万字博文让我们携手一起走进bs4的世界【python Beautifulsoup】bs4入门 find()与find_all()
目录
Beautiful Soup
支持从HTML或XML文件中提取数据的python库
- 支持Python标准库中的HTML解析器
- 还支持一些第三方的解析器lxml, 使用的是 Xpath 语法,推荐安装。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了
下表列出了主要的解析器:
|
解析器 |
使用方法 |
优势 |
劣势 |
|
Python标准库 |
BeautifulSoup(markup, "html.parser") |
Python的内置标准库;执行速度适中;文档容错能力强 |
Python 2.7.3 or 3.2.2前 的版本中文档容错能力差 |
|
lxml HTML 解析器 |
BeautifulSoup(markup, "lxml") |
速度快;文档容错能力强 ; |
需要安装C语言库 |
|
lxml XML 解析器 |
BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") |
速度快;唯一支持XML的解析器 |
需要安装C语言库 |
|
html5lib |
BeautifulSoup(markup, "html5lib") |
最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档 |
速度慢;不依赖外部扩展 |
下表列出了主要的解析器,以及它们的优缺点:
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
格式化输出soup 对象
print(soup.prettify())Beautiful Soup库的引用 Beautiful Soup库,也叫beautifulsoup4 或 bs4
引用方式如下,即主要是用BeautifulSoup 类
import bs4 from bs4
import BeautifulSoupBeautifulSoup类的基本元素
<p class=“title”> … </p>
|
基本元素 |
说明 |
|
Tag |
标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
|
Name |
标签的名字,<p>…</p>的名字是'p',格式:<tag>.name |
|
Attributes |
标签的属性,字典形式组织,格式:<tag>.attrs |
|
NavigableString |
标签内非属性字符串,<>…</>中字符串,格式:<tag>.string |
|
Comment |
标签内字符串的注释部分,一种特殊的Comment类型 |

任何存在于HTML语法中的标签都可以用soup.<tag>访问获得
当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个
它查找的是在所有内容中的第一个符合要求的标签。
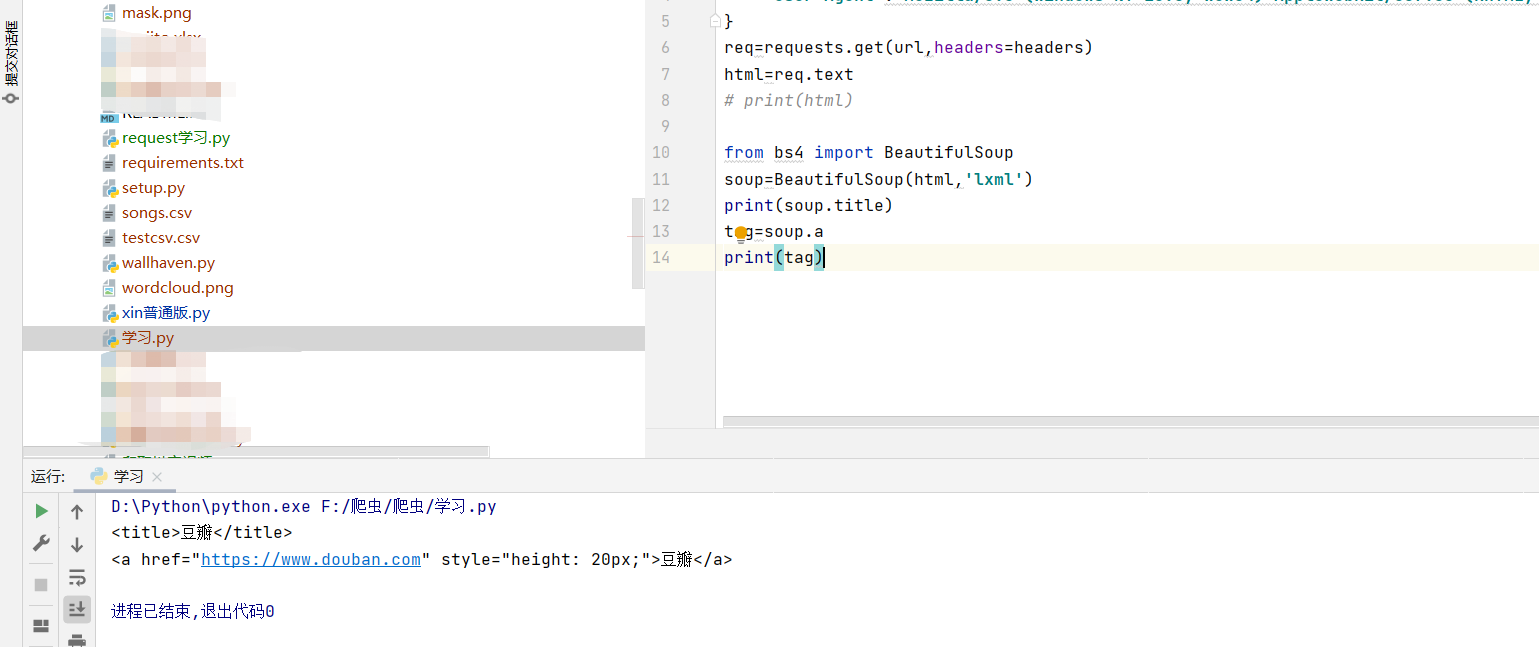
1.Tag的name
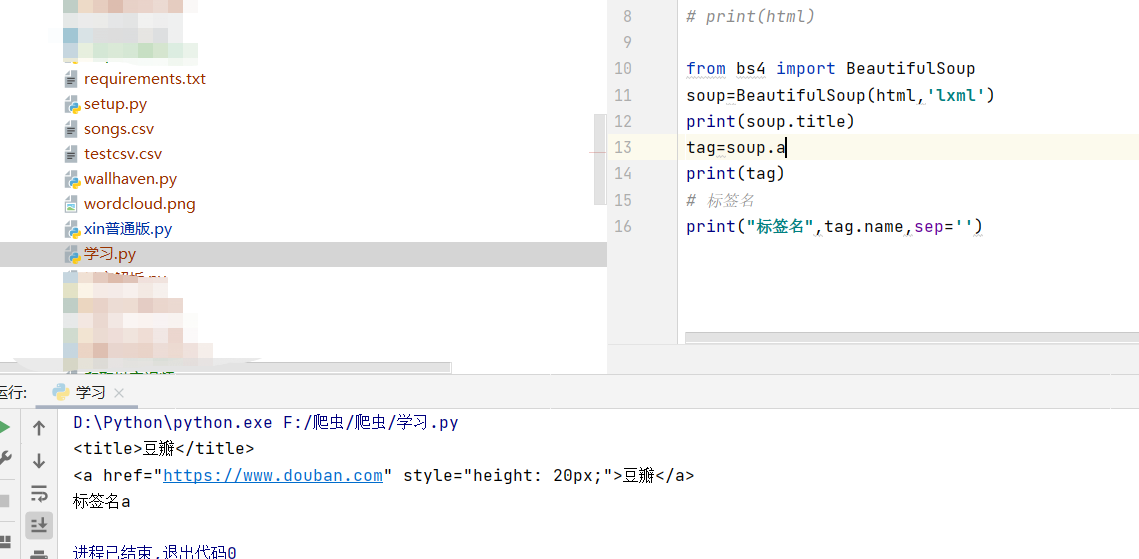
2.Tag的attrs(属性)
|
基本元素 |
说明 |
|
Attributes |
标签的属性,字典形式组织,格式:<tag>.attrs |
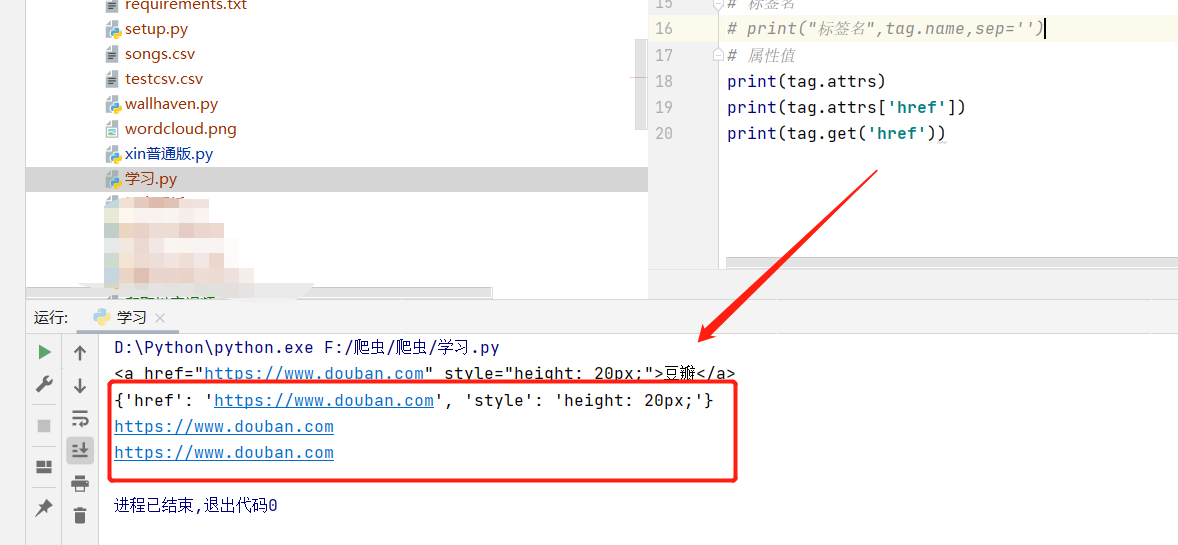
一个<tag>可以有0或多个属性,字典类型
还可以利用get方法,传入属性的名称,二者是等价的
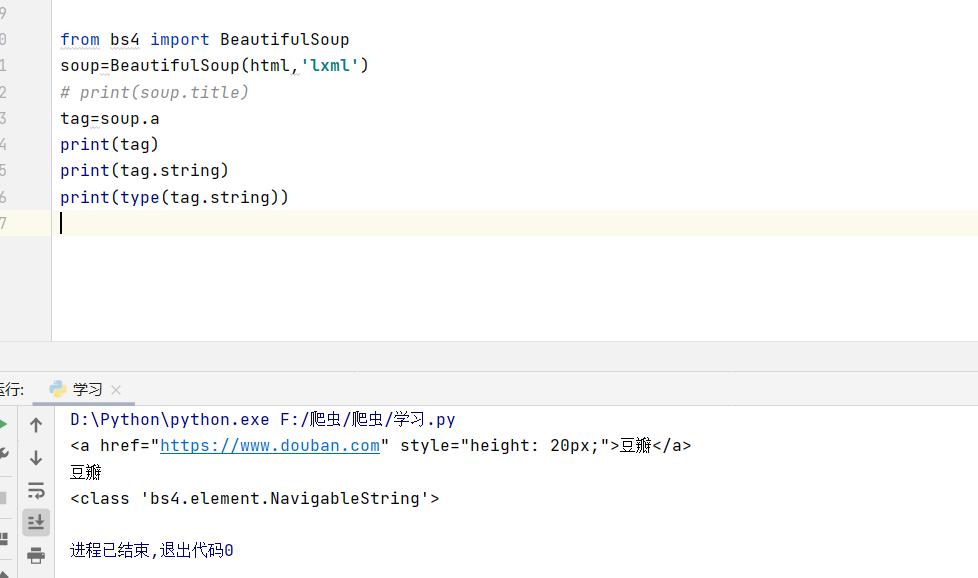
3.Tag的NavigableString
|
基本元素 |
说明 |
|
NavigableString |
标签内非属性字符串,<>…</>中字符串,格式:<tag>.string |

二、遍历文档树
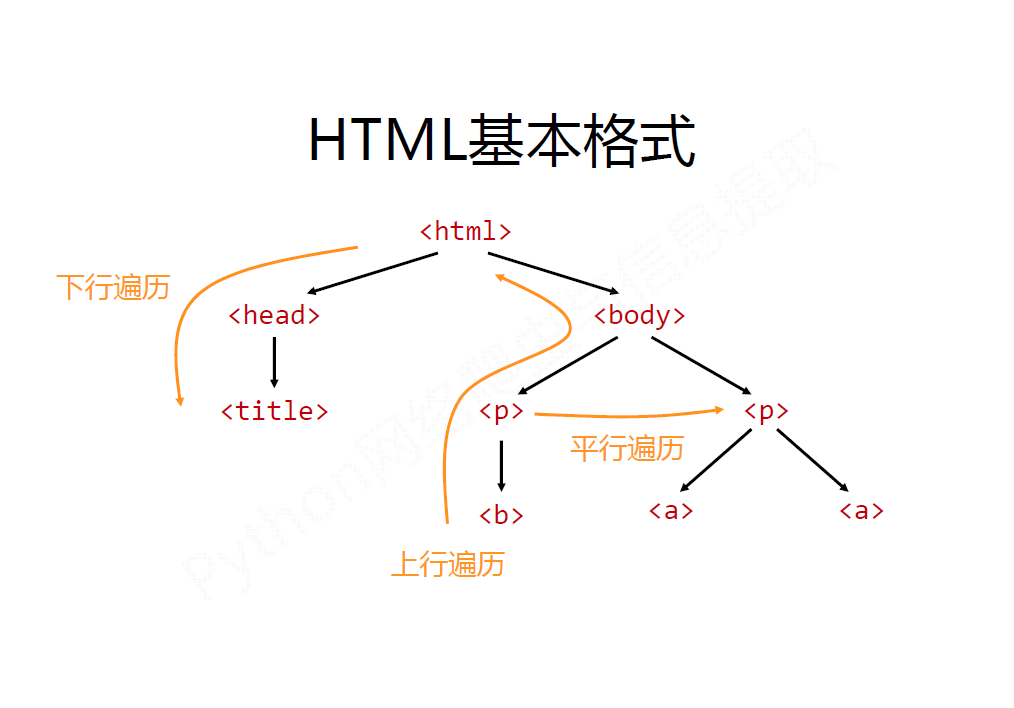
下行遍历
|
属性 |
说明 |
|
.contents |
子节点的列表,将<tag>所有儿子节点存入列表 |
|
.children |
子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
|
.descendants |
子孙节点的迭代类型,包含所有子孙节点,用于循环遍历,一级一级往子节点遍历 |
.contents
.children

标签树的上行遍历
|
属性 |
说明 |
|
.parent |
节点的父亲标签 |
|
.parents |
节点先辈标签的迭代类型,用于循环遍历先辈节点 |
标签树的平行遍历
|
属性 |
说明 |
|
.next_sibling |
返回按照HTML文本顺序的下一个平行节点标签 |
|
.previous_sibling |
返回按照HTML文本顺序的上一个平行节点标签 |
|
.next_siblings |
迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
|
.previous_siblings |
迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
三、bs4库的prettify()方法

四、获取字符串
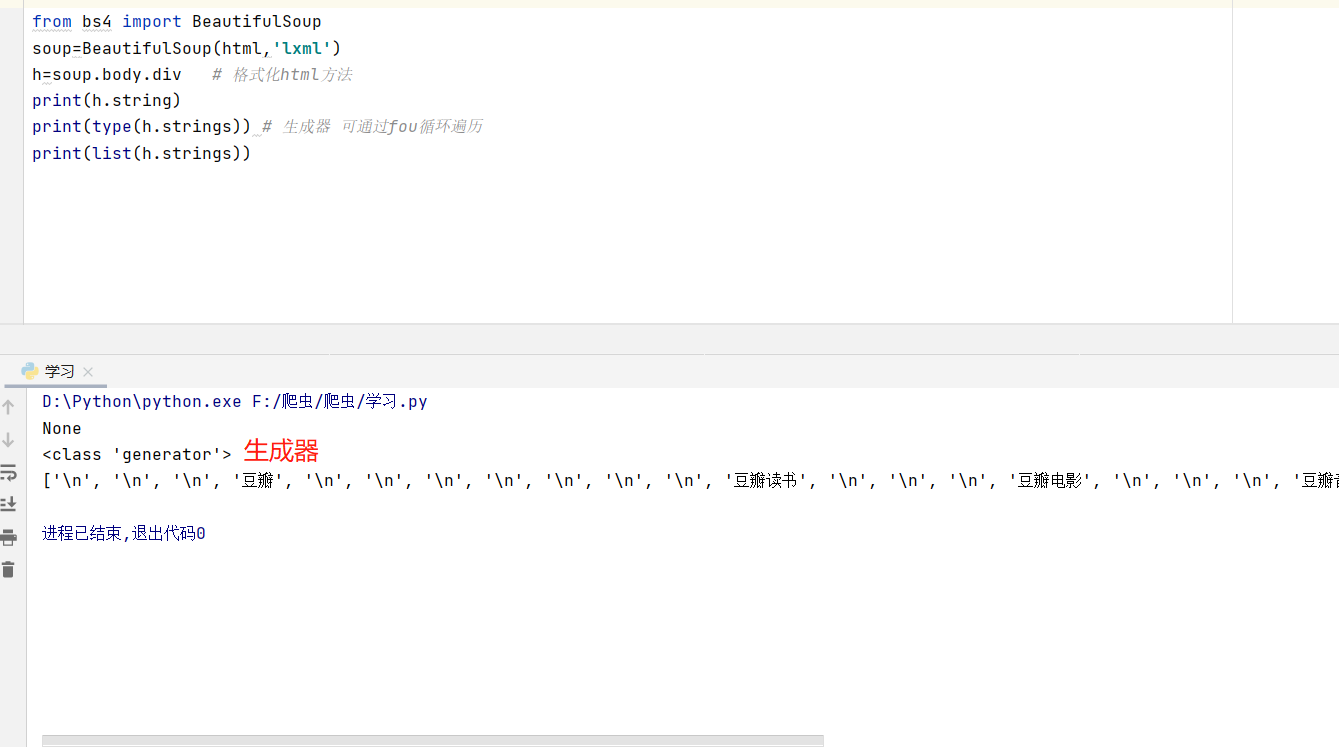
手误 for循环
生成器的学习请参考:生成器
这段代码来获得字符串时,返回的是None,不解,于是去查了BeautifulSoup的官方文档,发现.string方法在tag包含多个子节点时,tag无法确定.string方法应该调用哪个子节点的内容,所以输出None。
那么如何获得包含在tag中的字符串呢?方法如下:
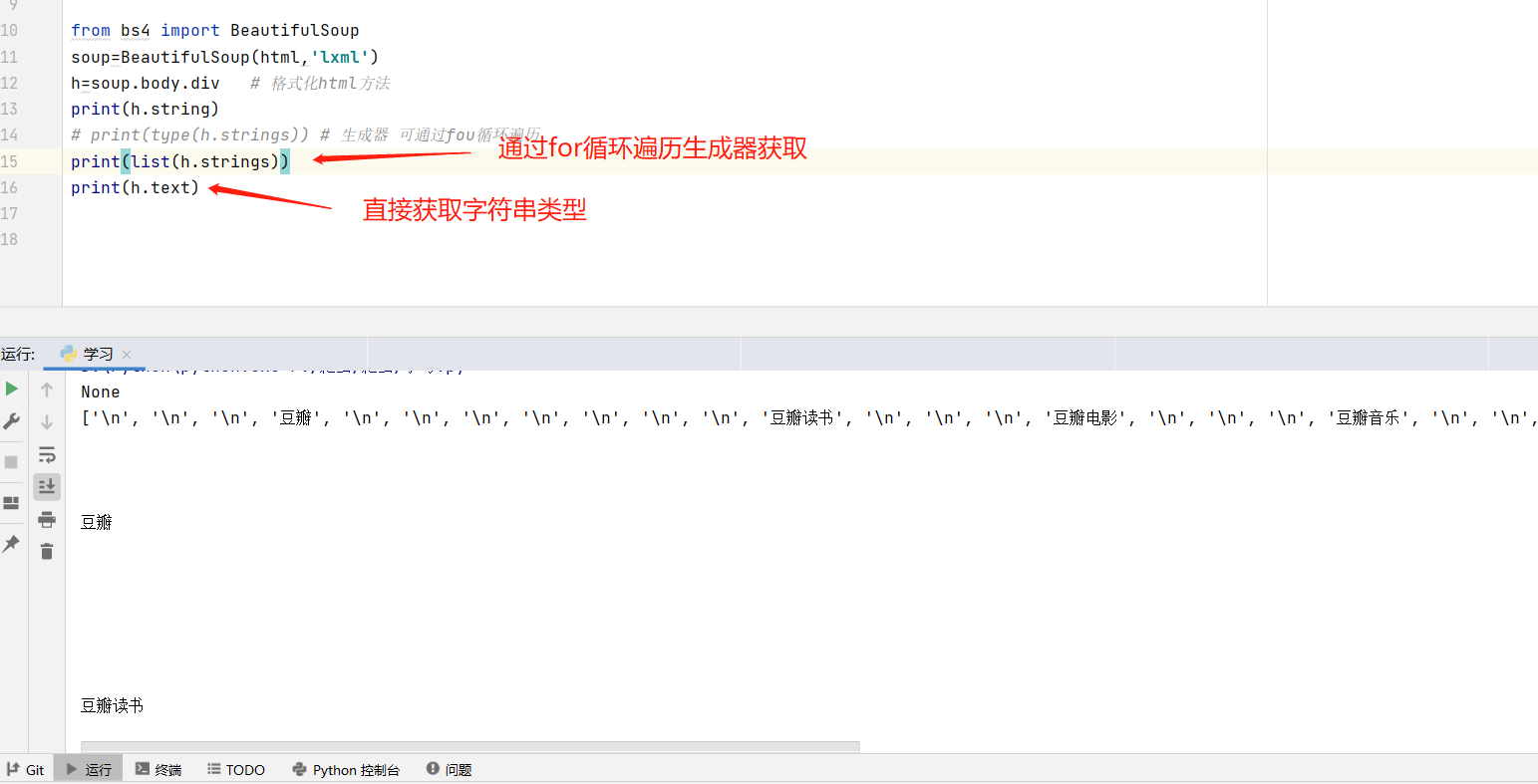
这样就可以得到字符串。不过这其中包含换行符,只需用strip方法处理即可,中间包含空格用换行符代替即可 ——replace()方法
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>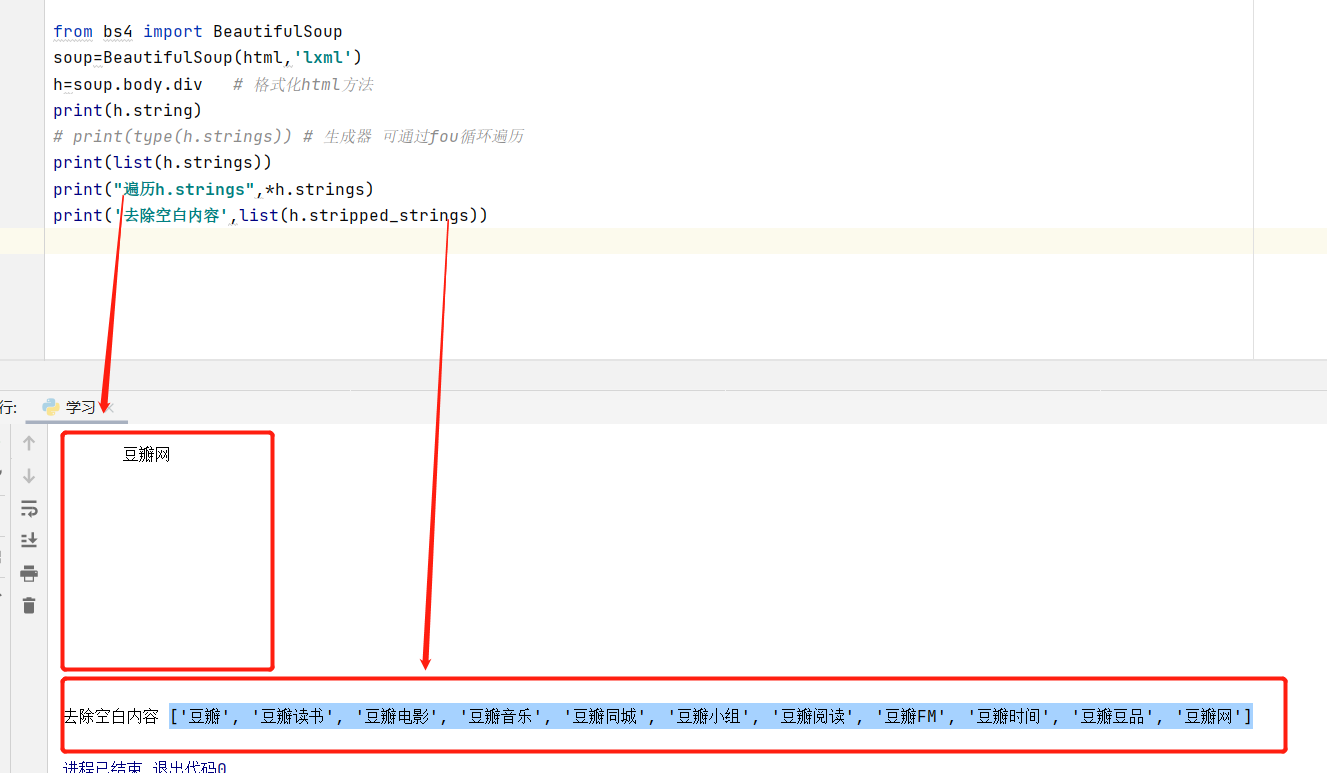
*h.strings 和h.text 实现效果类似
text与get_text()

总结:
.string可以返回当前节点中的内容,但是当前节点包含子节点时,.string不知道要获取哪一个节点中的内容,故返回空
.text(或者.get_text())可以返回当前节点所包含的所有文本内容,包括当前节点的子孙节点
如果tag中包含多个字符串 ,可以使用 .strings 来循环获取:
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容。
|
属性 |
说明 |
|
.string |
可以返回当前节点中的内容,但是当前节点包含子节点时,.string不知道要获取哪一个节点中的内容,故返回空 |
|
.text(或者.get_text()) |
可以返回当前节点所包含的所有文本内容,包括当前节点的子孙节点 |
|
.strings |
如果tag中包含多个字符串 ,可以使用 .strings 来循环获取。 |
|
.stripped_strings |
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容。 |
五、搜索文档树:
1.过滤器
字符串
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的<b>标签:
soup.find_all('b')
# [<b>The Dormouse's story</b>]过滤器包括:字符串、正则表达式、列表、True、方法。
详细请看官网文档: Beautiful Soup 4.2.0 文档 — Beautiful Soup 4.2.0 documentation
2. find和find_all方法:
搜索文档树,一般用得比较多的就是两个方法,一个是find,一个是find_all。find方法是找到第一个满足条件的标签后就立即返回,只返回一个元素。find_all方法是把所有满足条件的标签都选到,然后返回回去。使用这两个方法,最常用的用法是输入name以及attr参数找出符合要求的标签。
attrs 参数定义一个字典参数来搜索包含特殊属性的tag
soup.find_all("a",attrs={"id":"link2"})或者是直接传入属性的的名字作为关键字参数:
soup.find_all("a",id='link2')find_all()
find_all( name , attrs , recursive , text , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子:
# 搜索id为 anony-nav的<div>标签
print(h.find_all('div',id='anony-nav'))
# 搜索内容里面包含“豆瓣”的<a>标签:
print(soup.find_all("a",text=re.compile("豆瓣")))
print(soup.find_all("a",class_=re.compile("lnk-"))) # 搜索class里面包含“link-”的<a>标签:
# 使用多个指定名字的参数可以同时过滤tag的多个属性:
print(soup.find_all(href=re.compile("movie"), class_='lnk-movie'))
运行结果:
[<div id="anony-nav">
<div class="anony-nav-links">
<ul>
<li>
<a class="lnk-book" href="https://book.douban.com" target="_blank">豆瓣读书</a>
</li>
<li>
<a class="lnk-movie" href="https://movie.douban.com" target="_blank">豆瓣电影</a>
</li>
<li>
<a class="lnk-music" href="https://music.douban.com" target="_blank">豆瓣音乐</a>
</li>
<li>
<a class="lnk-events" href="https://www.douban.com/location/" target="_blank">豆瓣同城</a>
</li>
<li>
<a class="lnk-group" href="https://www.douban.com/group/" target="_blank">豆瓣小组</a>
</li>
<li>
<a class="lnk-read" href="https://read.douban.com" target="_blank">豆瓣阅读</a>
</li>
<li>
<a class="lnk-fm" href="https://douban.fm" target="_blank">豆瓣FM</a>
</li>
<li>
<a class="lnk-shijian" href="https://time.douban.com/?dt_time_source=douban-web_anonymous_index_top_nav" target="_blank">豆瓣时间</a>
</li>
<li>
<a class="lnk-market" href="https://market.douban.com?utm_campaign=anonymous_top_nav&utm_source=douban&utm_medium=pc_web" target="_blank">豆瓣豆品</a>
</li>
</ul>
</div>
<div class="site-name" style="display: inline-block; line-height: 24px; height: 24px; margin-top: 4px;margin-right: 24px;width: 73px;background-image: url(https://img3.doubanio.com/f/sns/714b8751a533ef592bea5cd4603dbb9e713ded61/pics/sns/sitename.png);background-size: contain; background-repeat: no-repeat;text-indent: -999em;" title="豆瓣网">
豆瓣网
</div>
<div class="anony-srh">
<form action="https://www.douban.com/search" method="get">
<span class="inp"><input autocomplete="off" maxlength="60" name="q" placeholder="书籍、电影、音乐、小组、小站、成员" size="12" type="text"/></span>
<span class="bn"><input type="submit" value="搜索"/></span>
</form>
</div>
</div>]
[<a href="https://www.douban.com" style="height: 20px;">豆瓣</a>, <a class="lnk-book" href="https://book.douban.com" target="_blank">豆瓣读书</a>, <a class="lnk-movie" href="https://movie.douban.com" target="_blank">豆瓣电影</a>, <a class="lnk-music" href="https://music.douban.com" target="_blank">豆瓣音乐</a>, <a class="lnk-events" href="https://www.douban.com/location/" target="_blank">豆瓣同城</a>, <a class="lnk-group" href="https://www.douban.com/group/" target="_blank">豆瓣小组</a>, <a class="lnk-read" href="https://read.douban.com" target="_blank">豆瓣阅读</a>, <a class="lnk-fm" href="https://douban.fm" target="_blank">豆瓣FM</a>, <a class="lnk-shijian" href="https://time.douban.com/?dt_time_source=douban-web_anonymous_index_top_nav" target="_blank">豆瓣时间</a>, <a class="lnk-market" href="https://market.douban.com?utm_campaign=anonymous_top_nav&utm_source=douban&utm_medium=pc_web" target="_blank">豆瓣豆品</a>, <a class="lnk-app" href="https://www.douban.com/doubanapp/app?channel=nimingye">下载豆瓣 App</a>, <a href="https://time.douban.com?dt_time_source=douban-web_anonymous">豆瓣时间</a>, <a href="https://read.douban.com/app/">豆瓣阅读</a>, <a href="https://www.douban.com/wetware/">潮潮豆瓣音乐周</a>, <a href="https://douban.fm/?from_=music_nav">豆瓣FM</a>, <a href="https://douban.fm/app?from_=shire_anonymous_home">豆瓣FM</a>, <a href="https://artist.douban.com/app">豆瓣音乐人</a>, <a href="https://www.douban.com/gallery/topic/761/?index=2&r=topic?dcm=douban&dcs=anonymous-home-topic" target="_blank">
我的豆瓣收藏夹里有什么
</a>, <a href="https://www.douban.com/group/topic/225403601?dcm=douban&dcs=anonymous-home-group" target="_blank">
【申请已结束】一日三餐,一起吃饭:邀请各位爱晒猫的铲屎官免费试用新品「豆瓣猫咪餐具」
</a>, <a href="https://www.douban.com/group/topic/203421229?dcm=douban&dcs=anonymous-home-group" target="_blank">
请开麦|我们很想听听你的心声,期待豆瓣豆品出什么样的产品?
</a>, <a href="https://www.douban.com/group/topic/204293834?dcm=douban&dcs=anonymous-home-group" target="_blank">
会员中心上线了「豆瓣遇见你便利贴」,100积分即可兑换
</a>, <a class="market-spu-title" href="https://market.douban.com/campaign/weeklycalendar2022?dcm=douban&dcs=anonymous-home-spu" target="_blank">
豆瓣读书周历2022
</a>, <a class="market-spu-title" href="https://market.douban.com/campaign/bookfragrance?dcm=douban&dcs=anonymous-home-spu" target="_blank">
国家图书馆 x 豆瓣 读书香薰
</a>, <a class="market-spu-title" href="https://market.douban.com/campaign/calendar2022?dcm=douban&dcs=anonymous-home-spu" target="_blank">
豆瓣电影日历2022
</a>, <a href="https://www.douban.com/about">关于豆瓣</a>, <a href="https://www.douban.com/jobs">在豆瓣工作</a>, <a href="https://www.douban.com/partner/">豆瓣广告</a>]
[<a class="lnk-book" href="https://book.douban.com" target="_blank">豆瓣读书</a>, <a class="lnk-movie" href="https://movie.douban.com" target="_blank">豆瓣电影</a>, <a class="lnk-music" href="https://music.douban.com" target="_blank">豆瓣音乐</a>, <a class="lnk-events" href="https://www.douban.com/location/" target="_blank">豆瓣同城</a>, <a class="lnk-group" href="https://www.douban.com/group/" target="_blank">豆瓣小组</a>, <a class="lnk-read" href="https://read.douban.com" target="_blank">豆瓣阅读</a>, <a class="lnk-fm" href="https://douban.fm" target="_blank">豆瓣FM</a>, <a class="lnk-shijian" href="https://time.douban.com/?dt_time_source=douban-web_anonymous_index_top_nav" target="_blank">豆瓣时间</a>, <a class="lnk-market" href="https://market.douban.com?utm_campaign=anonymous_top_nav&utm_source=douban&utm_medium=pc_web" target="_blank">豆瓣豆品</a>, <a class="lnk-app" href="https://www.douban.com/doubanapp/app?channel=nimingye">下载豆瓣 App</a>, <a class="lnk-qr" href="javascript: void 0;" id="expand-qr"><img height="28" src="https://img3.doubanio.com/f/sns/0c708de69ce692883c1310053c5748c538938cb0/pics/sns/anony_home/icon_qrcode_green.png" width="28"/></a>, <a class="lnk-buy" href="https://book.douban.com/cart">
<em>购书单</em>
</a>, <a class="lnk-icon" href="https://read.douban.com/app/">
<i class="app-icon app-icon-read"></i>
</a>, <a class="lnk-icon" href="https://douban.fm/app?from_=shire_anonymous_home">
<i class="app-icon app-icon-fm"></i>
</a>, <a class="lnk-icon" href="https://artist.douban.com/app">
<i class="app-icon app-icon-artists"></i>
</a>]
[<a class="lnk-movie" href="https://movie.douban.com" target="_blank">豆瓣电影</a>]经过上例可知,find_all返回的数据类型为列表
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用 class 做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag:
limit 参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果.
文档树中有3个tag符合搜索条件,但结果只返回了2个,因为我们限制了返回数量:
print(soup.find_all("a",class_=re.compile("lnk-"),limit=2))
运行结果:
[<a class="lnk-book" href="https://book.douban.com" target="_blank">豆瓣读书</a>, <a class="lnk-movie" href="https://movie.douban.com" target="_blank">豆瓣电影</a>]代码等价
soup.find_all("a")
soup("a")
find()
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
# Nonesoup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>3.CSS选择器
CSS Selector
CSS(即层叠样式表Cascading Stylesheet),
Selector来定位(locate)页面上的元素(Elements)。Selenium官网的Document里极力推荐使用CSS locator,而不是XPath来定位元素,原因是CSS locator比XPath locator速度快.
在写 CSS 时:
- 标签名不加任何修饰
- 类名前加点
- id名前加 #
在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数,即可使用CSS选择器的语法找到tag
利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
通过标签名查找
print (soup.select('title') )
#[<title>The Dormouse's story</title>]
print (soup.select('a'))
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print (soup.select('b'))
#[<b>The Dormouse's story</b>]通过类名查找
print (soup.select('.sister'))
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]通过 id 名查找
print(soup.select('#link1')) # [<a class="sister" href="http://example.com/elsie" id="link1"></a>]通过tag标签逐层查找:
每个空格结合符可以解释为“...在...中找到”、“...作为...的一部分”、“...作为...的后代”,但是要求必须从右向左读选择器——《CSS权威指南》第三版
1 div.contain .blue{color:blue;}
2 div.contain.blue{color:blue;}
以上两种规则分别应用的元素如下:
1 <div class="contain">contain<span class="blue">blue</span><!--后代-->
2 <div class="contain blue">contain and blue</div><!--多类-->
print (soup.select("body > div > div > h1"))
print (soup.select("body h1")) # 不同结点 逐层查找
运行结果: [<h1 id="douban-logo" style="height: 20px;width: 102px;margin: 7px 13px;background-size: contain;"> <a href="https://www.douban.com" style="height: 20px;">豆瓣</a> </h1>] [<h1 id="douban-logo" style="height: 20px;width: 102px;margin: 7px 13px;background-size: contain;"> <a href="https://www.douban.com" style="height: 20px;">豆瓣</a> </h1>]直接子标签查找
print (soup.select("head > title"))
#[<title>The Dormouse's story</title>]组合查找
组合查找即标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,
属性和标签不属于同一节点 二者需要用空格分开
print(soup.select('p #link1'))
# [<a class="sister" href="http://example.com/elsie" id="link1"></a>]属性查找
查找时还可以加入属性元素,属性需要用中括号括起来
注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到
print (soup.select('a[class="sister"]'))
# [<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print(soup.select('a[href="http://example.com/elsie"]'))
# [<a class="sister" href="http://example.com/elsie" id="link1"></a>]同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print (soup.select('p a[href="http://example.com/elsie"]'))
# [<a class="sister" href="http://example.com/elsie" id="link1"></a>]以上的 select 方法返回的结果都是列表形式,可以遍历形式输出
用 get_text() 方法来获取它的内容。
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print (title.get_text())六、编码自动检测
可以在Beautiful Soup以外使用,检测某段未知编码时,可以使用这个方法:
from bs4 import UnicodeDammit
dammit = UnicodeDammit("Sacr\xc3\xa9 bleu!")
print(dammit.unicode_markup)
# Sacré bleu! dammit.original_encoding最后,文中有不对错误的地方,欢迎各位大神前辈指教!
万字博文让我们携手一起走进bs4的世界【python Beautifulsoup】bs4入门 find()与find_all()的更多相关文章
- 走进JavaWeb技术世界14:Mybatis入门
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- 走进JavaWeb技术世界13:Hibernate入门经典与注解式开发
原文地址:Hibernate入门这一篇就够了 前言 本博文主要讲解介绍Hibernate框架,ORM的概念和Hibernate入门,相信你们看了就会使用Hibernate了! 什么是Hibernate ...
- Python:bs4的使用
概述 bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签. 一.初始化 from bs4 import BeautifulSoup soup ...
- Python:bs4中 string 属性和 text 属性的区别及背后的原理
刚开始接触 bs4 的时候,我也很迷茫,觉得 string 属性和 text 属性是一样的,不明白为什么要分成两个属性. html = '<p>hello world</p>' ...
- 【SpringMVC学习02】走进SpringMVC的世界
上一篇博文主要介绍了springmvc的整个架构执行流程,对springmvc有了宏观上的把握,这一篇博文主要以案例作为驱动,带你走进springmvc的世界.案例中的需求很简单:对商品列表的查询.表 ...
- 【MyBatis学习02】走进MyBatis的世界
mybatis是个持久层的框架,用来执行数据库操作的,无外乎增删改查,上一节对mybatis有了宏观上的了解后,这一篇博客主要通过一个小示例来入门mybatis,先看一下要写的示例需求: 根据用户id ...
- 走进JavaWeb技术世界1:JavaWeb的由来和基础知识
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- 走进JavaWeb技术世界7:Tomcat和其他WEB容器的区别
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- [C#] 走进 LINQ 的世界
走进 LINQ 的世界 序 在此之前曾发表过三篇关于 LINQ 的随笔: 进阶:<LINQ 标准查询操作概述>(强烈推荐) 技巧:<Linq To Objects - 如何操作字符串 ...
- 走进缓存的世界(三) - Memcache
系列文章 走进缓存的世界(一) - 开篇 走进缓存的世界(二) - 缓存设计 走进缓存的世界(三) - Memcache 简介 Memcache是一个高性能的分布式内存对象缓存系统,用于动态Web应用 ...
随机推荐
- 【JS 逆向百例】猿人学系列 web 比赛第二题:js 混淆 - 动态 cookie,详细剖析
逆向目标 猿人学 - 反混淆刷题平台 Web 第二题:js 混淆,动态 cookie 目标:提取全部 5 页发布日热度的值,计算所有值的加和 主页:https://match.yuanrenxue.c ...
- 用户 'NT Service\SSISScaleOutMaster140' 登录失败
用户 'NT Service\SSISScaleOutMaster140' 登录失败. 原因: 找不到与提供的名称匹配的登录名. 项目情况: 用户 'NT Service\SSISScaleOutMa ...
- uni-app 实现下拉刷新功能
我们在运用uni-app开发小程序或h5时,常常需要页面实现下拉刷新功能. 在 js 中定义 onPullDownRefresh 处理函数(和onLoad等生命周期函数同级),监听该页面用户下拉刷新事 ...
- 设计模式-2 简单工厂模式Factory Method
设计模式-2 简单工厂模式 1 意图: 定义一个用户创建对象的接口,让子类决定实例化那个类.Factory Method使一个类的实例化延迟到其子类 使用场景:将一个类的实例化延迟到其子类结构: 优缺 ...
- Window Server+IIS配置实现一台服务器绑定多个HTTPS证书
参考原文链接:https://blog.csdn.net/lengyiqiu/article/details/89182239 此处做个记录防止丢失: 直接上步骤: 1.选安装好SSL证书,供下面配置 ...
- [SpringBoot][Maven]关于maven pom文件的packaging属性
关于maven pom文件的packaging属性 前几天在调试源码运行程序的时候,因为将项目中pom文件的packaging属性用错导致源码包无法引入使用而报Bean注入错误,在此进行总结整理记录. ...
- JS leetcode 至少是其他数字的两倍的最大数 解答思路分析
壹 ❀ 引 刷leetcode的第二天,那么今天做的也是一道难度为简单的题目至少是其他数字的两倍的最大数,老规矩,先说说我的实现思路后,再来分析优质答案,原题如下: 在一个给定的数组nums中,总是存 ...
- android mvvm实例解析
MVVM架构,将整个应用分为三层,View层,VM层,Model层.其中View层单向引用VM层,VM层单向引用Model层.如上图. 单向引用,而非双向引用,这是MVVM与MVP最大的区别.View ...
- MySQL基础之DDL语句
讲解SQL语句三大分类和每个分类的SQL使用入门. 使用的是数据库是:MySQL 8.0.27 1.SQL分类 DDL(Data Definition Language)语句:数据定义语句. 用途 ...
- 深入 Nginx 之架构篇[转]
前言 最近在读 Nginx 相关的书籍,做一下读书笔记. Nginx 作为业界知名的高性能服务器,被广泛的应用.它的高性能正是由于其优秀的架构设计,其架构主要包括这几点:模块化设计.事件驱动架构.请求 ...