类型.状态码.响应头 requ ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python中urllib, urllib2,urllib3, httplib,httplib2, request的区别
permike原文python中urllib, urllib2,urllib3, httplib,httplib2, request的区别 若只使用python3.X, 下面可以不看了, 记住有个ur ...
- python:利用urllib查找计算机二级准考证号
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAaYAAAEACAIAAAB3VkWnAAAgAElEQVR4nOydZ3gUR9bv+WhExhHnDH
随机推荐
- ARC077D 11 组合数
---题面--- 题解: 做这道题的时候zz了,,,, 写了个很复杂的式子,然而后面重新想就发现很简单了. 考虑用总的情况减去重复的. 假设唯一重复的两个数的位置分别是l和r,那么唯一会导致重复的方案 ...
- Android 自定义View消除锯齿实现图片旋转,添加边框及文字说明
先看看图片的效果,左边是原图,右边是旋转之后的图: 之所以把这个写出来是因为在一个项目中需要用到这样的效果,我试过用FrameLayout布局如上的画面,然后旋转FrameLayout,随之而来也 ...
- LOJ2351:[JOI2017/2018决赛]毒蛇越狱——题解
https://loj.ac/problem/2351 参考:https://www.cnblogs.com/ivorysi/p/9144676.html 但是参考博客讲解太吓人了,我们换一种通俗易懂 ...
- bzoj4870: [Shoi2017]组合数问题(DP+矩阵乘法优化)
为了1A我居然写了个暴力对拍... 那个式子本质上是求nk个数里选j个数,且j%k==r的方案数. 所以把组合数的递推式写出来f[i][j]=f[i-1][j]+f[i-1][(j-1+k)%k].. ...
- HDU 2094 拓扑排序
产生冠军 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submi ...
- librdkafka 源码分析
http://note.youdao.com/noteshare?id=c7ff510525b4dadaabb6f6a0a72040cc
- 【题解】互不侵犯 SCOI 2005 BZOJ 1087 插头dp
以前没学插头dp的时候觉得这题贼难,根本不会做,学了才发现原来是一裸题. 用二进制表示以前的格子的状态,0表示没放国王,1表示放了国王. 假设当前位置为(x,y),需要记录的是(x-1,y-1)至(x ...
- gitlab 的使用策略和简单介绍
gitlab 作为版本控制器,基本使用和github 相同,以下是一些策略和介绍: Git 分支管理策略可以参考下面三个链接: http://www.ruanyifeng.com/blog/2012/ ...
- MongoDB入门(2)- MongoDB安装
windows安装 下载文件,解压缩即可.下载地址 每次运行mongod --dbpath D:/MongoDB/data 命令行来启动MongoDB实在是不方便,把它作为Windows服务,这样就方 ...
- 最大公倍数_Greatest Common Divisor
计算最大公倍数 Static int gcd( int a, int b) { int t; while( b>0) { t = b; b = a % b; a = t; } return a; ...