ArcGIS如何自动获得随机采样点?
本文介绍基于ArcMap软件,实现在指定区域自动生成随机点的方法。
在GIS应用中,我们时常需要在研究区域内进行地理数据的随机采样;而采样点的位置往往需要在结合实际情况的前提下,用计算机随机生成。这一操作在ArcMap软件中就可以非常方便地进行。
已知现有如下一景栅格图像,我们需要在这一图像对应的位置中,随机生成若干点作为采样点。

另一方面,我们还已知该栅格图像对应的空间范围的面要素矢量图层,如下图所示。其中,由于该栅格图像存在无效值NoData,因此可以看到栅格图像是没有完全遮盖矢量图层的。

接下来,就可以开始随机点的选取。在软件中依次选择“Data Management Tools.tbx”→“Sampling”→“Creat Random Points”。

弹出如下所示的界面。

这个工具的参数有很多,我们逐一介绍。“Output Location”为生成点要素的保存路径,“Output Point Feature Class”为生成点要素的名称;“Constraining Feature Class (optional)”为我们生成随机点的范围——这一项为可选项,如果我们选择了这一项,那么随机点就会在这一项所选的点、线或面矢量要素范围内生成;如果我们不选择这一项,就可以在下一项“Constraining Extent (optional)”中选择我们的栅格图像作为范围。“Number of Points [value or field] (optional)”为生成点的个数,如果我们选中“Long”,那么就直接输入整数即可;如果我们选中“Field”,那么就依据“Constraining Feature Class (optional)”这一项所选的点、线或面矢量要素的属性表中某一个字段作为点的个数;这里还需要注意,如果我们在“Constraining Feature Class (optional)”这一项选中了包含多个要素的要素集,那么“Long”所输入的点的个数其实是该要素集下属每1个要素中所生成的点的个数(这里大家看不明白也没关系,我们在后面会用一些例子来说明)。“Minimum Allowed Distance [value or field] (optional)”表示所生成点之间的最小距离,同样是可以用直接输入距离或者用矢量要素的属性表字段来赋值。最后一个勾选项表示是否将输出的随机点结果作为一个整体的要素——如果不勾选此项,那么输出的随机点要素集中,每1个点就相当于是1个要素;如果勾选此项,那么输出的随机点要素集中,所有点整体相当于是1个要素;如果勾选了这一项,就将激活最后一个输入框,表示如果将多个点整体当作1个要素的话,该要素最多可以含有多少个点。
接下来,我们就通过几个实例来探究一下上述参数的具体含义。
首先,第一个例子,我们就按照上图所示的参数设定运行该工具,得到结果如下所示。

可以看到,我们虽然在“Long”中设定了点的个数是100,但是实际生成的随机点个数远远不止100个;这是因为,前面我们也提到:如果在“Constraining Feature Class (optional)”这一项选中了包含多个要素的要素集,那么“Long”所输入的点的个数其实是该要素集下属每1个要素中所生成的点的个数。
在刚刚的例子中,我们“Constraining Feature Class (optional)”这一项选所用的面矢量要素图层如下所示,可以看到其是一个包含有9个省(9个要素)的要素集;那么结合我们前面介绍的,在“Long”中设定了点的个数是100,实际上是在每1个省份(每1个要素)中生成100个点,因此最终得到的整体结果是900个点,从而导致我们的随机点结果看起来就这么密集。
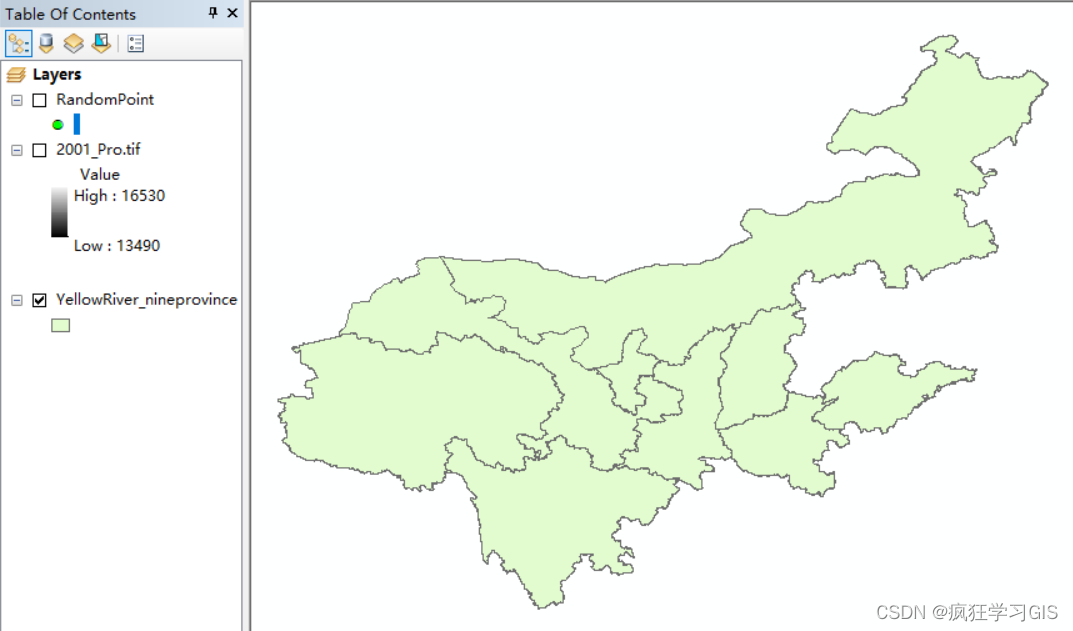
我们将这个9个省的面矢量要素图层和刚刚生成的随机点矢量要素放在一起看,大家就看得更清楚了——每个省都是100个点,但由于内蒙古地区面积大,因此这里100个点就看起来比较疏松;而宁夏(下图中红色区域)由于面积小,所以100个点在这里就显得尤为密集。

接下来,第二个例子,我们按照下图所示的参数设定运行该工具。

其中,我们选择用矢量图层的属性表字段来作为约束每1个行政区(每1个要素集)中生成随机点的个数。这里我们就选择用下图所示的这个字段作为输入字段。

得到的结果如下所示。可以看到,内蒙古的该字段数值为15,其所生成的点就是15个;而宁夏该字段的数值为64,因此其所生成的点看起来依然是密密麻麻的。

清楚了以上规则,就可以更好地进行随机点自动生成的操作了。
ArcGIS如何自动获得随机采样点?的更多相关文章
- Python中的随机采样和概率分布(二)
在上一篇博文<Python中的随机采样和概率分布(一)>(链接:https://www.cnblogs.com/orion-orion/p/15647408.html)中,我们介绍了Pyt ...
- 关于乱序(shuffle)与随机采样(sample)的一点探究
最近一个月的时间,基本上都在加班加点的写业务,在写代码的时候,也遇到了一个有趣的问题,值得记录一下. 简单来说,需求是从一个字典(python dict)中随机选出K个满足条件的key.代码如下(py ...
- 随机采样和随机模拟:吉布斯采样Gibbs Sampling实现高斯分布参数推断
http://blog.csdn.net/pipisorry/article/details/51539739 吉布斯采样的实现问题 本文主要说明如何通过吉布斯采样来采样截断多维高斯分布的参数(已知一 ...
- 随机采样和随机模拟:吉布斯采样Gibbs Sampling实现文档分类
http://blog.csdn.net/pipisorry/article/details/51525308 吉布斯采样的实现问题 本文主要说明如何通过吉布斯采样进行文档分类(聚类),当然更复杂的实 ...
- Pandas排列和随机采样
随机重排序 import pandas as pd import numpy as np from pandas import Series df = pd.DataFrame(np.arange(5 ...
- hive随机采样
hive> select * from account limit 10;OKaccount.accountname account.accid account.platid ac ...
- 使用 numpy.random.choice随机采样
使用 numpy.random.choice随机采样: 说明: numpy.random.choice(a, size=None, replace=True, p=None) 示例: >> ...
- 利用shuf对数据记录进行随机采样
最近在用SVM为分类器做实验,但是发现数据量太大(2000k条记录)但是训练时间过长...让我足足等了1天的啊!有人指导说可以先进行一下随机采样,再训练,这样对训练结果不会有太大影响(这个待考证).所 ...
- Pandas随机采样
实现对DataFrame对象随机采样 pandas是基于numpy建立起来的,所以numpy大部分函数可作用于DataFrame和Series数据结构. numpy.random.permutatio ...
- 《动手学深度学习》系列笔记 —— 语言模型(n元语法、随机采样、连续采样)
目录 1. 语言模型 2. n元语法 3. 语言模型数据集 4. 时序数据的采样 4.1 随机采样 4.2 相邻采样 一段自然语言文本可以看作是一个离散时间序列,给定一个长度为\(T\)的词的序列\( ...
随机推荐
- MySQL学习(七)varchar和char区别
varchar:用于存储可变长字符串,是最常见的字符串数据类型.比定长类型更节省空间,因为它仅使用必要的空间.varchar需要使用1或2个额外字节记录字符串的长度:如果列的最大长度小于或等于255字 ...
- Linux 硬盘存储和文件系统介绍
一:硬盘存储 1.存储类型 根据存储的可以将存储分为内存和外存两类. 内存:又叫做主存储器,计算机中所有程序的运行都是在内存中进行. 外存:又叫做辅助存储器,因为内存容量小且断电会丢失所有数据.所以磁 ...
- 【转载】vue3 中如何像 vue2 的 extend 一样挂载未挂载的组件,拿到标签本身($el)
原文地址:https://blog.csdn.net/qq_39953537/article/details/110437554 vue3 中如何像 vue2 的 extend 一样挂载未挂载的组件, ...
- 动手造轮子自己实现人工智能神经网络(ANN),解决鸢尾花分类问题Golang1.18实现
人工智能神经网络( Artificial Neural Network,又称为ANN)是一种由人工神经元组成的网络结构,神经网络结构是所有机器学习的基本结构,换句话说,无论是深度学习还是强化学习都是基 ...
- FreeSWITCH的originate命令解析及示例
FreeSWITCH版本:1.10.9 操作系统:CentOS 7.6.1810 originate经常用于发起呼叫,在实际工作过程中用到的也比较多,今天总结下基本用法,也方便我以后查阅. 一.wik ...
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- 方差分析2——双因素方差分析(R语言)
双因素方差分析(Double factor variance analysis) 有两种类型:一个是无交互作用的双因素方差分析,它假定因素A和因素B的效应之间是相互独立的,不存在相互关系:另一个是有交 ...
- 痞子衡嵌入式:利用i.MXRT1xxx系列ROM集成的DCD功能可轻松配置指定外设
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是利用i.MXRT1xxx系列ROM集成的DCD功能可轻松配置指定外设. 关于 i.MXRT1xxx 系列芯片 BootROM 中集成的 ...
- [数据库]Oracle数据迁移至HIVE(待续)
step1 导出csv数据,并 call sql_to_csv('select * from BE_JJZKJCQKTJ', 'OUT_PATH', 'DA.BE_JJZKJCQKTJ.csv'); ...
- SpringBoot2:@Configuration 注解
@Configuration 这个注解的作用,告诉 springboot 这是一个配置类.配置类以及类里的方法都可以作为Bean.里面的方法用@Bean标记. @Configuration 替换了繁琐 ...