Linux 搭建Hadoop集群 成功
内容基于(自己的真是操作步骤编写)
一:下载安装 Hadoop
1.1:下载指定的Hadoop
hadoop-2.8.0.tar.gz

1.2:通过XFTP把文件上传到master电脑bigData目录下
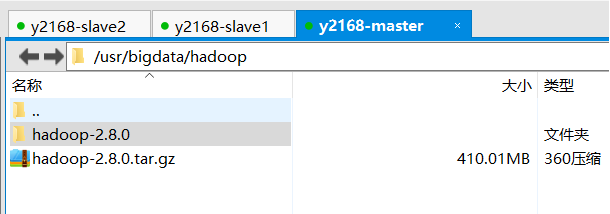
1.3:解压hadoop压缩文件
tar -xvf hadoop-2.8.0.tar.gz
1.4:进入压缩文件之后 复制路径
/bigData/hadoop-2.8.0
1.5:配置Hadoop的环境变量
vim /etc/profile

添加如下配置:

export HADOOP_HOME=/usr/bigdata/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让文件生效:
wq!保存并退出
source /etc/profile让文件生效

二:Hadoop集群的配置
2.1:进入hadoop的配置文件位置
进入hadoop配置文件目录
cd hadoop2.8.0/etc/hadoop/

2.2:配置hadoop-env.sh文件
vim hadoop-env.sh
加入如下配置:
export JAVA_HOME=/usr/bigdata/java/jdk1.8.0_121
2.3:配置yarn-env.sh文件
vim yarn-env.sh
加入如下配置:
export JAVA_HOME=/usr/bigdata/java/jdk1.8.0_121
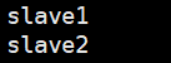
2.4:配置slaves文件,增加slave主机名或者IP地址
01.vim slaves
删除原有localhost,加入子机器名称或者ip地址
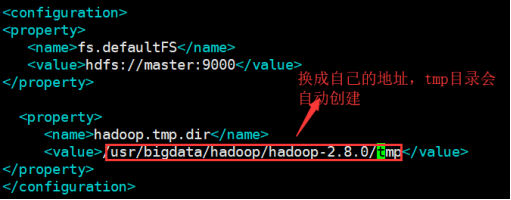
2.5:配置core-site.xml文件
01.vim core-site.xml
02.在configuration节点下加入如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/bigdata/hadoop/hadoop-2.8.0/tmp</value>
</property>
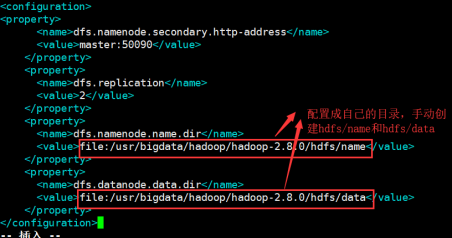
2.6:配置hdfs-site.xml文件
vim hdfs-site.xml
在configuration节点下加入如下配置:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop/hadoop-2.8.0/hdfs/data</value>
</property>
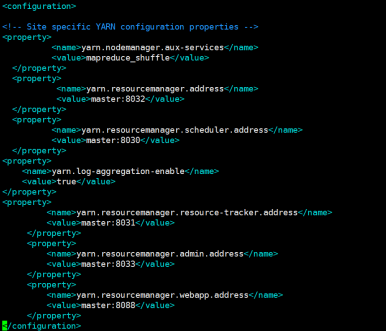
2.7:配置yarn-site.xml文件
在configuration节点下加入如下配置:
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
2.8:配置mapred-site.xml文件
mapred-site.xml.template存在
mapred-site.xml不存在
先要copy一份
cp mapred-site.xml.template mapred-site.xml
然后编辑
vim mapred-site.xml
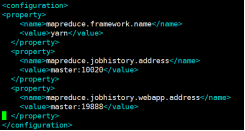
在configuration节点下加入如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
2.9:把配置好的hadoop文件复制到其他的子机器中
scp -r /usr/bigdata/hadoop/hadoop-2.8.0 root@slave1:/usr/bigdata/hadoop
scp -r /usr/bigdata/hadoop/hadoop-2.8.0 root@slave2:/usr/bigdata/hadoop
3.0把配置好的/etc/profile复制到其他两个子机器中
scp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile
分别在两个子机器中应用/etc/profile
source /etc/profile
3.1:在master 主机器中运行
hdfs namenode -format
3.2:在master 主机器中启动hadoop环境
进入/usr/bigdata/hadoop/hadoop-2.8.0/sbin
./start-all.sh 启动hadoop集群
./stop-all.sh 关闭hadoop集群
3.3:jps
vim jps

3.4:启动JobHistoryServer
./mr-jobhistory-daemon.sh start historyserver

访问页面:
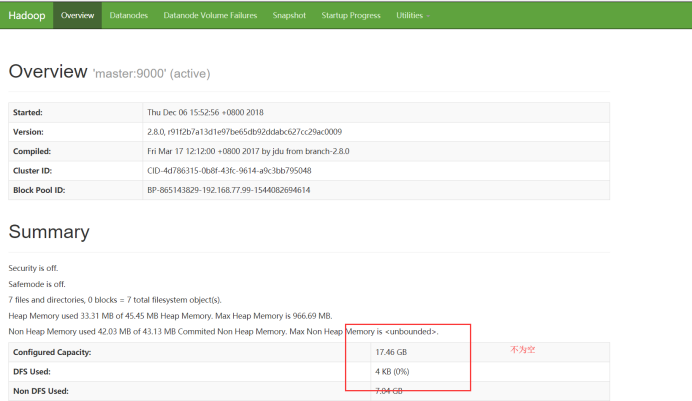


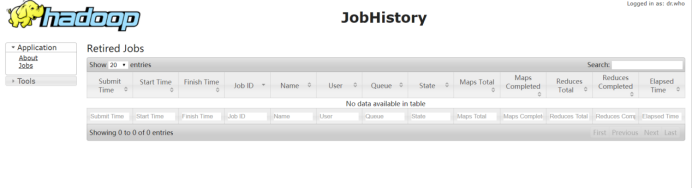
Hadoop集群搭建成功
3.5关闭:
第一步:
关闭JobHistoryServer
./mr-jobhistory-daemon.sh stop historyserver
第二步:
关闭hadoop集群
./stop-all.sh
Linux 搭建Hadoop集群 成功的更多相关文章
- Linux 搭建Hadoop集群错误锦集
一.Hadoop集群配置好后,执行start-dfs.sh后报错,一堆permission denied zf sbin $ ./start-dfs.sh Starting namenodes on ...
- Linux 搭建Hadoop集群 ----workcount案例
在 Linux搭建集群---JDK配置 Linux搭建集群---SSH免密登陆 Linux搭建集群---集群搭建成功 的基础上实现workcount案例 注意 虚拟机三台启动集群(自己亲自搭建) 1. ...
- Linux搭建Hadoop集群---Jdk配置
三台虚拟机:master slave1 slave2 192.168.77.99 master 192.168.77.88 slave1 192.168.77.77 slave2 1.修改主机名: ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- 搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的 ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
随机推荐
- form提交xml文件
--为何ajax提交不了xml?--原因:Request.Form["Data"]这种获取参数方式,原本就不是mvc路由参数获取方式,这是Asp.net中webfrom页面获取参数 ...
- Mybatis入门及于hibernate的区别
pojo:不按mvc分层,只是java bean有一些属性,还有get set方法domain:不按mvc分层,只是java bean有一些属性,还有get set方法po:用在持久层,还可以再增加或 ...
- Mysql授权root用户远程登录
默认情况下Mysql的root用户不支持远程登录,使用以下命令授权 [Charles@localhost ~]$ mysql -uroot -p123 MariaDB [(none)]> u ...
- TP无限回复
引入文件和css样式 <script src="__PUBLIC__/bootstrap/js/jquery-1.11.2.min.js"></script> ...
- React高级教程(es6)——(1)JSX语法深入理解
从根本上来说,JSX语法提供了一种创建React元素的语法糖,JSX语句可以编译成: React.createElement(component, props, …children)的形式,比如: & ...
- js实现打印
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...
- Netty源码分析之服务端启动
Netty服务端启动代码: public final class EchoServer { static final int PORT = Integer.parseInt(System.getPro ...
- Docker 搭建私有仓库
Docker 搭建私有仓库 环境: docker 版本 :18.09.1 主机地址:192.168.1.79 1.运行并创建私有仓库 docker run -d \ -v /opt/registry: ...
- 剑指offer(33)丑数
题目描述 把只包含因子2.3和5的数称作丑数(Ugly Number).例如6.8都是丑数,但14不是,因为它包含因子7. 习惯上我们把1当做是第一个丑数.求按从小到大的顺序的第N个丑数. 题目分析 ...
- bzoj 4358 Permu - 莫队算法 - 链表
题目传送门 需要高级权限的传送门 题目大意 给定一个全排列,询问一个区间内的值域连续的一段的长度的最大值. 考虑使用莫队算法. 每次插入一个数$x$,对值域的影响可以分成4种情况: $x - 1$, ...