深入理解Linux内核——内存管理(1)
提要:本系列文章主要参考MIT 6.828课程以及两本书籍《深入理解Linux内核》 《深入Linux内核架构》对Linux内核内容进行总结。
内存管理的实现覆盖了多个领域:
- 内存中的物理内存页的管理
- 分配大块内存的伙伴系统
- 分配较小内存的slab、slub、slob分配器
- 分配非连续内存块的vmalloc分配器
- 进程的地址空间
传统的内存管理主要包括段式存储、页式存储、段页式存储,这里我们会以这部分开始,逐步介绍Linux内核中的内存管理,而要学习内存管理,首先需要了解内存寻址。所以本节内容主要讲解内存寻址的相关知识,并介绍Linux内核中的段、页式存储。
内存地址
在编程过程中,难免需要通过内存地址来访问内存中的某些内容,那么这个过程中地址是如何映射到对应的物理单元的呢?解决这一问题首先要区分三种不同的地址:
- 逻辑地址:逻辑地址是包含在机器语言指令中用来指定一个操作数或者一条指令的地址。
每一个逻辑地址都由一个段和一个偏移量组成,偏移量指明了从段开始的地方到实际地址之间的距离。(这在分段结构中表现的极为明显)。 - 线性地址:线性地址是一个32位的无符号数,可以用来表示高达4GB的地址。线性地址通常使用十六进制数字表示,值的范围从0x00000000到0xffffffff(常用于页式存储)。
- 物理地址:
用于内存芯片级内存单元寻址。它们与微处理器的地址引脚发送到内存总线上的电信号相对应。物理地址由32位或36位无符号整数表示。
内存控制单元(MMU)通过分段单元(硬件设备)将逻辑地址转化为线性地址。使用分页单元(硬件设备)把线性地址转化为物理地址:
-------- -------
|逻辑地址| --> |分段单元| --> |线性地址| --> |分页单元| --> |物理地址|
-------- -------
从格式上简单区别逻辑地址与线性地址,逻辑地址包含了两部分:段和偏移量(注意这两者是分开的),而线性地址知识一个32位无符号数,虽然后期也会根据地址的位数再次进行划分(详见分页部分),但终归只是一个线性的无符号数。
段式存储
硬件将逻辑地址转化为线性地址主要由分段单元完成该任务。逻辑地址由两部分组成:
- 段标识符:该字段是一个16位长的字段,称为
段选择符,负责从众多段中选择出正确的段,因为段信息会存储在一张段描述符表中,因此需要通过段选择符从段描述符表中索引找到正确的段描述符。 - 指定段内相对地址的偏移量:32位长的字段(因为一个段可能很长,因此偏移量要足够大)
段选择符格式如下:
15 3 2 1 0
-------- ---- ---
段选择符 | index | TL | RPL|
-------- ---- ---
对于每个字段的含义,后续在详细讲解通过段选择符寻找对应段时会对每个字段给出解释。
段选择符被存放在段寄存器中,这使得可以方便快速地找到段选择符,段寄存器主要包括6个,分别为cs,ss,ds,es,fs,gs。其中有3个具有专门的用途:
| 段寄存器 | 描述 |
|---|---|
| cs | 代码段寄存器,指向包含指令序列的段 |
| ss | 栈段寄存器,指向包含当前程序栈的段 |
| ds | 数据段寄存器,指向包含静态数据或者全局数据段 |
其他3个段寄存器作一般用途,可以指向任意的数据段。
注意:cs寄存器还有一个很重要的功能:它含有一个两位的字段,用以指明CPU的当前特权级(GPL)。值为0代表最高优先级,而值为3代表最低优先级。Linux只用0级和3级,分别称为内核态和用户态。
段描述符
刚才提到过,每个段由一个8字节的段描述符表示,它描述了段的特征。段描述符放在全局描述符表(GDT)或者局部描述符表里(LDT)中(前面提到过)。通常只定义一个GDT,而每个进程除了存放在GDT中的段之外如果还需要创建附加段,就会创建自己的LDT。GDT在主存中的地址和大小存放在gdtr控制寄存器中,当前正被使用的LDT地址和大小存放在ldtr寄存器中。如下给出一个全局段描述符例子:
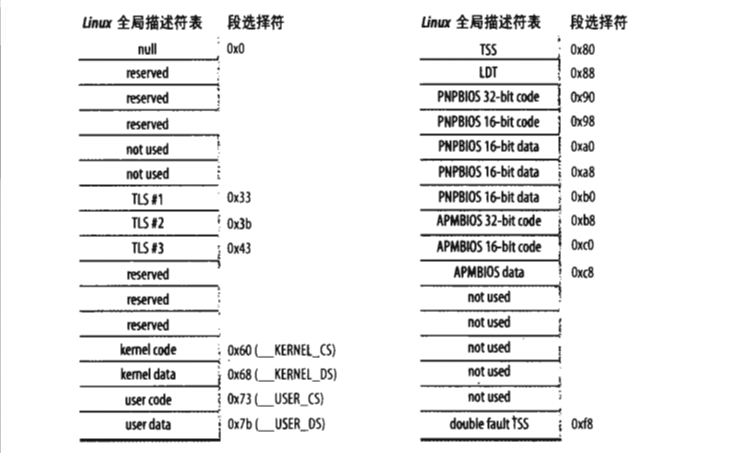
在段描述符表中通常会使用如下几种段描述符(简单了解各个段的作用即下面第一个表就好,具体字段的名称可以用到再回来查):
| 描述符名称 | 描述 |
|---|---|
| 代码段描述符 | 这个段描述符代表一个代码段,它可以放在GDT或LDT中。该描述符置S标志位1(非系统段) |
| 数据段描述符 | 这个段描述符代表一个数据段,它可以放在GDT或LDT中。该描述符置S标志为1。栈段是通过一般的数据段实现的。 |
| 任务状态段描述符(TSSD) | 这个段描述符代表一个任务状态段(Task State Segment, TSS),也就是说这个段用于保存处理器寄存器的内容。它只能出现在GDT中。根据相应的进程是否正在CPU上运行,其Type字段的值分别为11或9。这个描述符的S标志置为0。 |
| 局部描述符表描述符(LDTD) | 这个段描述符代表一个包含LDT的段,它只出现在GDT中。相应的Type字段的值为2,s标志置为0 |
段描述符格式如下:
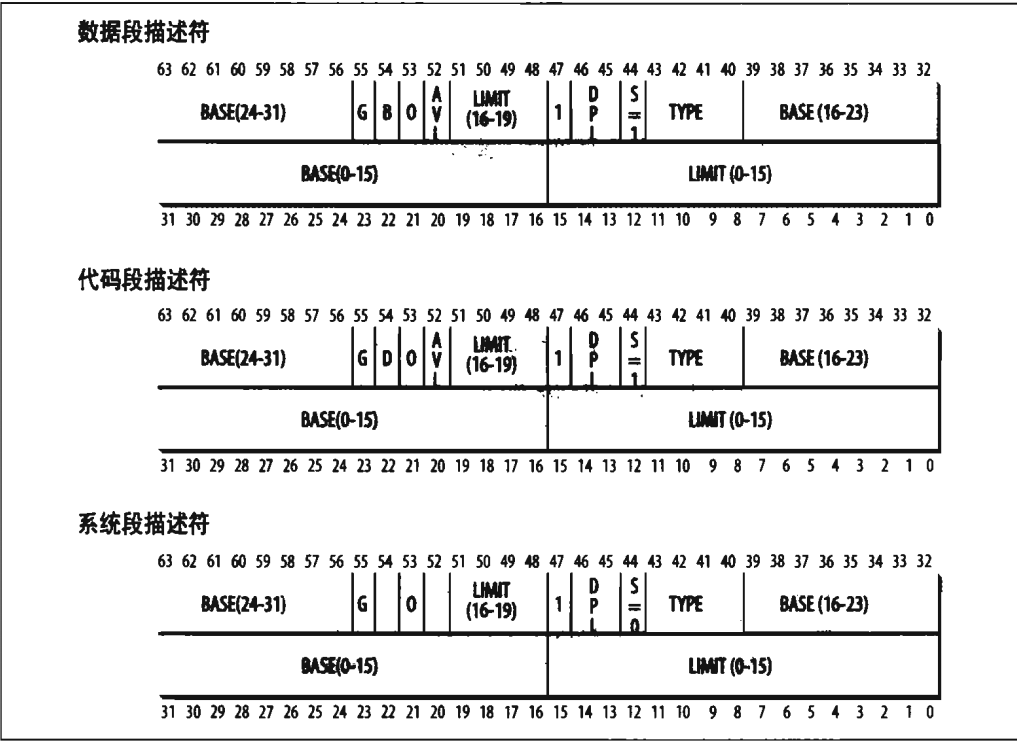
段描述符中各个字段含义如下:
| 字段表 | 描述 |
|---|---|
| Base | 包含段的首字节的线性地址 |
| G | 粒度标志:如果该位清0,则段大小以字节为单位,否则以4096的倍数计 |
| Limit | 存放段中最后一个内存单元的偏移量,从而决定段的长度。如果G被置为0,则一个段的大小在1个字节到1MB之间变化;否则,则在4KB到4GB之间变化。 |
| S | 系统标志:如果它被清0,则这是一个系统段,存储诸如LDT这种关键的数据结构,否则它是一个普通的代码段或者数据段。 |
| Type | 描述了段的类型特征和他的存取权限 |
| DPL | 描述符特权级(Descriptor Privilege Level)字段:用于限制对这个段的存取。它表示为访问这个段而要求的CPU最小的优先级。因此,DPL设为0的段只能当CPL为0时(即在内核态)才是可以访问的,而DPL设为3的段对任何CPL值都是可以访问的。 |
| P | Segment-Present标志:等于0表示段当前不在主存中。Linux总是把这个标志(第47位)设为1,因为它从来不把整个段交换到磁盘上去。 |
| D或B | 成为D或B的标志,取决于是代码段还是数据段。D或B的含义在两种情况下稍微有区别,但是如果段偏移量的地址是32位长,就基本上把它置为1,如果这个偏移量是16位长,它被清0。 |
| AVL标志 | 可以由操作系统使用,但是被Linux忽略 |
快速访问段描述符
在本节主要介绍分段单元将逻辑地址转化为线性地址的过程。我们知道逻辑地址主要包括:16位的段选择符和32位的段偏移量,段选择符存放在段寄存器中。段选择符格式如下:
15 3 2 1 0
-------- ---- ---
段选择符 | index | TL | RPL|
-------- ---- ---
这里我们需要了解3个字段的含义:
| 字段名 | 描述 |
|---|---|
| index | 指定了放在GDT或者LDT中相应的段描述符的入口 |
| TI | TI(Table Indicator)标志:指明段描述符是在GDT中(TI = 0)或在LDT中(TI=1) |
| RPL | 请求者特权级:当相应的段选择符装入到cs寄存器中时指示出CPU当前的特权级;它还可以用于在访问数据段时有选择地削弱处理器的特权级。 |
由于一个段描述符是8个字节长,因此它在GDT或LDT内的相对地址是由段选择符的最高13位的值乘以8得到的(8=2^3,13+3=16)。例如如果GDT在0x00020000(这个值保存在gdtr寄存器中),切由段选择符所指定的索引号为2,那么相应的段描述符地址为0x00020000+(2*8)即0x00020010。
逻辑地址转换为线性地址流程如下图:

- 先检查段选择符的
TI字段,以确定段描述符保存在哪一个描述符表(GDT、LDT)中。 - 从段选择符的index字段计算段描述符的地址,index字段值乘以8(一个段描述符大小),这个结果与gdtr或ldtr寄存器中的内容相加
- 把逻辑地址的偏移量与段描述符的
Base字段的值相加就得到了线性地址。
操作系统课本中的介绍通常如下,可以与之进行对比:
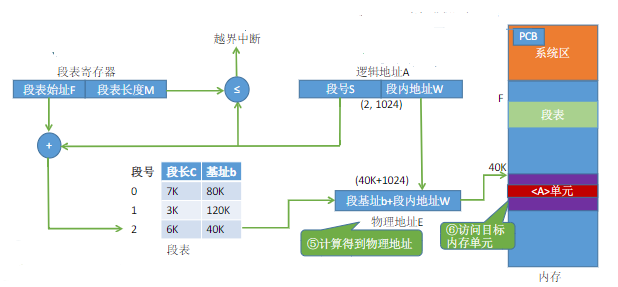
注意:GDT的第一项总是设置为0。这就确保空段选择符的逻辑地址会被认为是无效的,因此引起一个处理器异常。能够保存在GDT中的段描述符的最大数目是8191,即2^13-1。
最后,由于整个地址转换过程中,前两个过程,即访问GDT、LDT中段描述符的过程是比较耗时的,为了加速该过程,80x86处理器提供了一种附加的非编程的寄存器供6个可编程的段寄存器使用。每个非编程寄存器含有8个字节的段描述符。通过这个非编程寄存器,达到了如下功能:每当一个段描述符被装入段寄存器时,相应的段描述符就由内存装入到对应的非编程CPU寄存器中,从那时起,针对那个段的逻辑地址转换就可以不访问主存中的GDT或LDT,只有在段寄存器内容改变时,才有必要访问GDT或LDT。
Linux中的分段
Linux以非常有限的方式使用分段,分段可以给一个进程分配不同的线性地址空间,而分页可以把同一线性地址空间映射到不同的物理空间,与分段相比,Linux更喜欢使用分页方式,因为:
- 当所有进程使用相同的段寄存器时,内存管理变得更简单,也就是说他们能共享同样的一组线性地址。
- Linux设计目标之一时可以把它移植到绝大多数的处理器平台上。然而,RISC体系结构对分段的支持很有限。
2.6版的Linux只有在80x86结构下才需要使用分段。
运行在用户态的所有Linux进程都使用一对相同的段来对指令和数据寻址。这两个段就是所谓的用户代码段和用户数据段。类似的运行在内核态的所有Linux进程都使用一对相同的段对指令和数据寻址,他们分别是内核代码段和内核数据段。下表显示了这四个重要段的段描述符字段的值。
| 段 | Base | G | Limit | S | Type | DPL | D/B | P |
|---|---|---|---|---|---|---|---|---|
| 用户代码段 | 0x00000000 | 1 | 0xfffff | 1 | 10 | 3 | 1 | 1 |
| 用户数据段 | 0x00000000 | 1 | 0xfffff | 1 | 2 | 3 | 1 | 1 |
| 内核代码段 | 0x00000000 | 1 | 0xfffff | 1 | 10 | 0 | 1 | 1 |
| 内核数据段 | 0x00000000 | 1 | 0xfffff | 1 | 2 | 0 | 1 | 1 |
上面4个段,G标志都设置为1,即limit以4096为单位。与段相关的线性地址从0开始,达到2^32-1的寻址限长,这意味着在用户态或内核态下的所有进程可以使用相同的逻辑地址。
所有段都从0x00000000开始,表示Linux下逻辑地址和线性地址是一致的,即逻辑地址的偏移量字段的值与相应的线性地址的值总是一致的。
那如何区分这4个段呢?
如前所述,CPU的当前特权级(CPL)反映了进程是在用户态还是内核态,并由存放在cs寄存器中的段选择符的RPL字段指定。只要当前特权级被改变,一些段寄存器必须相应地更新。例如,当CPL=3时(用户态),ds寄存器必须含有用户数据段的段选择符,而当CPL=0时,ds寄存器必须含有内核数据段的段选择符。
页式存储
分页单元(paging unit)把线性地址转换成物理地址。其中的一个关键任务是把所请求的访问类型与线性地址的访问权限项比较,如果这次内存访问是无效的,就产生一个缺页异常。
为了效率起见,线性地址被分成以固定长度为单位的组,称为页(page)。页内部连续的线性地址被映射到连续的物理地址中。这样,内核可以指定一个页的物理地址和其存储权限,而不用指定页所包含的全部线性地址的存取权限。
分页单元把所有的RAM分成固定长度的页框(有时叫做物理页)。每一个页框包含一个页(page),也就是说一个页框的长度与一个页的长度一致。页框是主存的一部分,因此也是一个存储区域。
把线性地址映射到物理地址的数据结构称为页表。页表存放在主存中,并在启动分页单元之前必须由内核对页表进行适当的初始化。
从80386开始,所有的80x86处理器都支持分页,它通过设置cr0寄存器的PG标志启用。当PG=0时,线性地址就被解释成物理地址。
常规分页
从80386起,Intel处理器的分页单元处理4KB的页。
32位的线性地址被分为3个域(线性地址是根据位数划分的,是隐式划分的功能):
Directory(目录):最高10位。Table(页表):中间10位。Offset(偏移量):最低12位。
线性地址转换为物理地址时,需要依赖两张表:页目录表和页表。转换过程如下图:
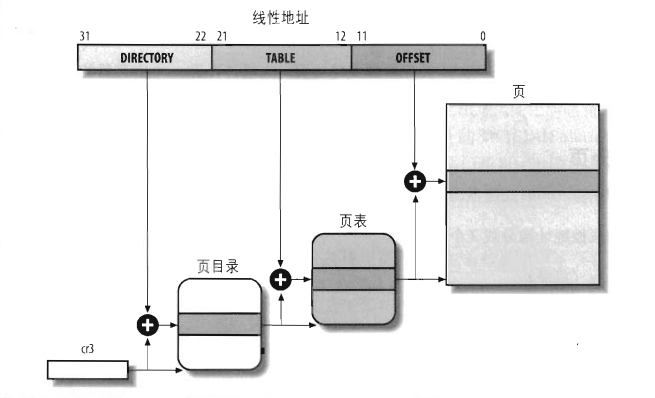
每个活动进程必须有一个分配给它的页目录,正在使用的页目录的物理地址存放在控制寄存器cr3中。线性地址内的Directory字段决定页目录表中的目录项,而目录项指向适当的页表。地址的Table字段依次又决定页表中的表项,而表项含有页所在页框的物理地址。Offset字段决定页框内的相对位置,由于它是12位长,故每一页含有4096字节的数据。
页目录项表和页表中的每项具有相同的结构(可以先暂时跳过,碰到使用的字段可以再回来看),每项字段如下:
| 标志 | 描述 |
|---|---|
| Present标志 | 如果被置为1,所指的页(或页表)就在主存中。如果该标志为0,则这一页不在主存中,此时这个表剩余的位可由操作系统用于自己的目的。如果执行一个地址转换所需的页表项或页目录项中的Present标志被清0,那么分页单元就把该线性地址存放在控制寄存器cr2中,并产生14号异常:缺页异常。 |
| 包含页框物理地址最高20位的字段 | 由于每一个页框有4KB的容量,它的物理地址必须是4096的倍数,因此物理地址的最低12位总是为0。如果这个字段指向一个页目录,相应的页框就含有一个页表,如果它指向一个页表,相应的页框就含有一页数据。 |
| Accessed标志 | 每当分页单元对应页框进行寻址时就设置这个标志。当选出的页被交换出去时,这一标志就可以由操作系统使用。分页单元从来不重置这个标志,而是必须由操作系统去做。 |
| Dirty标志 | 只应用于页表项中。每当对一个页框进行写操作时就设置这个标志。与Accessed标志一样,当选中的页被交换出去时,这一标志就可以由操作系统使用。分页单元从来不重置这个标志,而是必须由操作系统去做。 |
| Read/Write标志 | 含有页或页表的存取权限(Read/Write或Read)。 |
| User/Superisor标志 | 含有访问页或页表所需的特权级。 |
| PCD和PWT标志 | 控制硬件告诉缓存处理页或页表的方式。 |
| Page Size标志 | 只应用于页目录项。如果设置为1,则页目录项指的是2MB或4MB的页框。 |
| Global标志 | 只应用于页表项。这个标志时在Pentium Pro中引入的,用来防止常用页从TLB(快表)高速缓存中刷新出去。只有在cr4寄存器的页全局启动(PGE)标志置位时这个标志才起作用。 |
这里再简单强调一个问题,为何要使用多级页表:
常规分页的加速策略
当今的微处理器时钟频率接近几个GHz,而动态RAM(DRAM)芯片的存取时间是时钟周期的数百倍。这意味着,当从RAM中取操作数或向RAM中存放结果这样的指令执行时,CPU可能等待很长时间。
硬件高速缓存
为了缩小CPU和RAM之间的速度不匹配,引入了硬件高速缓存内存(hardware cache memory)。硬件高速缓存基于著名的局部性原理(locality principle),它表明由于程序的循环结构及相关数组可以组织成线性数组,最近最常用的相邻地址在最近的将来又被用到的可能性极大。80x86体系结构中引入了一个叫行(line)的新单位。行由几十个连续的字节组成,它们以脉冲突发模式(burst mode)在慢速DRAM和快速的用来实现告诉缓存的片上静态RAM(SRAM)之间传送,用来实现高速缓存。
高速缓存再被细分为行的子集。在一种极端的情况下,高速缓存可以是直接映射的(direct mapped),这时主存中的一个行总是存放在高速缓存中完全相同的位置。在另一种极端情况下,高速缓存是充分关联的(fully associative),这意味着主存中的任意一个行可以存放在高速缓存中的任意位置。但是大多数高速缓存在某种程度上是N-路组关联的(N-way set associative),意味着主存中的任意一个行可以存放在高速缓存N行中的任意一行中。例如,内存中的一个行可以存放到一个2路组关联高速缓存两个不同的行中。
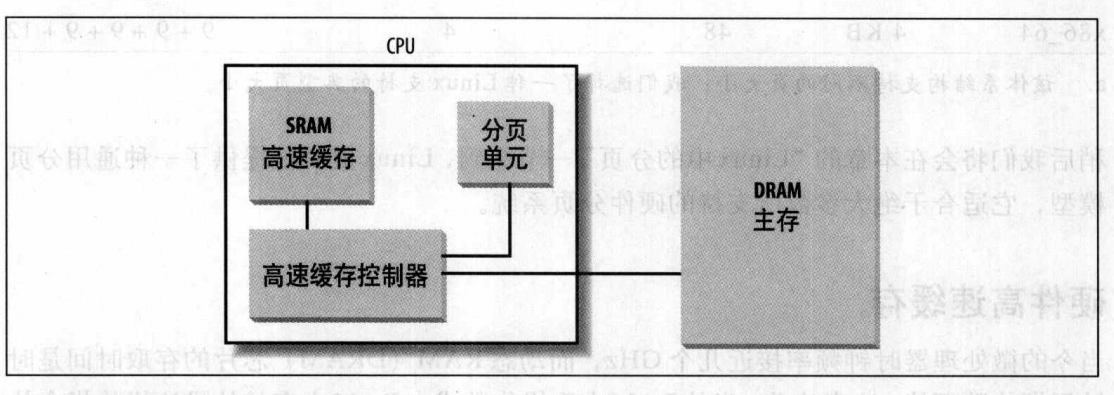
如下图,硬件高速缓存由两部分组成:
- 硬件高速缓存内存:负责存放真正的行
- 高速缓存控制器:存放一个表项数组,每个表项对应高速缓存内存中的一个行。每个表项有一个标签(tag)和描述高速缓存行状态的几个标志(flag)。这个标签由一些位组成,这些位让高速缓存控制器能够辨别由这个行当前所映射的内存单元。这种
内存物理地址通常分为3组:最高几位对应标签,中间几位对应高速缓存控制器的子集索引,最低几位对应行内的偏移量。
这里引用链接中的一部分描述,对内存物理地址进行描述(否则后续的高速缓存访问过程可能比较难以看懂):
访问cache时,访问地址可分为3个部分:偏移量Offset、索引Index和标签Tag。
- Offset是块内地址,在地址的低几位,因为cache块一般比较大,如每个cache块32字节或64字节。以32个字节为例,读cache时把32个字节即256位作为一组一起都读出来,用Offset在32字节中选择本次访问所需的字或双字等;
- Index用来索引cache,访问时用Index作为访问cache的地址。
- 地址的高位是访问cache的Tag,由于cache的大小有限,每个cache行可能对应内存中的若干个存储块,cache中的每一行都要用tag来标识当前存的是哪个存储块,访问时用地址的Tag跟cache存的tag进行比较,如果相等就给出命中信号hit。
了解了上面的内容,原书中的高速缓存访问过程就可以很容易看懂了:
- 当访问一个RAM存储单元时,CPU从物理地址中提取出子集的
索引号并把子集中所有行的标签与物理地址的高几位相比较。 - 如果发现某一个行的
标签与这个物理地址的高位相同,则CPU命中一个高速缓存(cache hit);否则,高速缓存没有命中(cache miss)。
最后给出了查找到高速缓存中具体内容后的一些后操作:
当命中一个高速缓存时,高速缓存控制器进行不同的操作,具体取决于存储类型。
- 对于
读操作,控制器从高速缓存行中选取数据并送到CPU寄存器;不需要访问RAM而节约了CPU时间。因此高速缓存系统起到了其应有的作用。 - 对于
写操作,控制器可能采用以下两个基本策略之一,分别称之为通写和回写。- 在
通写中,控制器总是既写RAM也写高速缓存行,为了提高写操作的效率关闭高速缓存。 回写方式只更新高速缓存行,不改变RAM的内容,提供了更快的功效。当然,回写结束后,RAM最终必须被更新。只有当CPU执行一条要求刷新高速缓存表项的指令时,或者当一个FLUSH硬件信号产生时(通常在高速缓存不命中之后),高速缓存控制器才把高速缓存行写回到RAM中。
- 在
当高速缓存没有命中时,高速缓存行被写回到内存中,如果有必要的话,吧正确的行从RAM中取出放到高速缓存的表项中。
页目录项表和页表中的每项具有相同的结构 中PCD和PWT两个标志用于控制上述操作:
- PCD(Page Cache Disabit)标志指明当访问包含在这个页框中的数据时,高速缓存功能必须被启用还是禁用。
- PWT(page Write-Through)标志指明当把数据写到页框时,必须使用的策略是回写策略还是通写策略。
最后给出一个链接,较为详细的介绍了硬件高速缓存,如果感兴趣可以继续了解。
转换后援缓冲器(TLB)
注意:这个TLB不是Thread Local Buffer。
除了通用硬件高速缓存之外,80x86处理器还包含了另一个称为转换后援缓冲器或TLB(Translation Lookaside Buffer)的高速缓存用于加快线性地址的转换。当一个线性地址被第一个使用时,通过慢速访问RAM中的页表计算出相应的物理地址。同时物理地址被存放在一个TLB表项(TLB entry)中,以便以后对同一个线性地址的引用可以快速地得到转换。
在多处理器系统中,每个CPU都有自己的TLB,这叫做该CPU的本地TLB。与硬件高速缓存相反,TLB中的对应项不必同步,这是因为运行在现有CPU上的进程可以使同一线性地址与不同的物理地址发生联系。
当CPU的cr3控制寄存器被修改时,硬件自动使本地TLB中的所有项都无效,这是因为新的一组页表被启用而TLB指向的是旧数据。
64位系统中的分页
通过上面我们可以看到32位系统使用两级分页就可以满足需求,那64位系统呢?
首先假设一个大小为4KB的标准页。因为1KB覆盖210个地址的范围,4KB覆盖212个地址,所以offset字段是12位。这样线性地址就剩下52位分配给Table和Directory字段。如果我们现在决定仅仅使用64位中的48位来寻址(这个限制仍然使我们自在地拥有256TB的寻址空间!),剩下的48-12=36位将被分配给Table和Directory字段。如果我们现在决定为两个字段各预留18位,那么每个进程的页目录和页表都含有2^18个项,即超过256000个项,而一页无法放下如此多的页目录项和页表项。
因此,所有64位处理器的硬件分页系统都使用了额外的分页级别。使用的级别数量取决于处理器的类型。下表总结出了一些Linux支持64位平台使用的硬件分页系统的主要特征:
| 平台名称 | 页大小 | 寻址使用的位数 | 分页级别数 | 线性地址分级 |
|---|---|---|---|---|
| alpha | 8KB | 43 | 3 | 10+10+10+13 |
| ia64 | 4KB | 39 | 3 | 9+9+9+12 |
| x86_64 | 4KB | 48 | 4 | 9+9+9+9+12 |
Linux本身提供了一种通用的分页系统,它适用于绝大多数所支持的硬件分页系统。
Linux的分页
Linux采用了一种同时适用于32位和64位系统的普通分页模型。到2.6.10版本,Linux采用三级分页的模型。从2.6.11版本开始,采用了四级分页模型,分为4种页表如下:
- 页全局目录(Page Global Directory)
- 页上级目录(Page Upper Directory)
- 页中间目录(Page Middle Directory)
- 页表(Page Table)
结构如下图:

页全局目录包含若干页上级目录的地址,页上级目录又依次包含若干页中间目录的地址,而页中间目录又包含若干页表地址。因此线性地址被分成五个部分。上图没有显示位数,因为每一部分的大小与具体的计算机体系结构有关。
对于没有启用物理地址扩展的32位系统,两级页表已经足够了。Linux通过使“页上级目录”位和“页中间目录”位全为0,从根本上取消了页上集目录和页中间目录字段。不过,页上级目录和页中间目录在指针序列中的位置被保留,以便同样的代码在32位系统和64位系统下都能使用。内核为页上集目录和页中间目录保留了一个位置,这是通过把它们的页目录项数设置为1,并把这两个目录项映射到全局目录一个适当的目录而实现的。
总结
本篇文章主要讲解内存地址转换的主要内容,并对Linux内核对段式存储和页式存储进行了简单的了解,下一篇文章将开始进行真正内存管理相关的内容。
深入理解Linux内核——内存管理(1)的更多相关文章
- Linux内核内存管理算法Buddy和Slab: /proc/meminfo、/proc/buddyinfo、/proc/slabinfo
slabtop cat /proc/slabinfo # name <active_objs> <num_objs> <objsize> <objpersla ...
- 深入理解Linux中内存管理
前一段时间看了<深入理解Linux内核>对其中的内存管理部分花了不少时间,但是还是有很多问题不是很清楚,最近又花了一些时间复习了一下,在这里记录下自己的理解和对Linux中内存管理的一些看 ...
- linux内核 内存管理
以下内容汇总自网络. 在早期的计算机中,程序是直接运行在物理内存上的.换句话说,就是程序在运行的过程中访问的都是物理地址. 如果这个系统只运行一个程序,那么只要这个程序所需的内存不要超过该机器的物理内 ...
- Linux内核内存管理架构
内存管理子系统可能是linux内核中最为复杂的一个子系统,其支持的功能需求众多,如页面映射.页面分配.页面回收.页面交换.冷热页面.紧急页面.页面碎片管理.页面缓存.页面统计等,而且对性能也有很高的要 ...
- linux内核内存管理(zone_dma zone_normal zone_highmem)
Linux 操作系统和驱动程序运行在内核空间,应用程序运行在用户空间,两者不能简单地使用指针传递数据,因为Linux使用的虚拟内存机制,用户空间的数据可能被换出,当内核空间使用用户空间指针时,对应的数 ...
- 【Linux】深入理解Linux中内存管理
主题:Linux内存管理中的分段和分页技术 回顾一下历史,在早期的计算机中,程序是直接运行在物理内存上的.换句话说,就是程序在运行的过程中访问的都是物理地址. 如果这个系统只运行一个程序,那么只要这个 ...
- Linux内核——内存管理
内存管理 页 内核把物理页作为内存管理的基本单位.内存管理单元(MMU,管理内存并把虚拟地址转换为物理地址)通常以页为单位进行处理.MMU以页大小为单位来管理系统中的页表. 从虚拟内存的角度看,页就是 ...
- Linux内核内存管理子系统分析【转】
本文转载自:http://blog.csdn.net/coding__madman/article/details/51298718 版权声明:本文为博主原创文章,未经博主允许不得转载. 还是那张熟悉 ...
- Linux内核内存管理
<Linux内核设计与实现>读书笔记(十二)- 内存管理 内核的内存使用不像用户空间那样随意,内核的内存出现错误时也只有靠自己来解决(用户空间的内存错误可以抛给内核来解决). 所有内核 ...
- linux内核--内存管理(二)
一.进程与内存 所有进程(执行的程序)都必须占用一定数量的内存,它或是用来存放从磁盘载入的程序代码,或是存放取自用户输入的数据等等.不过进程对这些内存的管理方式因内存用途不一而不尽相同,有些内 ...
随机推荐
- 回溯理论基础及leetcode例题
学习参考 回溯 与递归相辅相成;回溯是递归的副产品,只要有递归就会有回溯. 回溯函数也就是递归函数,指的都是一个函数. 回溯搜索法 纯暴力搜索 解决的问题 组合问题:N个数里面按一定规则找出k个数的集 ...
- .Net8顶级技术:IR边界检查之IR解析(二)
前言 IR技术应用在各个编程语言当中,它属于JIT的核心部分,确实有点点麻烦.但部分基本明了.本篇通过小例子了解下.前情提要,看这一篇之前建议看看前一篇:点击此处,以便于理解. 概括 1.前奏 先上C ...
- Module build failed: Error: Plugin/Preset files are not allowed to export objects, only functions.
运行项目是提示Module build failed: Error: Plugin/Preset files are not allowed to export objects, only funct ...
- WPF中登录接口
通过获取文本将json字符串转化成对象并做好相应的匹配 步骤 获取相应的文本 json字符串转化对象 json转化成实体类 参考链接:https://www.sojson.com/json2cshar ...
- CMU15445 (Fall 2020) 数据库系统 Project#3 - Query Execution 详解
前言 经过前两个实验的铺垫,终于到了执行 SQL 语句的时候了.这篇博客将会介绍 SQL 执行计划实验的实现过程,下面进入正题. 总体架构 一条 SQL 语句的处理流程可以归纳为: SQL 被 Par ...
- 基于DSP的设备振动信号的采集技术方案综述
前记 在能源领域,由于很多地方都是无人值守,设备故障检测是一个必须面对的问题.笔者通过几个行业案例了解到,由于很多设备发生故障时候会产生特定频谱的声音,所以该行业对振动监测的需求特别强烈,由于涉及到 ...
- kali问题排查
kali从2020的更新到最新版就卡在了启动界面 猜想会不会是内核的问题,选择到这个最新内核就可以正常进入系统了 由于觉得这样启动太过于麻烦,想办法把这个内核作为默认启动内核,从网上了解到要修改/et ...
- 如何使用libavcodec将.yuv图像序列编码为.h264的视频码流?
1.实现打开和关闭输入文件和输出文件的操作 //io_data.cpp static FILE* input_file= nullptr; static FILE* output_file= null ...
- Open LLM 排行榜近况
Open LLM 排行榜是 Hugging Face 设立的一个用于评测开放大语言模型的公开榜单.最近,随着 Falcon 的发布并在 Open LLM 排行榜 上疯狂屠榜,围绕这个榜单在推特上掀起了 ...
- Valine评论插件因为LeanCloud国内域名解析问题无法正常使用的解决方法
近日,LeanCloud 国内域名解析存在问题,Valine评论插件的评论内容都储存在LeanCloud,使用Valine评论插件的个人博客的评论及阅读数会显示失败. 关于 LeanCloud 国内域 ...