HashTable代码解析
HashTable继承关系如下:
HashTable是一个线程安全的【键-值对】存储结构。其存储结构和HashMap相同,参考这里。
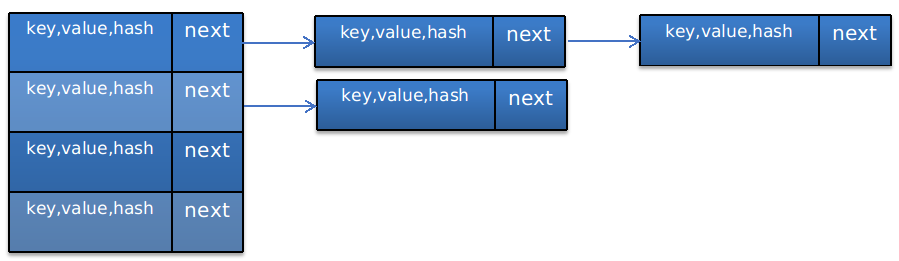
1. HashTable定义了一个类型为Entry<K,V>的数组table用来存储数据。
/**
* The hash table data.
*/
private transient Entry<K,V>[] table;
类型Entry<K,V>的定义如下:
/**
* Hashtable bucket collision list entry
*/
private static class Entry<K,V> implements Map.Entry<K,V> {
int hash;
final K key;
V value;
Entry<K,V> next;
}
由Entry<K,V>的定义可知,上图每个节点中其实存了4个变量:
key表示键,即存入map的键值
value表示值,即存入map的值
next表示下一个Entry节点
hash表示key的哈希值。
那么,table的图示为:
2. HashTable定义了count值来表示HashTable中元素的个数
/**
* The total number of entries in the hash table.
*/
private transient int count;
由于所有对count值进行操作的方法都是线程安全的,所以count可以精确表示HashTable中元素的个数。(在HashMap中,size()方法是不精确的)
有了精确的count值,求size() / isEmpty() 就比较简单了。
/**
* Returns the number of keys in this hashtable.
*
* @return the number of keys in this hashtable.
*/
public synchronized int size() {
return count;
} /**
* Tests if this hashtable maps no keys to values.
*
* @return <code>true</code> if this hashtable maps no keys to values;
* <code>false</code> otherwise.
*/
public synchronized boolean isEmpty() {
return count == 0;
}
注意: 这些方法都带有synchronized关键字。
3. HashTable同样定义了
threshold: hashtable的重新扩容的阈值,一般值为(int)(capacity * loadFactor)。二般情况下是什么值呢?就是当HashTable的table数组的大小已经超过Integer最大值-8时,rehash的时候不在扩大table数组的大小,而是将threshold值放到最大。
loadFactor: 负载因子,默认是0.75f
modCount: 修改次数
代码如下:
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
*
* @serial
*/
private int threshold; /**
* The load factor for the hashtable.
*
* @serial
*/
private float loadFactor; /**
* The number of times this Hashtable has been structurally modified
* Structural modifications are those that change the number of entries in
* the Hashtable or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the Hashtable fail-fast. (See ConcurrentModificationException).
*/
private transient int modCount = 0;
3. HashTable默认构造函数为
/**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).
*/
public Hashtable() {
this(11, 0.75f);
}
为什么初始容量为11 ??
其中, this()调用了
/**
* Constructs a new, empty hashtable with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hashtable.
* @param loadFactor the load factor of the hashtable.
* @exception IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive.
*/
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
// 初始化table数组变量
table = new Entry[initialCapacity];
// 求threshold的值
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
initHashSeedAsNeeded(initialCapacity);
}
4. hash()方法
private int hash(Object k) {
// hashSeed will be zero if alternative hashing is disabled.
return hashSeed ^ k.hashCode();
}
5. put()方法,使用了synchronized方法修饰
/**
* Maps the specified <code>key</code> to the specified
* <code>value</code> in this hashtable. Neither the key nor the
* value can be <code>null</code>. <p>
*
* The value can be retrieved by calling the <code>get</code> method
* with a key that is equal to the original key.
*
* @param key the hashtable key
* @param value the value
* @return the previous value of the specified key in this hashtable,
* or <code>null</code> if it did not have one
* @exception NullPointerException if the key or value is
* <code>null</code>
* @see Object#equals(Object)
* @see #get(Object)
*/
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
} // Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key); // 在HashMap中,求一个key的索引位置是只用的hash & (tab.length-1)
int index = (hash & 0x7FFFFFFF) % tab.length;
// 如果已经包含了该key,更新value,并返回旧的value
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
} modCount++;
// 如果HashTable中元素的个数已经超过了阈值threshold,需要对HashTable扩容,从新hash
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash(); tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
} // Creates the new entry. 这里同样是在链表头部插入元素,将当前链表的第一个节点作为新节点的下一个元素
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
// 元素个数加1
count++;
return null;
}
6. rehash(),HashTable是如何进行rehash的呢?
/**
* Increases the capacity of and internally reorganizes this
* hashtable, in order to accommodate and access its entries more
* efficiently. This method is called automatically when the
* number of keys in the hashtable exceeds this hashtable's capacity
* and load factor.
*/
protected void rehash() {
int oldCapacity = table.length;
Entry<K,V>[] oldMap = table; // overflow-conscious code
// oldCapacity左移1位,扩大2倍,可能会溢出
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
// 创建新的table,大小为newCapacity
Entry<K,V>[] newMap = new Entry[newCapacity]; modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
boolean rehash = initHashSeedAsNeeded(newCapacity); // 更新table数组,为新的newMap
table = newMap;
// 遍历oldMap,迁移到新的newMap中
// oldMap数组的长度为oldCapacity
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next; if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
7. get()方法比较简单
(a). 根据key,求出hash值
(b). 根据hash值求出key所在的table的索引index,可以定位到链表的第一个元素
(c). 遍历链表娶老婆(元素), 娶不到返回null
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key.equals(k))},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @param key the key whose associated value is to be returned
* @return the value to which the specified key is mapped, or
* {@code null} if this map contains no mapping for the key
* @throws NullPointerException if the specified key is null
* @see #put(Object, Object)
*/
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
8. remove(),最后再来学习下remove()方法
/**
* Removes the key (and its corresponding value) from this
* hashtable. This method does nothing if the key is not in the hashtable.
*
* @param key the key that needs to be removed
* @return the value to which the key had been mapped in this hashtable,
* or <code>null</code> if the key did not have a mapping
* @throws NullPointerException if the key is <code>null</code>
*/
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
// 和get方法类似,同样是先获取到key对应的链表tab[index]
// 然后遍历链表,移除元素
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
// prev -> e ,prev是e的下一个元素,e就是要删除的元素
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
// count个数减1
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
HashTable的线程安全是使用synchronized关键字实现的,因此效率不高,所以在多线程环境下,推荐使用ConcurrentHashMap。
HashTable代码解析的更多相关文章
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
- VBA常用代码解析
031 删除工作表中的空行 如果需要删除工作表中所有的空行,可以使用下面的代码. Sub DelBlankRow() DimrRow As Long DimLRow As Long Dimi As L ...
- [nRF51822] 12、基础实验代码解析大全 · 实验19 - PWM
一.PWM概述: PWM(Pulse Width Modulation):脉冲宽度调制技术,通过对一系列脉冲的宽度进行调制,来等效地获得所需要波形. PWM 的几个基本概念: 1) 占空比:占空比是指 ...
- [nRF51822] 11、基础实验代码解析大全 · 实验16 - 内部FLASH读写
一.实验内容: 通过串口发送单个字符到NRF51822,NRF51822 接收到字符后将其写入到FLASH 的最后一页,之后将其读出并通过串口打印出数据. 二.nRF51822芯片内部flash知识 ...
- [nRF51822] 10、基础实验代码解析大全 · 实验15 - RTC
一.实验内容: 配置NRF51822 的RTC0 的TICK 频率为8Hz,COMPARE0 匹配事件触发周期为3 秒,并使能了TICK 和COMPARE0 中断. TICK 中断中驱动指示灯D1 翻 ...
- [nRF51822] 9、基础实验代码解析大全 · 实验12 - ADC
一.本实验ADC 配置 分辨率:10 位. 输入通道:5,即使用输入通道AIN5 检测电位器的电压. ADC 基准电压:1.2V. 二.NRF51822 ADC 管脚分布 NRF51822 的ADC ...
- Kakfa揭秘 Day8 DirectKafkaStream代码解析
Kakfa揭秘 Day8 DirectKafkaStream代码解析 今天让我们进入SparkStreaming,看一下其中重要的Kafka模块DirectStream的具体实现. 构造Stream ...
- linux内存管理--slab及其代码解析
Linux内核使用了源自于 Solaris 的一种方法,但是这种方法在嵌入式系统中已经使用了很长时间了,它是将内存作为对象按照大小进行分配,被称为slab高速缓存. 内存管理的目标是提供一种方法,为实 ...
- MYSQL常见出错mysql_errno()代码解析
如题,今天遇到怎么一个问题, 在理论上代码是不会有问题的,但是还是报了如上的错误,把sql打印出來放到DB中却可以正常执行.真是郁闷,在百度里面 渡 了很久没有相关的解释,到时找到几个没有人回复的 & ...
随机推荐
- xml方式将dataset导出excel
using System;using System.Collections;using System.Collections.Generic;using System.Data;using Syste ...
- hive中,动态添加map和reduce的大小,以增加并行度
map是配置mapred.max.split.size,来定义map处理文件的大小,默认是256000000字段,换算就是256M. 如果想增加map的并行度,那么就是减少map处理文件的大小即可. ...
- springmvc+ajax——第一讲(搭建)
下面是整个整合测试的代码: ajax01.html TestController web.xml springmvc.xml applicationContext.xml <!DOCTYPE h ...
- 20165220预备作业3 Linux安装及学习
首先对于这第三次作业而言,给我的准备时间确实不多,因为过年回老家6天,没有办法及时的进行学习和思考,回到家中便草草的看了下相关操作跟教程从而完成了作业,这次主要是学习一些基础操作,为开学的Java学习 ...
- HDU4578 Transformation【线段树】
<题目链接> <转载于 >>> > 题目大意: 有一个序列,有四种操作: 1:区间[l,r]内的数全部加c. 2:区间[l,r]内的数全部乘c. 3:区间[l ...
- 在控制台下玩玩dotnet core内置原生的DI
转载请注明出处:http://www.cnblogs.com/zhiyong-ITNote/ 在基于dotnet core的web开发中,我们会经常用到DI,那么如果单单使用dotnet core自身 ...
- PHP SOAP
<?php $classmap = array(); //注意和实例一的不同 $soap = new SoapServer(null, array('uri' => "http: ...
- UVA 2519 Radar Installtion
思路: #include<cstdio> #include<iostream> #include<cmath> #include<algorithm> ...
- BZOJ.3170.[TJOI2013]松鼠聚会(切比雪夫距离转曼哈顿距离)
题目链接 将原坐标系每个点的坐标\((x,y)\)变为\((x+y,x-y)\),则原坐标系中的曼哈顿距离等于新坐标系中的切比雪夫距离. 反过来,将原坐标系每个点的坐标\((x,y)\)变为\((\f ...
- Centos7常用操作
1.装完系统无法用scrt连接服务器 查看IP命令 ip addr [root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 ...