Apriori
基本概念
- 项与项集:设itemset={item1, item_2, …, item_m}是所有项的集合,其中,item_k(k=1,2,…,m)成为项。项的集合称为项集(itemset),包含k个项的项集称为k项集(k-itemset)。
- 事务与事务集:一个事务T是一个项集,它是itemset的一个子集,每个事务均与一个唯一标识符Tid相联系。不同的事务一起组成了事务集D,它构成了关联规则发现的事务数据库。
- 关联规则:关联规则是形如A=>B的蕴涵式,其中A、B均为itemset的子集且均不为空集,而A交B为空。
- 支持度(support):关联规则的支持度定义如下:

其中
 表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。
表示事务包含集合A和B的并(即包含A和B中的每个项)的概率。注意与P(A or B)区别,后者表示事务包含A或B的概率。 - 置信度(confidence):关联规则的置信度定义如下:
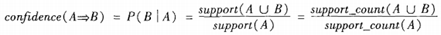
- 项集的出现频度(support count):包含项集的事务数,简称为项集的频度、支持度计数或计数。
- 频繁项集(frequent itemset):如果项集I的相对支持度满足事先定义好的最小支持度阈值(即I的出现频度大于相应的最小出现频度(支持度计数)阈值),则I是频繁项集。
- 强关联规则:满足最小支持度和最小置信度的关联规则,即待挖掘的关联规则。
实现步骤
一般而言,关联规则的挖掘是一个两步的过程:
- 找出所有的频繁项集
- 由频繁项集产生强关联规则
挖掘频繁项集
1 相关定义
- 连接步骤:频繁(k-1)项集Lk-1的自身连接产生候选k项集Ck
Apriori算法假定项集中的项按照字典序排序。如果Lk-1中某两个的元素(项集)itemset1和itemset2的前(k-2)个项是相同的,则称itemset1和itemset2是可连接的。所以itemset1与itemset2连接产生的结果项集是{itemset1[1], itemset1[2], …, itemset1[k-1], itemset2[k-1]}。连接步骤包含在下文代码中的create_Ck函数中。
- 剪枝策略
由于存在先验性质:任何非频繁的(k-1)项集都不是频繁k项集的子集。因此,如果一个候选k项集Ck的(k-1)项子集不在Lk-1中,则该候选也不可能是频繁的,从而可以从Ck中删除,获得压缩后的Ck。下文代码中的is_apriori函数用于判断是否满足先验性质,create_Ck函数中包含剪枝步骤,即若不满足先验性质,剪枝。
- 删除策略
基于压缩后的Ck,扫描所有事务,对Ck中的每个项进行计数,然后删除不满足最小支持度的项,从而获得频繁k项集。删除策略包含在下文代码中的generate_Lk_by_Ck函数中。
2 步骤
- 每个项都是候选1项集的集合C1的成员。算法扫描所有的事务,获得每个项,生成C1(见下文代码中的create_C1函数)。然后对每个项进行计数。然后根据最小支持度从C1中删除不满足的项,从而获得频繁1项集L1。
- 对L1的自身连接生成的集合执行剪枝策略产生候选2项集的集合C2,然后,扫描所有事务,对C2中每个项进行计数。同样的,根据最小支持度从C2中删除不满足的项,从而获得频繁2项集L2。
- 对L2的自身连接生成的集合执行剪枝策略产生候选3项集的集合C3,然后,扫描所有事务,对C3每个项进行计数。同样的,根据最小支持度从C3中删除不满足的项,从而获得频繁3项集L3。
- 以此类推,对Lk-1的自身连接生成的集合执行剪枝策略产生候选k项集Ck,然后,扫描所有事务,对Ck中的每个项进行计数。然后根据最小支持度从Ck中删除不满足的项,从而获得频繁k项集。
由频繁项集产生关联规则
一旦找出了频繁项集,就可以直接由它们产生强关联规则。产生步骤如下:
- 对于每个频繁项集itemset,产生itemset的所有非空子集(这些非空子集一定是频繁项集);
- 对于itemset的每个非空子集s,如果
 ,则输出
,则输出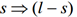 ,其中min_conf是最小置信度阈值。
,其中min_conf是最小置信度阈值。
样例以及Python实现代码
下图是《数据挖掘:概念与技术》(第三版)中挖掘频繁项集的样例图解。

本文基于该样例的数据编写Python代码实现Apriori算法。代码需要注意如下两点:
- 由于Apriori算法假定项集中的项是按字典序排序的,而集合本身是无序的,所以我们在必要时需要进行set和list的转换;
- 由于要使用字典(support_data)记录项集的支持度,需要用项集作为key,而可变集合无法作为字典的key,因此在合适时机应将项集转为固定集合frozenset。

"""
# Python 2.7
# Filename: apriori.py
# Author: llhthinker
# Email: hangliu56[AT]gmail[DOT]com
# Blog: http://www.cnblogs.com/llhthinker/p/6719779.html
# Date: 2017-04-16
""" def load_data_set():
"""
Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition)
Returns:
A data set: A list of transactions. Each transaction contains several items.
"""
data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'],
['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'],
['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']]
return data_set def create_C1(data_set):
"""
Create frequent candidate 1-itemset C1 by scaning data set.
Args:
data_set: A list of transactions. Each transaction contains several items.
Returns:
C1: A set which contains all frequent candidate 1-itemsets
"""
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1 def is_apriori(Ck_item, Lksub1):
"""
Judge whether a frequent candidate k-itemset satisfy Apriori property.
Args:
Ck_item: a frequent candidate k-itemset in Ck which contains all frequent
candidate k-itemsets.
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
Returns:
True: satisfying Apriori property.
False: Not satisfying Apriori property.
"""
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lksub1:
return False
return True def create_Ck(Lksub1, k):
"""
Create Ck, a set which contains all all frequent candidate k-itemsets
by Lk-1's own connection operation.
Args:
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
k: the item number of a frequent itemset.
Return:
Ck: a set which contains all all frequent candidate k-itemsets.
"""
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
# pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
"""
Generate Lk by executing a delete policy from Ck.
Args:
data_set: A list of transactions. Each transaction contains several items.
Ck: A set which contains all all frequent candidate k-itemsets.
min_support: The minimum support.
support_data: A dictionary. The key is frequent itemset and the value is support.
Returns:
Lk: A set which contains all all frequent k-itemsets.
"""
Lk = set()
item_count = {}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk def generate_L(data_set, k, min_support):
"""
Generate all frequent itemsets.
Args:
data_set: A list of transactions. Each transaction contains several items.
k: Maximum number of items for all frequent itemsets.
min_support: The minimum support.
Returns:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
"""
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data def generate_big_rules(L, support_data, min_conf):
"""
Generate big rules from frequent itemsets.
Args:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
min_conf: Minimal confidence.
Returns:
big_rule_list: A list which contains all big rules. Each big rule is represented
as a 3-tuple.
"""
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in big_rule_list:
# print freq_set-sub_set, " => ", sub_set, "conf: ", conf
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list if __name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)
for Lk in L:
print "="*50
print "frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport"
print "="*50
for freq_set in Lk:
print freq_set, support_data[freq_set]
print "Big Rules"
for item in big_rules_list:
print item[0], "=>", item[1], "conf: ", item[2]
代码运行结果截图如下:
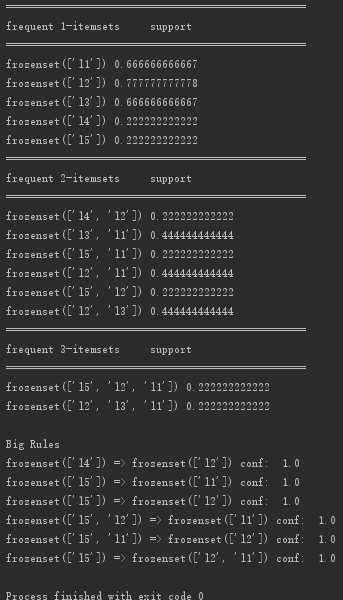
==============================
Apriori的更多相关文章
- Apriori算法的原理与python 实现。
前言:这是一个老故事, 但每次看总是能从中想到点什么.在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售.但是这个奇怪的举措却使尿布和啤酒的销量双双增加了.这不是一个笑话,而是发生在美国沃尔玛 ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- #研发解决方案#基于Apriori算法的Nginx+Lua+ELK异常流量拦截方案
郑昀 基于杨海波的设计文档 创建于2015/8/13 最后更新于2015/8/25 关键词:异常流量.rate limiting.Nginx.Apriori.频繁项集.先验算法.Lua.ELK 本文档 ...
- 数据挖掘算法(四)Apriori算法
参考文献: 关联分析之Apriori算法
- Apriori on MapReduce
Apiroi算法在Hadoop MapReduce上的实现 输入格式: 一行为一个Bucket 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 34 36 38 ...
- Apriori——python3实现
最近看了关联算法中的Apriori没看懂,这次看了一些论文总算看懂了,不过还是没能够自己实现.在github搜到一些代码看,看的不很懂,这里先贴上(当中有自己加的注释),有时间再补充研究. # -*- ...
- Apriori 关联分析算法原理分析与代码实现
前言 想必大家都听过数据挖掘领域那个经典的故事 - "啤酒与尿布" 的故事. 那么,具体是怎么从海量销售信息中挖掘出啤酒和尿布之间的关系呢? 这就是关联分析所要完成的任务了. 本文 ...
- apriori推荐算法
大数据时代开始流行推荐算法,所以作者写了一篇教程来介绍apriori推荐算法. 推荐算法大致分为: 基于物品和用户本身 基于关联规则 基于模型的推荐 基于物品和用户本身 基于物品和用户本身的,这种推荐 ...
- 关联分析---Apriori
关联分析是一种在大规模数据集中寻找有趣关系的任务,这些关系有两种形式:频繁项集和关联规则.频繁项集是经常出现在一起的物品的集合,关联规则暗示两种物品之间可能存在的很强的关系. 如何寻找数据集中的频繁或 ...
- Apriori原理与实践
Apriori: 其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集.经典的关联规则数据挖掘算法Apriori 算法广泛应用于各种领域,通过对数据的关联性进行了分析和挖掘,挖掘出的这 ...
随机推荐
- OSI 协议
- Java编程常见缺陷汇总(一)
[案例1] public boolean equalNode(JudgeNode a, JudgeNode b) { return a.getId() == b.getId(); } [点评] 应在 ...
- 【thinkphp5】安全建议:隐藏后台登录入口地址
我们都知道后台 www.test.com/admin 是我们最常用的登录入口,方便的同时也留下了隐患,如果你刚好使用了 admin/ 这种账号密码的方式,会导致我们的后台完全暴露在外. 因此我们建 ...
- Delphi过程函数传递参数的几种方式
Delphi过程函数传递参数的几种方式 在Delphi过程.函数中传递参数几个修饰符为Const.Var.Out. 另一种不加修饰符的为默认按值传递参数. 一.默认方式以值方式传递参数 proced ...
- 【分布式系列】session跨域及单点登录解决方案
Cookie机制 Cookie技术是客户端的解决方案,Cookie就是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息. ...
- [原]CentOS7安装Rancher2.1并部署kubernetes (一)---部署Rancher
################## Rancher v2.1.7 + Kubernetes 1.13.4 ################ ##################### ...
- JS中实现种子随机数
参数: 详谈JS中实现种子随机数及作用 我在Egret里这么写... class NumberTool{ /**种子(任意默认值5)*/ public static seed:number = 5; ...
- win10 安装mysql
现在mysql压缩包:https://downloads.mysql.com/archives/community/ 在目录下新建data文件夹,my.ini文件,内容如下: [mysqld] bas ...
- 如何查看MySQL单个数据库或者表的大小
总体来说,这些信息存在于information_schema数据库的TABLES表中 mysql> desc information_schema.TABLES; +-------------- ...
- 解决org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)错误
我调这个bug调了一天多,在网上搜索的检查namespace,package等,都没有错.错误提示是没有找到xml文件,我就纳闷了,为什么找不到呢?后来才发现,原来是resource中奇怪的目录为题, ...