策略梯度训练cartpole小游戏
我原来已经安装了anaconda,在此基础上进入cmd进行pip install tensorflow和pip install gym就可以了. 在win10的pycharm做的。
policy_gradient.py
# -*- coding: UTF-8 -*- """
Policy Gradient 算法(REINFORCE)。做决策的部分,相当于机器人的大脑
""" import numpy as np
import tensorflow as tf try:
xrange = xrange # Python 2
except:
xrange = range # Python 3 # 策略梯度 类
class PolicyGradient:
def __init__(self,
lr, # 学习速率
s_size, # state/observation 的特征数目
a_size, # action 的数目
h_size, # hidden layer(隐藏层)神经元数目
discount_factor=0.99 # 折扣因子
):
self.gamma = discount_factor # Reward 递减率 # 神经网络的前向传播部分。大脑根据 state 来选 action
self.state_in = tf.placeholder(shape=[None, s_size], dtype=tf.float32) # 第一层全连接层
hidden = tf.layers.dense(self.state_in, h_size, activation=tf.nn.relu) # 第二层全连接层,用 Softmax 来算概率
self.output = tf.layers.dense(hidden, a_size, activation=tf.nn.softmax) # 直接选择概率最大的那个 action
self.chosen_action = tf.argmax(self.output, 1) # 下面主要是负责训练的一些过程
# 我们给神经网络传递 reward 和 action,为了计算 loss
# 再用 loss 来调节神经网络的参数
self.reward_holder = tf.placeholder(shape=[None], dtype=tf.float32)
self.action_holder = tf.placeholder(shape=[None], dtype=tf.int32) self.indexes = tf.range(0, tf.shape(self.output)[0]) * tf.shape(self.output)[1] + self.action_holder
self.outputs = tf.gather(tf.reshape(self.output, [-1]), self.indexes) # 计算 loss(和平时说的 loss 不一样)有一个负号
# 因为 TensorFlow 自带的梯度下降只能 minimize(最小化)loss
# 而 Policy Gradient 里面是要让这个所谓的 loss 最大化
# 因此需要反一下。对负的去让它最小化,就是让它正向最大化
self.loss = -tf.reduce_mean(tf.log(self.outputs) * self.reward_holder) # 得到可被训练的变量
train_vars = tf.trainable_variables() self.gradient_holders = [] for index, var in enumerate(train_vars):
placeholder = tf.placeholder(tf.float32, name=str(index) + '_holder')
self.gradient_holders.append(placeholder) # 对 loss 以 train_vars 来计算梯度
self.gradients = tf.gradients(self.loss, train_vars) optimizer = tf.train.AdamOptimizer(learning_rate=lr)
# apply_gradients 是 minimize 方法的第二部分,应用梯度
self.update_batch = optimizer.apply_gradients(zip(self.gradient_holders, train_vars)) # 计算折扣后的 reward
# 公式: E = r1 + r2 * gamma + r3 * gamma * gamma + r4 * gamma * gamma * gamma ...
def discount_rewards(self, rewards):
discounted_r = np.zeros_like(rewards)
running_add = 0
for t in reversed(xrange(0, rewards.size)):
running_add = running_add * self.gamma + rewards[t]
discounted_r[t] = running_add
return discounted_r
play.py
# -*- coding: UTF-8 -*- """
游戏的主程序,调用机器人的 Policy Gradient 决策大脑
""" import numpy as np
import gym
import tensorflow as tf from policy_gradient import PolicyGradient # 伪随机数。为了能够复现结果
np.random.seed(1) env = gym.make('CartPole-v0')
env = env.unwrapped # 取消限制
env.seed(1) # 普通的 Policy Gradient 方法, 回合的方差比较大, 所以选一个好点的随机种子 print(env.action_space) # 查看这个环境中可用的 action 有多少个
print(env.observation_space) # 查看这个环境中 state/observation 有多少个特征值
print(env.observation_space.high) # 查看 observation 最高取值
print(env.observation_space.low) # 查看 observation 最低取值 update_frequency = 5 # 更新频率,多少回合更新一次
total_episodes = 3000 # 总回合数 # 创建 PolicyGradient 对象
agent = PolicyGradient(lr=0.01,
a_size=env.action_space.n, # 对 CartPole-v0 是 2, 两个 action,向左/向右
s_size=env.observation_space.shape[0], # 对 CartPole-v0 是 4
h_size=8) with tf.Session() as sess:
# 初始化所有全局变量
sess.run(tf.global_variables_initializer()) # 总的奖励
total_reward = [] gradient_buffer = sess.run(tf.trainable_variables())
for index, grad in enumerate(gradient_buffer):
gradient_buffer[index] = grad * 0 i = 0 # 第几回合
while i < total_episodes:
# 初始化 state(状态)
s = env.reset() episode_reward = 0
episode_history = [] while True:
# 更新可视化环境
env.render() # 根据神经网络的输出,随机挑选 action
a_dist = sess.run(agent.output, feed_dict={agent.state_in: [s]})
a = np.random.choice(a_dist[0], p=a_dist[0])
a = np.argmax(a_dist == a) # 实施这个 action, 并得到环境返回的下一个 state, reward 和 done(本回合是否结束)
s_, r, done, _ = env.step(a) # 这里的 r(奖励)不能准确引导学习 x, x_dot, theta, theta_dot = s_ # 把 s_ 细分开, 为了修改原配的 reward # x 是车的水平位移。所以 r1 是车越偏离中心, 分越少
# theta 是棒子离垂直的角度, 角度越大, 越不垂直。所以 r2 是棒越垂直, 分越高
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2 # 总 reward 是 r1 和 r2 的结合, 既考虑位置, 也考虑角度, 这样学习更有效率 episode_history.append([s, a, r, s_]) episode_reward += r
s = s_ # Policy Gradient 是回合更新
if done: # 如果此回合结束
# 更新神经网络
episode_history = np.array(episode_history) episode_history[:, 2] = agent.discount_rewards(episode_history[:, 2]) feed_dict = {
agent.reward_holder: episode_history[:, 2],
agent.action_holder: episode_history[:, 1],
agent.state_in: np.vstack(episode_history[:, 0])
} # 计算梯度
grads = sess.run(agent.gradients, feed_dict=feed_dict) for idx, grad in enumerate(grads):
gradient_buffer[idx] += grad if i % update_frequency == 0 and i != 0:
feed_dict = dictionary = dict(zip(agent.gradient_holders, gradient_buffer)) # 应用梯度下降来更新参数
_ = sess.run(agent.update_batch, feed_dict=feed_dict) for index, grad in enumerate(gradient_buffer):
gradient_buffer[index] = grad * 0 total_reward.append(episode_reward)
break # 每 50 回合打印平均奖励
if i % 50 == 0:
print("回合 {} - {} 的平均奖励: {}".format(i, i + 50, np.mean(total_reward[-50:]))) i += 1
启动训练:
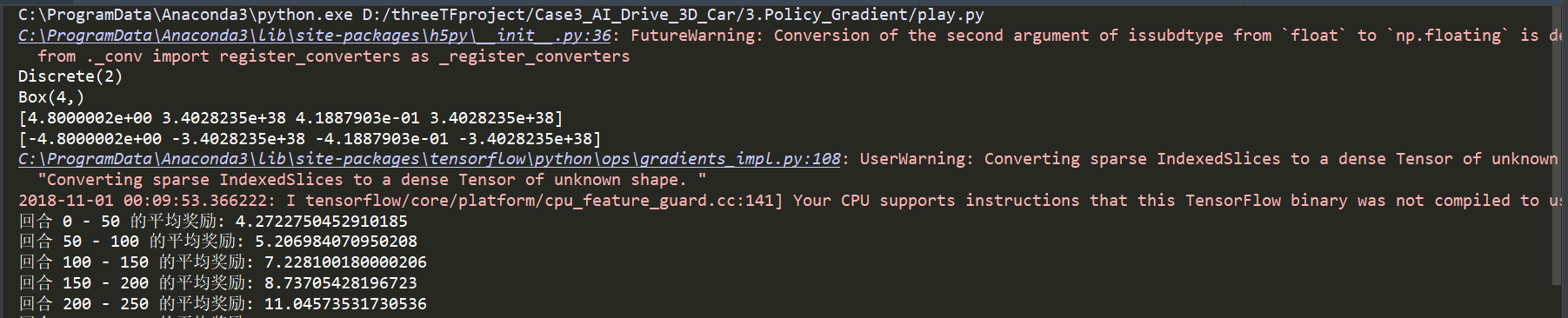
会报一些警告,不用理会,训练到奖励大概有300分的时候,就比较稳定了,能较好的平衡杠子了
还有另外一个游戏Mountain-car小游戏也可以基于策略梯度来做, 这个小游戏的说明见“基于核方法的强化学习算法-----何源,张文生”里面有一段说明了这个小游戏:

这个具体的实现下回继续。。。
策略梯度训练cartpole小游戏的更多相关文章
- 微信小游戏 RES版本控制+缓存策略 (resplugin和ResSplitPlugin插件使用)
参考: RES版本控制 使用 AssetsManager 灵活定制微信小游戏的缓存策略 一.我们的目标 目标就是让玩家快速进入游戏,然后根据游戏的进度加载相应的资源,并可对资源进行版本控制.本地缓存. ...
- lecture6-mini批量梯度训练及三个加速的方法
Hinton的第6课,这一课中最后的那个rmsprop,关于它的资料,相对较少,差不多除了Hinton提出,没论文的样子,各位大大可以在这上面研究研究啊. 一.mini-批量梯度下降概述 这部分将介绍 ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习_PolicyGradient(策略梯度)_代码解析
使用策略梯度解决离散action space问题. 一.导入包,定义hyper parameter import gym import tensorflow as tf import numpy as ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- 软件工程 Android小游戏 猜拳大战
一.前言 最近学校举办的大学生程序设计竞赛,自己利用课余时间写了一个小游戏,最近一直在忙这个写这个小游戏,参加比赛,最终是老师说自己写的简单,可以做的更复杂的点的.加油 二.内容简介 自己玩过Andr ...
- [安卓] 12、开源一个基于SurfaceView的飞行射击类小游戏
前言 这款安卓小游戏是基于SurfaceView的飞行射击类游戏,采用Java来写,没有采用游戏引擎,注释详细,条理比较清晰,适合初学者了解游戏状态转化自动机和一些继承与封装的技巧. 效果展示 ...
- 2048小游戏代码解析 C语言版
2048小游戏,也算是风靡一时的益智游戏.其背后实现的逻辑比较简单,代码量不算多,而且趣味性强,适合作为有语言基础的童鞋来加强编程训练.本篇分析2048小游戏的C语言实现代码. 前言 游戏截图: 游 ...
- C语言实现简易2048小游戏
一直很喜欢玩这个小游戏,简单的游戏中包含运气与思考与策略,喜欢这种简约又不失内涵的游戏风格.于是萌生了用C语言实现一下的想法. 具体代码是模仿这个:https://www.cnblogs.com/ju ...
随机推荐
- Select2 多层次赋值时异步赋值的问题
场景: 当选择人员时加载人员,选择部门时加载部门.所以在人员下,选择人员A后,如果选择部门,会触发二级select 重新获取数据. 问题: 使用select2()方法进行绑定远程数据后,对第二个sel ...
- 期货大赛项目|三,autofac简单用法
autofac是依赖注入 我们以前要引入一个dal层,是这么写的 private IDal _dao = new Dal() 我们可以看得出,这样写,我们的bll层不光依赖了接口IDal,还依赖了Da ...
- 详解 Java 中的三种代理模式
代理模式 代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式;即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能. 这里使用 ...
- noi2016旷野大作战
玩了差不多两个小时61分 大概第9个点可以再拿5-6分 但是挺麻烦的并不想搞.. 这道题还是比较考验智商的??以及对那个特殊的ln函数的应用 感觉题目出的挺好的 看了题解 发现第4个点的确我应该想不到 ...
- python多线程之t.setDaemon(True) 和 t.join()
0.目录 1.参考2.结论 (1)通过 t.setDaemon(True) 将子线程设置为守护进程(默认False),主线程代码执行完毕后,python程序退出,无需理会守护子线程的状态. ...
- Nginx的配置与部署研究,Upstream负载均衡模块
Nginx 的 HttpUpstreamModule 提供对后端(backend)服务器的简单负载均衡.一个最简单的 upstream 写法如下: upstream backend { server ...
- web项目部署以及放到ROOT目录下
最近度过了一个国庆长假,好几天都没有写博客了! 发布这篇案例也是希望能帮助到像我一样的菜鸟o(* ̄︶ ̄*)o,百度上面的资料都不怎么全.也没有人说明注意事项.总是这篇说一点.那个人也说补一点,最后自己 ...
- 做生活的有心人——xxx系统第一阶段总结
2017秋,桃子已经步入大学三年级了,觉得格外幸运 因为现在,有了学习的动力. 如果你和我一样也是在大学中后部分才意识到,自己是个大人了,思维模式开始转变开始融入一些前所未有的认知,觉得自己渺小得如沧 ...
- QT +go 开发 GUI程序
,转载 https://blog.csdn.net/lanbery/article/details/81745611 如果你是一个墨守成规的coding,请移步其他内容,这部分内容可能不适合你.如 ...
- Tree Reconstruction Gym - 101911G(构造)
---恢复内容开始--- Monocarp has drawn a tree (an undirected connected acyclic graph) and then has given ea ...